Le grand malentendu : quand la vélocité brise la stabilité
Vos pipelines de déploiement continu affichent un vert éclatant, vos développeurs célèbrent dix déploiements par jour, et pourtant votre support technique croule sous les plaintes d'utilisateurs confrontés à des latences de plusieurs secondes. C’est la réalité amère de nombreuses organisations qui ont confondu la vitesse de livraison avec la qualité de service. Le divorce entre les équipes chargées de pousser le code et celles chargées de maintenir le système en vie n'est pas une fatalité technique, mais une rupture méthodologique majeure.
D'un côté, le mouvement DevOps pousse à l'automatisation extrême et à la réduction du temps de mise sur le marché. De l'autre, le Site Reliability Engineering (SRE) applique des principes d'ingénierie logicielle pour garantir que l'infrastructure reste debout à n'importe quel prix. Lorsque ces deux philosophies s'affrontent sans arbitre, l'infrastructure devient un champ de bataille où le moindre déploiement se transforme en roulette russe pour la production.
Les angles morts d'une cohabitation forcée
Le mirage de l'ingénieur DevOps universel
L'erreur classique consiste à renommer les anciens administrateurs système en "ingénieurs DevOps" et à leur demander d'écrire des scripts YAML à longueur de journée. Cette transition superficielle crée des silos encore plus profonds où les développeurs balancent du code par-dessus le mur de la production en s'imaginant que l'automatisation résoudra magiquement les problèmes de conception. On se retrouve alors avec des architectures microservices hyper-complexes mais totalement impossibles à monitorer en conditions réelles.
L'approche Site Reliability Engineering, théorisée à l'origine par Google, aborde le problème sous un autre angle : traiter les opérations comme s'il s'agissait d'un problème logiciel. Le SRE ne se contente pas de déployer, il conçoit des systèmes capables de s'auto-guérir. Le tableau ci-dessous met en lumière les divergences opérationnelles qui causent la friction quotidienne entre ces deux profils.
| Indicateur | Philosophie DevOps | Approche SRE |
|---|---|---|
| Objectif principal | Maximiser la fréquence des déploiements. | Garantir la fiabilité et la disponibilité du service. |
| Mesure du succès | Lead Time, Deployment Frequency, MTTR. | Respect des SLO/SLI, préservation de l'Error Budget. |
| Gestion des pannes | Correction rapide par des correctifs continus. | Analyse post-mortem systémique et automatisation des remèdes. |
| Outils de prédilection | CI/CD, Terraform, Helm, Registres de conteneurs. | Prometheus, OpenTelemetry, scripts d'auto-remédiation. |
La guerre des métriques : Vélocité contre Stabilité
Le conflit éclate lorsque les incitations de performance divergent. Les équipes DevOps sont souvent évaluées sur leur capacité à livrer de nouvelles fonctionnalités à un rythme soutenu, tandis que les SRE portent la responsabilité de la haute disponibilité. Si vos développeurs ont carte blanche pour déployer sans tenir compte de la dégradation des performances réseau, l'équipe d'exploitation passe son temps à éteindre des incendies au lieu d'améliorer l'infrastructure.
Pour illustrer cette fracture, voici l'exemple typique d'une alerte Prometheus mal configurée qui ignore la réalité du trafic et finit par saturer les canaux Slack de notifications inutiles, désensibilisant ainsi les équipes opérationnelles.
# Alerte DevOps naïve basée uniquement sur le taux d'erreur brut
groups:
- name: api-alerts
rules:
- alert: HighErrorRate
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) > 10
for: 2m
labels:
severity: critical
annotations:
summary: "Trop d'erreurs 5xx détectées sur l'API"Résultat lors d'une campagne de tests de charge :
[ALERT] HighErrorRate triggered - Active Alerting on Slack Channel #ops-spam
Details: Current error rate is 12 req/sec. (Threshold: 10)
Status: False Positive caused by a scheduled load-test. No actual customer impact detected on critical paths.Le piège des alertes absolues
Les alertes basées sur des valeurs absolues sans corrélation avec le volume global de trafic ou le comportement des utilisateurs réels sont le meilleur moyen de fatiguer vos équipes d'astreinte et de masquer les véritables pannes applicatives.
Anatomie d'une panne : quand le manque d'alignement détruit la production

Le déploiement aveugle du vendredi après-midi
Prenons un cas réel d'échec constaté chez un e-commerçant majeur. Une équipe produit déploie un microservice de recommandation optimisé pour la vitesse de chargement. Le pipeline GitHub Actions passe au vert sans aucune erreur. Malheureusement, le service consomme silencieusement 100% de la mémoire disponible sur les nœuds Kubernetes en raison d'une mauvaise gestion des connexions à la base de données.
Faute d'une définition claire de l'Error Budget partagé, aucun mécanisme n'interrompt le déploiement progressif. Quelques minutes plus tard, l'effet domino s'enclenche : les nœuds du cluster s'effondrent les uns après les plus autres sous l'effet du mécanisme Out-Of-Memory (OOM) killer de Linux.
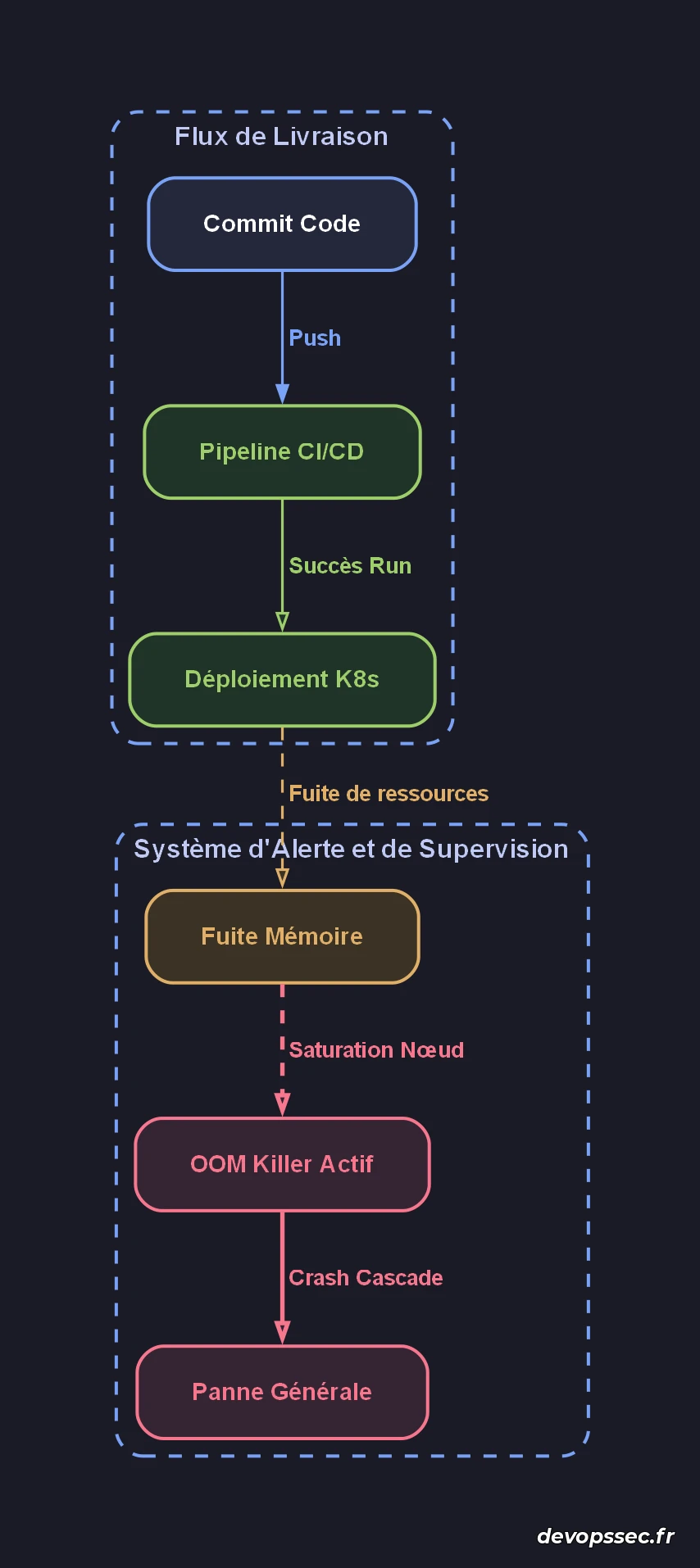
Le schéma ci-dessus met en évidence la faille de communication et de contrôle entre les deux silos. Alors que le flux DevOps valide l'étape de livraison purement technique, l'absence de garde-fous dynamiques côté SRE laisse la fuite de mémoire se propager jusqu'au crash global de l'infrastructure. Sans métriques de santé applicative partagées, les signaux d'alerte restent isolés.
La résolution : implémenter un arrêt d'urgence automatisé
Pour éviter cette catastrophe, le SRE doit configurer des sondes de disponibilité intelligentes et lier les déploiements à la consommation réelle du budget d'erreur. Si la latence au 95ème centile (p95) augmente de plus de 5% par rapport à la veille, le déploiement doit être immédiatement annulé et un rollback automatique déclenché.
Voici un exemple de configuration de ressource Kubernetes avancée intégrant des sondes de démarrage (startupProbe) et des limites de ressources strictes, empêchant un conteneur défaillant d'impacter le reste de l'infrastructure.
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-service-production
namespace: production
spec:
replicas: 5
template:
spec:
containers:
- name: api-worker
image: internal-registry.net/api-worker:v2.4.1
resources:
limits:
cpu: "1"
memory: "512Mi"
requests:
cpu: "250m"
memory: "256Mi"
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /live
port: 8080
periodSeconds: 15Bâtir une passerelle technique robuste
La solution ne réside pas dans de grands discours managériaux, mais dans l'intégration étroite des architectures logicielles avec la télémétrie. En définissant des Service Level Objectives (SLO) réalistes, vous donnez aux développeurs une cible concrète de fiabilité à respecter lors de la conception de leur code.
Lorsque le budget d'erreur alloué à un service pour le mois en cours est consommé à plus de 80%, le pipeline de déploiement automatique doit être automatiquement verrouillé pour les nouvelles fonctionnalités, forçant l'équipe de développement à se concentrer exclusivement sur la résolution des bugs et la stabilité système.
L'alignement culturel par le code
Le véritable DevOps et le SRE ne s'excluent pas mutuellement. Considérez le SRE comme une implémentation pragmatique et scientifique des principes théoriques du DevOps. L'automatisation doit servir la fiabilité autant que la rapidité de déploiement.
Pour réconcilier vos équipes, mettez en place des post-mortems sans blâme après chaque incident majeur. L'objectif n'est pas de désigner un coupable au sein des équipes de développement ou d'exploitation, mais de comprendre pourquoi le système a permis à cette erreur de se propager en production. C'est à ce prix que vous construirez une culture d'ingénierie résiliente et performante.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
Un
AdmissionControllerdoit toujours avoir une porte de sortie pour les situations d'urgence.Mais 90% des déploiements du vendredi ne sont pas des urgences vitales. C'est juste de la précipitation.
Le jour où vous aurez une panne critique à corriger en urgence le vendredi soir, vous serez bien contents de pouvoir bypasser votre
AdmissionController.Je suis d'accord avec l'auteur sur le risque du déploiement du vendredi. On a mis en place un
AdmissionControllerqui bloque tout déploiement après 16h.C'est radical mais efficace.
Exactement. L'instrumentation est la clé. Sans visibilité sur ce qui se passe à l'intérieur de tes conteneurs, tu es aveugle.
Si tu ne peux pas tracer une requête, tu ne fais pas du DevOps, tu fais du 'prie pour que ça marche'.
On utilise du
GrafanaavecTempopour le tracing. Ça aide à voir quelle requête flingue la mémoire. Mais bon, faut encore que les devs instrumentent leur code avecOpenTelemetry.Et pour le monitoring, vous utilisez quoi réellement pour corréler les logs et les métriques ? Prometheus seul ça ne suffit pas quand t'as une fuite mémoire.
On n'a pas besoin d'experts infra, on a besoin de développeurs qui comprennent les contraintes de l'environnement d'exécution.
Si ton code consomme 2 Go de RAM par défaut, tu dois le savoir avant de pousser ton image.
Le vrai SRE, c'est d'arrêter de vouloir automatiser l'humain. Le problème c'est qu'on demande aux devs d'être des experts infra.
Au final, personne n'est expert en rien.
Je bosse sur du legacy, et les
livenessProbesur des apps monolithiques qui mettent 3 minutes à démarrer, c'est l'enfer.On finit par mettre des
initialDelaySecondsaberrants. C'est du bricolage.C'est vrai. Si tu commences à chercher un coupable, tu perds le bénéfice du post-mortem. L'idée c'est de se demander : comment le système a permis cette erreur ?
Si un seul dev peut faire tomber la prod, c'est que ton architecture est mal foutue, pas que le dev est nul.
L'article parle de
post-mortemsans blâme. J'en ai fait des dizaines. À la fin, c'est toujours la même personne qui se fait pointer du doigt en douce.C'est la culture d'entreprise qui est pourrie, pas l'outillage.
Parlons des
resourcesdans ledeployment.yaml. Mettre des limites strictes c'est bien, mais ça demande de connaître parfaitement son app.Si tu mets des
limitstrop basses, tu brises les perfs. Si tu mets trop haut, tu gaspilles du fric. Le juste milieu est introuvable.C'est là que le rôle du SRE devient politique. Si tu ne sais pas dire 'non' en t'appuyant sur des données, tu n'es qu'un exécutant.
Le
error budgetest là pour avoir une discussion factuelle avec le PO, pas pour faire la police tout seul dans son coin.Le verrouillage des déploiements quand le budget est épuisé, c'est la théorie. En pratique, le business force le passage en prod pour une 'feature critique' et tout ton bel édifice SRE s'écroule.
Je suis d'accord sur le constat des alertes. On a remplacé le spam par email par du spam Slack. C'est juste plus moderne, mais tout aussi inutile.
Qui ici utilise vraiment des
error budgetpour bloquer les déploiements ? Ça me semble être une utopie managériale.C'est une vision un peu radicale. Le but n'est pas de leur donner les clés du camion, mais de leur fournir des garde-fous dans le pipeline.
Si tu laisses un dev gérer les limites mémoires sans contrainte, tu finis avec un
OOMKilledglobal dès le premier pic de trafic.Le problème de fond c'est le découplage. Tant que les devs n'ont pas la main sur la prod via
kubectl, ils ne comprendront jamais pourquoi leur code crash.Le SRE est une béquille pour masquer le manque de compétences OPS des développeurs.
L'exemple de l'alerte Prometheus est criant de vérité. On a tous eu des alertes
HighErrorRatequi se déclenchent pendant les tests de charge.Mais mettre en place des SLOs corrects, c'est un enfer politique. Personne ne veut admettre que son service n'est pas disponible à 99.99%.
Justement, le
CrashLoopBackOffest ton meilleur ami ici. Il empêche un pod défectueux de bouffer toutes les ressources de ton nœud et de tuer tes autres services.La différence, c'est qu'avec une
startupProbe, tu laisses le temps à ton app de charger ses connexions DB avant de dire à Kubernetes qu'elle est prête. C'est du basique, mais ça sauve des vies.Encore un article qui idéalise le SRE. Dans la vraie vie, le SRE c'est juste le sysadmin de luxe qui se fait appeler par les devs à 3h du mat parce qu'ils ont poussé un truc non testé.
Le coup des
startupProbe, c'est bien gentil, mais si ton app est mal codée, ça va juste faireCrashLoopBackOffà répétition et saturer ton cluster.