Policy-as-Code : La Révolution de la Gouvernance Holistique en DevOps
Tu as sûrement remarqué à quel point nos infrastructures sont devenues complexes. Entre les microservices, les clusters Kubernetes multi-cloud et les déploiements continus, les méthodes manuelles de validation de la conformité sont tout simplement devenues des goulets d'étranglement. Tenter de vérifier manuellement chaque déploiement est non seulement inefficace, mais surtout, incroyablement risqué.
C'est précisément dans ce chaos organisé que le concept de Policy-as-Code (PaC) est passé de "nice-to-have" à un pilier fondamental de toute stratégie DevOps et Cloud Native mature. Il ne s'agit plus de courir après les problèmes, mais de les empêcher de naître, directement à la source.
L'idée fondamentale est de traiter les règles de gouvernance, de sécurité et de conformité de la même manière que nous traitons notre code applicatif : en les écrivant dans un langage déclaratif, en les stockant dans Git, en les testant et en les déployant de manière automatisée. Cela transforme la gouvernance d'une tâche réactive et manuelle à un processus proactif et intégré.
Démystifier le concept : de la règle métier au code
Le terme peut sembler intimidant, mais la logique derrière est d'une clarté redoutable. Il s'agit de traduire des règles humaines, souvent écrites dans des documents Word ou des wikis, en un format que les machines peuvent comprendre et appliquer sans aucune intervention humaine.
Qu'entend-on par "Politique" ?
Une politique, dans notre univers technique, est une règle qui définit ce qui est autorisé et ce qui ne l'est pas au sein de ton système. Ces règles peuvent couvrir un spectre extrêmement large, allant de la simple convention de nommage à des contraintes de sécurité critiques pour ton entreprise.
Concrètement, une politique pourrait stipuler que :
- Tous les buckets S3 doivent avoir le chiffrement activé.
- Chaque ressource déployée sur le cloud doit posséder un tag "owner" et "project".
- Aucun conteneur ne peut s'exécuter avec des privilèges "root".
- Seules les images Docker provenant de notre registre privé sont autorisées dans le cluster de production.
Chacune de ces phrases représente un garde-fou essentiel pour la stabilité, la sécurité ou la gestion des coûts de ton infrastructure. Le Policy-as-Code nous donne les moyens d'automatiser leur vérification.
Open Policy Agent (OPA) : Le standard de facto
Pour traduire ces règles en code, il nous faut un outil et un langage. C'est là qu'intervient Open Policy Agent (OPA), un projet incubé par la CNCF (Cloud Native Computing Foundation) qui est rapidement devenu le standard du marché. OPA utilise un langage déclaratif nommé Rego, spécialement conçu pour interroger des structures de données complexes comme des fichiers JSON ou YAML.
Imagine que tu veuilles t'assurer qu'aucun service Kubernetes de type LoadBalancer n'est exposé publiquement. En Rego, la règle pourrait ressembler à ceci, une syntaxe qui, une fois maîtrisée, devient un puissant outil de gouvernance.
package kubernetes.services
# Deny if a service of type LoadBalancer is found
deny[msg] {
input.request.kind.kind == "Service"
input.request.object.spec.type == "LoadBalancer"
msg := "Exposing services via LoadBalancer is not allowed."
}Ce petit bout de code, une fois intégré dans tes processus, peut empêcher une erreur de configuration potentiellement catastrophique avant même qu'elle n'atteigne l'environnement de production.
Une Gouvernance Intégrée à chaque étape du cycle de vie
La véritable puissance du Policy-as-Code réside dans sa capacité à s'intégrer de manière transparente tout au long de la chaîne de livraison logicielle. Il ne s'agit pas d'un simple audit post-mortem, mais d'une série de points de contrôle qui garantissent la conformité à chaque étape.
Ce flux continu de validation est ce qui constitue une gouvernance holistique : une approche complète qui couvre le cycle de vie de l'artefact, depuis le poste du développeur jusqu'au runtime en production.
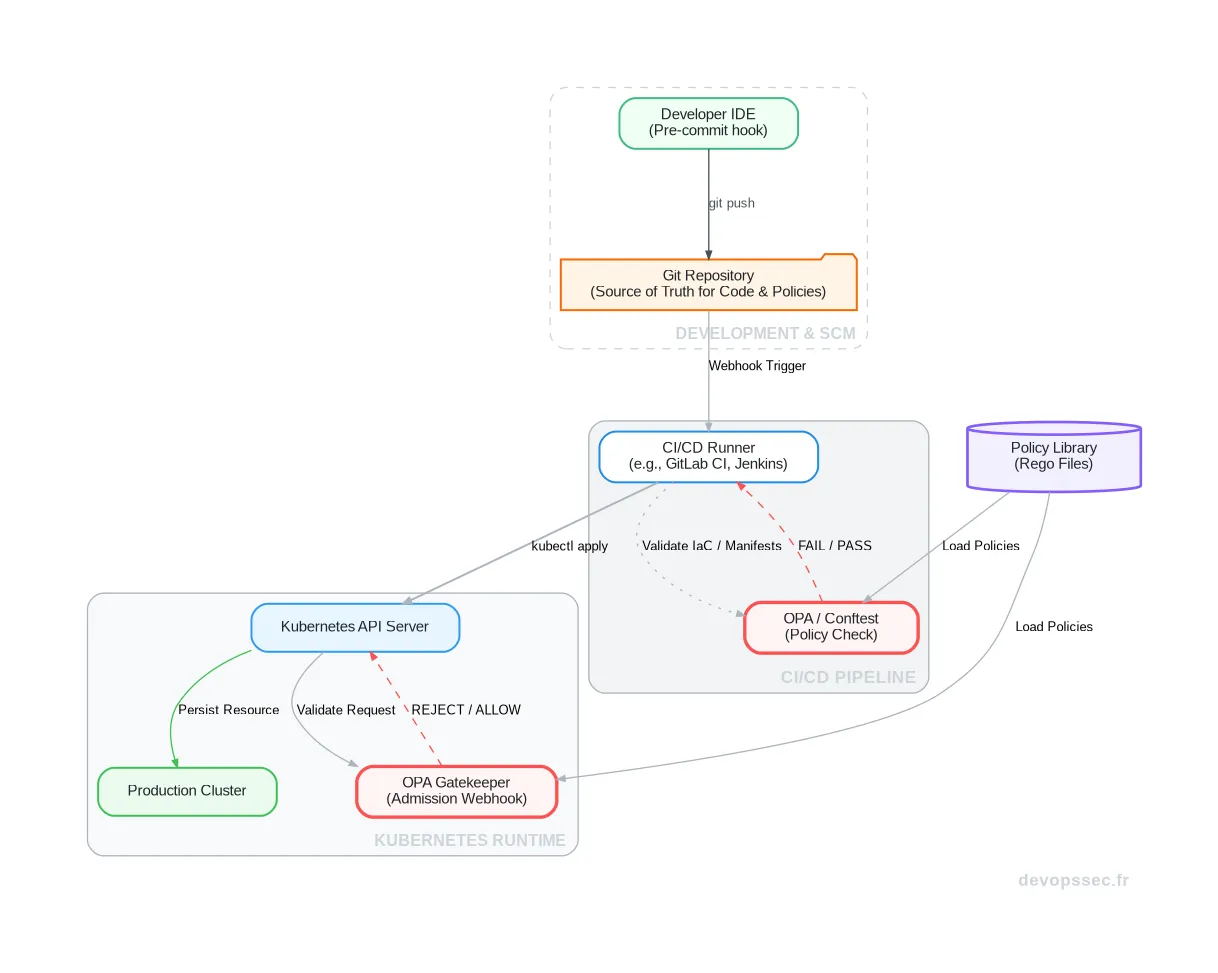
Validation précoce dans la CI/CD
L'un des plus grands bénéfices du Policy-as-Code est sa capacité à s'intégrer nativement dans le pipeline de CI/CD. Avant même qu'une ligne de code d'infrastructure (Terraform, CloudFormation) ou un manifeste Kubernetes ne soit appliqué, on peut le valider contre notre bibliothèque de politiques.
Des outils comme Conftest, qui s'appuie sur le moteur OPA, permettent de scanner ces fichiers de configuration. Si une règle est violée, par exemple un pod Kubernetes qui demande des privilèges excessifs, le pipeline échoue immédiatement. Le développeur reçoit un retour instantané et peut corriger le tir avant que le déploiement n'ait lieu.
Le Shift Left en action
Cette pratique est l'incarnation même du principe "Shift Left". En déplaçant les contrôles de sécurité et de conformité le plus tôt possible dans le cycle de développement, on réduit drastiquement le coût et le temps nécessaires pour corriger les anomalies.
Voici à quoi pourrait ressembler la sortie d'un pipeline qui a détecté une non-conformité :
conftest test deployment.yamlRésultat:
FAIL - deployment.yaml - main - Container 'nginx' is running as root. Containers must run as non-root user.
FAIL - deployment.yaml - main - Missing required label 'app.kubernetes.io/name' for pod spec.Ce retour est immédiat, précis, et permet une action corrective sans avoir à attendre un audit de sécurité plusieurs semaines plus tard. C'est un gain de temps et de sérénité pour toute l'équipe.
Les défis et considérations à ne pas négliger
Si l'approche Policy-as-Code est révolutionnaire, son implémentation n'est pas une simple formalité. Adopter cette philosophie demande une réflexion stratégique et une acculturation des équipes, car elle introduit une nouvelle couche de complexité et de responsabilité.
La courbe d'apprentissage et la maintenance des politiques
Le premier obstacle est souvent la courbe d'apprentissage du langage Rego. Bien que puissant, il n'est pas trivial et demande un investissement initial pour que les équipes soient à l'aise pour lire, écrire et débugger des politiques. C'est une nouvelle compétence à acquérir.
De plus, les politiques ne sont pas statiques. Elles doivent vivre et évoluer avec ton application et ton infrastructure. Cela implique de mettre en place une gouvernance pour les politiques elles-mêmes : qui peut les modifier ? Comment sont-elles testées ? Comment sont-elles versionnées et déployées ? Sans ce cadre, tu risques de créer un "policy drift" où les règles appliquées ne correspondent plus aux besoins réels.
Trouver le juste équilibre
Un autre défi majeur est de trouver le bon équilibre entre sécurité et agilité. Des politiques trop restrictives peuvent rapidement devenir un frein pour les équipes de développement, générant de la frustration et des tentatives de contournement. Il est donc crucial de co-construire ces règles avec les développeurs.
| Avantages d'une approche collaborative | Risques d'une approche en silo |
|---|---|
| Les politiques sont mieux comprises et acceptées. | Les règles sont perçues comme une contrainte externe. |
| Moins de friction et de blocages dans les pipelines. | Augmentation du "shadow IT" et des contournements. |
| Les développeurs deviennent des acteurs de la sécurité. | La sécurité reste le problème d'une seule équipe. |
La collaboration est la clé. Impliquer toutes les parties prenantes (Dev, Ops, Sec) dans la définition des politiques garantit qu'elles sont pertinentes, comprises et qu'elles n'entravent pas la capacité des équipes à innover.
Conclusion : Vers une confiance automatisée
Le Policy-as-Code n'est pas juste une nouvelle technologie à la mode. C'est une évolution culturelle profonde qui répond à la complexité croissante de nos systèmes. En traitant nos règles de gouvernance comme du code, nous les rendons visibles, testables, et surtout, automatisables.
Cela nous permet de construire une confiance systémique dans nos déploiements. Plutôt que de reposer sur des vérifications humaines faillibles, nous déléguons cette charge à des automates infatigables qui garantissent que chaque modification respecte les garde-fous que nous avons collectivement définis.
Pour toi, jeune ingénieur DevOps, maîtriser ces concepts est un investissement majeur. C'est la compétence qui te permettra de construire des plateformes non seulement agiles et rapides, mais aussi fondamentalement sûres, résilientes et conformes par conception.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
21 commentaires
C'est pour ça qu'on teste en mode
dry-runavant d'appliquer. Il ne faut jamais pousser une policy sans passer par une suite de tests unitaires sur tes manifestes de test. La rigueur, encore la rigueur.Et si ta policy est buggée ? Tu bloques toute la prod. C'est déjà arrivé à un collègue sur un cluster en prod, il avait mal écrit une règle et tout le déploiement a été refusé. Le risque de blocage est réel.
Les scripts ne remplacent pas les humains, ils les libèrent des tâches répétitives. On automatise le contrôle pour que les humains se concentrent sur l'architecture, pas sur la vérification de chaque tag dans chaque
service.yaml.Est-ce qu'on peut vraiment automatiser la confiance ? Ça sonne très marketing. La confiance, ça se gagne avec des bons processus humains et des revues de code, pas avec des scripts Rego.
Le coût est réel, je ne vais pas le nier. Mais la question est : quel est le coût de ne rien avoir ? Une fuite de données ou un cluster mal configuré qui expose tout à Internet, c'est ça le vrai risque.
Totalement d'accord avec 9. On finit par passer plus de temps à maintenir nos outils de gouvernance qu'à livrer des features. L'article oublie de mentionner que le coût opérationnel est énorme.
La standardisation, c'est bien, mais la complexité, c'est le vrai ennemi. À chaque fois que je vois un nouveau projet qui rajoute une couche d'abstraction, je transpire.
Kyverno est super pour Kubernetes, mais OPA est agnostique. Si tu veux appliquer les mêmes politiques sur Terraform, tes fichiers CloudFormation et K8s, OPA est bien plus polyvalent. C'est une question de standardisation.
Perso je préfère Kyverno. C'est du YAML pur, pas besoin d'apprendre un langage obscur comme Rego. Pourquoi s'entêter sur OPA ?
Sympa l'exemple, mais OPA c'est lourd à déployer dans un cluster, surtout si t'as déjà des contraintes de ressources. Vous utilisez quoi comme sidecar pour injecter ça ?
Tu joues sur les métadonnées. Tu ajoutes une annotation spécifique dans ton
deployment.yamlet ta règle Rego l'ignore. Exemple :Comment tu gères les exceptions ? Genre le service legacy qui DOIT tourner en root parce qu'il a besoin d'accéder à un périphérique spécifique sur l'hôte ? Le
denyglobal, il fait quoi ?Le temps perdu est un investissement. Le feedback immédiat via
conftestempêche de déployer des erreurs qui coûtent des heures d'astreinte. C'est pas une question de vitesse, c'est une question de fiabilité.C'est surtout le risque du
policy drift. Si tu changes une règle globale, tu dois vérifier tout ton historique. C'est une usine à gaz, faut arrêter de vendre ça comme une solution miracle.Le
Shift Leftc'est mignon sur le papier, mais en pratique, ça ralentit le déploiement de 30%. On a des devs qui attendent 5 minutes que le scan termine pour un simple changement de config. C'est du temps perdu.Il faut traiter tes politiques comme ton code applicatif. Voici la structure que je recommande pour éviter le chaos :
Tu testes tes policies avec
conftestavant chaque merge. Si ça casse, la PR est bloquée. C'est du TDD pour ta gouvernance.Parle-moi de la maintenance. Une fois que tu as 50 politiques en
.rego, tu fais comment pour les gérer sans que ça devienne un enfer de versioning ? On a fini avec un dépôt dédié aux policies, c'est devenu injouable.C'est là que la culture intervient. Si tu imposes des règles sans expliquer pourquoi, les gens vont chercher à contourner, c'est humain. Il faut que le feedback soit clair dans la CI, pas juste un log cryptique.
Je suis d'accord avec 1. On a tenté d'imposer ça sur nos pipelines CI/CD. Résultat : les devs contournent tout avec des
kubectl apply --forceou des annotations pour ignorer les contrôles. Si c'est pas fluide, ça devient une contrainte insupportable.C'est vrai que la syntaxe de Rego demande un temps d'adaptation. Mais comparer ça au coût de corriger une faille de sécurité en prod, le calcul est vite fait. On préfère galérer sur
opa testque de passer trois jours à patcher un cluster compromis.Encore un article qui vend du rêve. Rego, c'est une usine à gaz sans nom. Tu as déjà essayé de débugger une règle complexe avec
opa testquand ça part en sucette ? La courbe d'apprentissage est violente pour une équipe qui veut juste déployer.