Pourquoi vos CPU s'emballent dans le vide : l'art de l'ordonnancement
Vos serveurs de production affichent une charge CPU à 100%, pourtant vos requêtes HTTP s'accumulent dans la file d'attente et le débit s'effondre de moitié. Ce paradoxe classique cache une réalité souvent ignorée par les développeurs juniors : vos coeurs de processeur ne travaillent pas pour votre application, ils s'épuisent à gérer l'organisation interne du système d'exploitation.
Nous allons analyser les mécanismes internes du noyau Linux qui provoquent ce phénomène de sur-sollicitation invisible. Comprendre comment le processeur bascule d'une tâche à l'autre vous permettra d'éviter les pièges de performance majeurs et d'architecturer des applications hautement concurrentes véritablement efficaces.
Aux origines de l'ordonnancement Linux : du CFS à EEVDF
Pour comprendre pourquoi vos threads tournent à vide, il faut d'abord analyser l'arbitre central de votre système d'exploitation : l'ordonnanceur (ou scheduler). Cet algorithme décide à chaque milliseconde quel thread a le droit d'exécuter ses instructions sur quel coeur de processeur physique.
L'évolution vers EEVDF et les exigences architecturales
Pendant plus de quinze ans, le noyau Linux a utilisé le Completely Fair Scheduler (CFS). Son but était de distribuer équitablement le temps de processeur disponible entre toutes les tâches en s'appuyant sur un arbre rouge-noir. Cependant, le CFS souffrait d'un problème majeur : il ne gérait pas correctement la latence des tâches interactives ou en temps réel qui requièrent des réponses immédiates sans pour autant consommer beaucoup de temps de calcul.
Les noyaux modernes ont donc introduit l'algorithme EEVDF (Earliest Eligible Virtual Deadline First). Cet ordonnanceur calcule dynamiquement une date limite virtuelle pour chaque processus, garantissant que les tâches légères mais urgentes passent en priorité devant les longs calculs en arrière-plan. Pour en tirer parti, votre système doit disposer d'un noyau Linux moderne configuré avec l'option CONFIG_SCHED_DEBUG activée pour surveiller ces métriques.
Le piège de la sur-parallélisation et le coût de la concurrence
Le coût caché du changement de contexte

Le changement de contexte est le mécanisme par lequel le processeur interrompt l'exécution d'un thread pour en lancer un autre. Imaginez un banquier qui doit s'occuper d'une file d'attente interminable : s'il doit ranger tous les papiers du client A, nettoyer son bureau, sortir le dossier du client B et se remémorer où ils s'étaient arrêtés toutes les dix secondes, il passera sa journée à ranger des dossiers plutôt qu'à traiter les demandes. C'est exactement ce qui se produit lors d'une sur-parallélisation.
Lors d'un changement de contexte, le noyau doit sauvegarder les registres du processeur, vider ou invalider les mémoires caches ultra-rapides L1 et L2, et recharger la table des pages mémoire (TLB). Ce processus peut consommer plusieurs milliers de cycles d'horloge pendant lesquels aucune ligne de votre code applicatif n'est exécutée. Lorsque vous configurez trop de threads par rapport au nombre de coeurs physiques disponibles, vous provoquez une gigue d'ordonnancement permanente.
Le fléau de l'invalidation de cache
Un changement de contexte ne se résume pas à copier des registres de mémoire. L'invalidation du cache L1/L2 force le processeur à récupérer les données directement dans la mémoire RAM principale (beaucoup plus lente), créant un goulot d'étranglement matériel invisible.
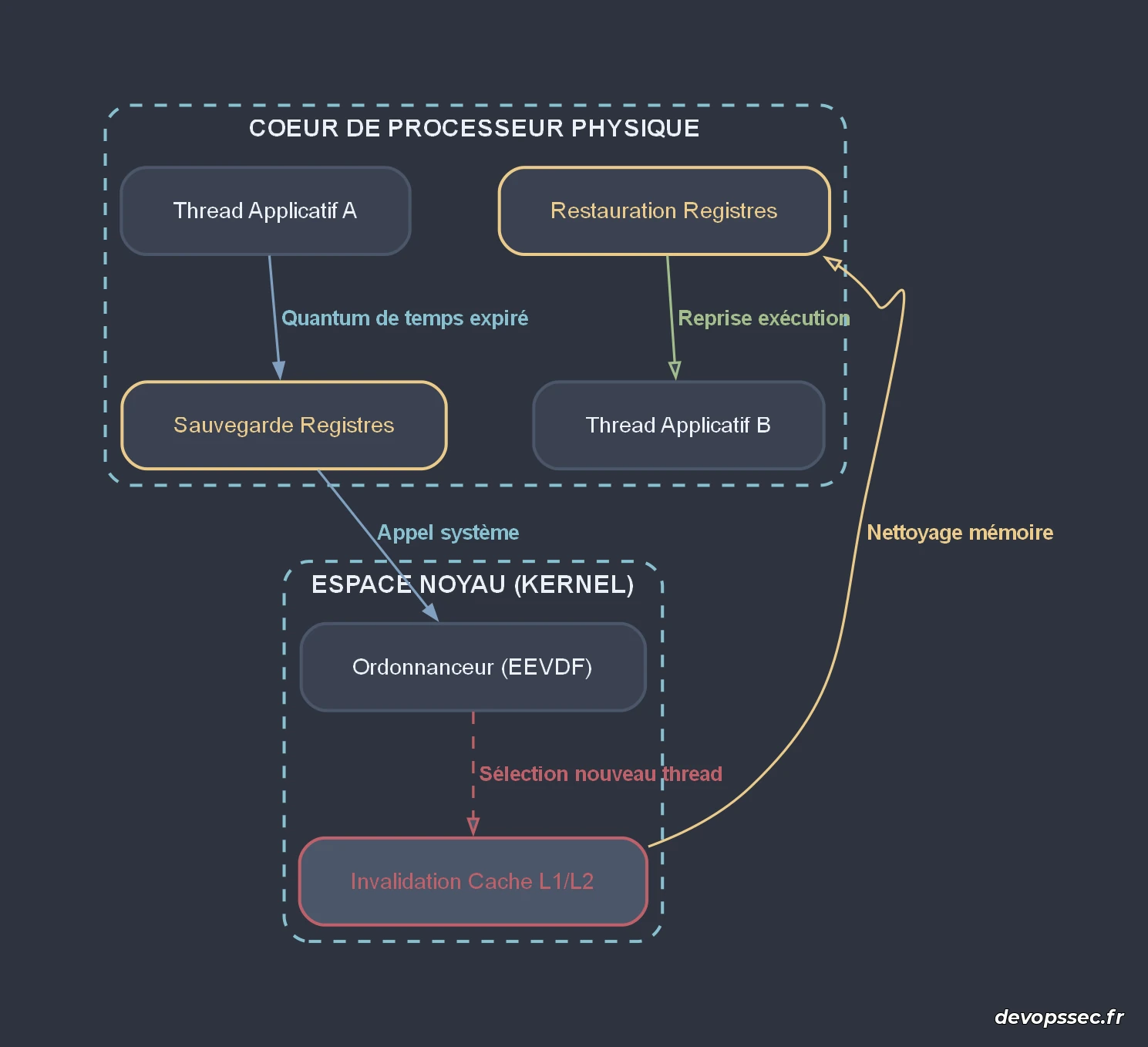
Le schéma ci-dessus illustre la transition imposée par l'ordonnanceur. Lorsqu'un thread dépasse son temps d'allocation, l'ordonnanceur interrompt le cycle d'exécution nominal. On constate clairement que les étapes de sauvegarde, de sélection algorithmique et d'invalidation des mémoires caches représentent une perte de temps matérielle critique, représentée en rouge et orange, pénalisant directement les performances de l'application globale.
Diagnostic et surveillance en production : traquer l'inactivité forcée
Analyser les métriques système avec pidstat et perf
Pour diagnostiquer si votre application souffre de ce problème d'inactivité forcée, vous devez analyser le comportement de vos processus au niveau du système d'exploitation. La commande pidstat, incluse dans le paquet sysstat, est l'outil idéal pour cela. Elle permet de dissocier les changements de contexte volontaires des changements involontaires.
Un changement de contexte volontaire se produit lorsque votre application attend une ressource externe (comme une réponse de base de données ou une lecture de fichier). Un changement de contexte involontaire survient lorsque l'ordonnanceur force votre thread à s'arrêter parce qu'il a épuisé son temps de calcul autorisé. Si ce dernier indicateur est trop élevé, votre système est en sur-utilisation critique.
pidstat -w -I -p ALL 2 5Résultat:
Linux 6.8.0-generic (prod-web-01) _x86_64_ (16 CPU)
03:14:02 PM UID PID cswch/s nclcs/s Command
03:14:04 PM 1001 12345 1254.20 8945.10 node-app
03:14:04 PM 1001 12450 102.10 15.40 db-workerDans l'exemple de log ci-dessus, on constate que le processus node-app subit près de 9000 changements de contexte non volontaires par seconde (nclcs/s). C'est le signal d'alarme typique indiquant que l'application tente d'exécuter trop d'opérations simultanées par rapport aux capacités réelles des coeurs de calcul.
| Métrique | Valeur cible saine | Seuil d'alerte critique | Impact sur la production |
|---|---|---|---|
| cswch/s (Changements volontaires) | < 2000 / sec | > 10000 / sec | Attentes d'I/O réseau ou disque bloquantes |
| nclcs/s (Changements involontaires) | < 500 / sec | > 3000 / sec | Saturation du processeur par l'ordonnanceur |
| CPU % (Utilisation CPU) | 50% - 70% | > 90% | Surchauffe, augmentation drastique des temps de réponse |
Optimisation de production : dompter les pools de threads
Configuration d'une affinité CPU et limitation dynamique
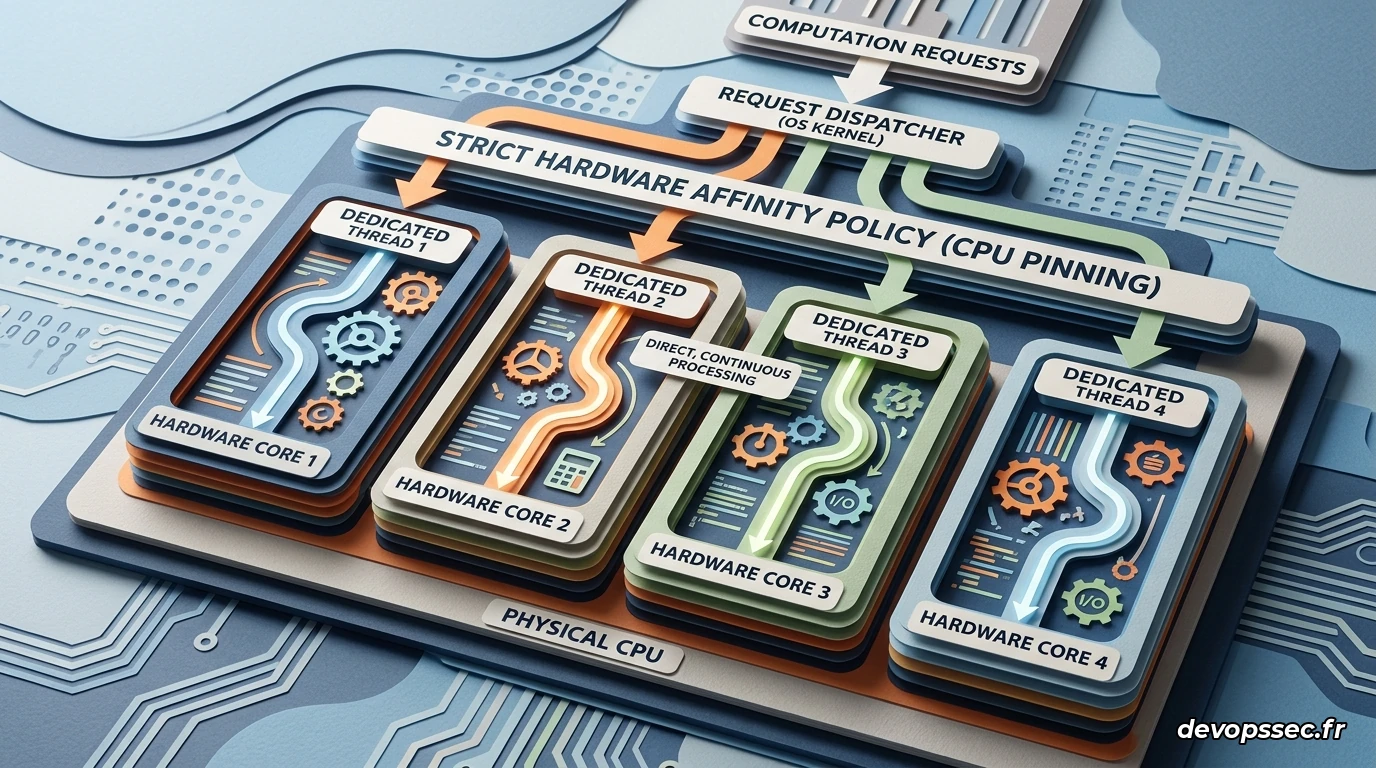
Pour éliminer définitivement la gigue d'ordonnancement, la meilleure stratégie consiste à adapter la taille de vos pools de threads au nombre exact de coeurs d'exécution disponibles. Dans les environnements conteneurisés comme Kubernetes, il est également impératif de configurer correctement les quotas pour éviter que le noyau ne bride vos applications de manière brutale.
Voyons comment configurer un serveur d'API haute performance écrit en Go pour lui attribuer une affinité CPU spécifique et configurer au plus juste l'ordonnanceur interne. L'exemple de code ci-dessous montre comment restreindre l'empreinte processeur d'une application pour éliminer les conflits d'ordonnancement.
package main
import (
"fmt"
"runtime"
"sync"
"syscall"
)
// Définir le masque d'affinité CPU au niveau système
func setCPUAffinity(coreID int) error {
var mask syscall.CpuSet
mask.Zero()
mask.Set(coreID)
// Associe le processus courant uniquement au coeur spécifié
err := syscall.SchedSetaffinity(0, &mask)
if err != nil {
return fmt.Errorf("impossible de définir l'affinité CPU : %w", err)
}
return nil
}
func main() {
// Limiter le nombre de threads d'exécution Go au nombre de coeurs physiques
numCores := runtime.NumCPU()
runtime.GOMAXPROCS(numCores)
// Assigner le thread principal sur le coeur physique numéro 0
if err := setCPUAffinity(0); err != nil {
panic(err)
}
var wg sync.WaitGroup
// Lancement d'un pool de calcul optimisé et sans chevauchement
for i := 0; i < numCores; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
// Simulation d'une boucle de calcul intensive
accumulator := 0
for j := 0; j < 100000000; j++ {
accumulator += j * workerID
}
}(i)
}
wg.Wait()
}Ce code montre une configuration solide pour la production. En limitant le paramètre GOMAXPROCS au nombre réel de coeurs de processeurs détectés, l'application évite d'alimenter inutilement l'ordonnanceur avec des threads en surnombre. De plus, l'utilisation de l'appel système SchedSetaffinity verrouille le processus sur des coeurs précis pour garantir la préservation des données de la mémoire cache L1 et L2.
L'affinité CPU en conteneur
Si vous déployez vos applications sous Docker ou Kubernetes, préférez l'utilisation du paramètre --cpuset-cpus ou le composant CPU Manager de Kubernetes plutôt que de forcer les appels système directement dans le code applicatif.
Dompter l'ordonnanceur pour pérenniser vos infrastructures
Le contrôle précis du comportement de vos threads est un prérequis indispensable pour maintenir des applications de production véloces et stables. Ignorer le coût de la concurrence matérielle revient à gaspiller plus de la moitié de vos ressources d'infrastructure en changements de contexte inutiles.
En surveillant régulièrement les changements de contexte non volontaires et en adaptant la configuration de vos pools d'exécution à la réalité matérielle de vos serveurs, vous éliminerez ces pics d'utilisation CPU fantômes. Gardez à l'esprit que l'efficacité logicielle ne consiste pas à exécuter le plus de tâches possible en même temps, mais à optimiser la fluidité de chaque instruction envoyée au processeur.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
16 commentaires
C'est l'outil de base. Si tu ne l'as pas dans ta toolbox, tu es aveugle sur ce qui se passe réellement sous le capot de ton OS.
Merci pour le rappel sur
pidstat. C'est sous-utilisé ce truc.Oui, ça ajoute un overhead. C'est top pour debugger en staging, mais en prod, garde ça pour les instances de test. Si tu as besoin de monitorer en prod, utilise
ebpf, c'est beaucoup moins invasif.Est-ce que l'activation de
CONFIG_SCHED_DEBUGdans le noyau a un impact sur les perfs en prod ?C'est exactement ça. Le CPU passait plus de temps à faire du switch de contexte qu'à faire du calcul utile. Ton exemple prouve que la simplicité bat souvent la parallélisation sauvage.
Je confirme pour le
GOMAXPROCS. On avait une app qui tournait à 128 threads sur une machine à 16 coeurs. Une fois bridée à 16, la latence p99 a chuté de 40%.Java c'est un cas spécial avec le garbage collector qui tourne en arrière-plan. Si ton GC est mal configuré, il va provoquer des changements de contexte involontaires massifs.
Règle d'or : ajuste tes tailles de heap pour éviter que le GC ne vienne hacher l'exécution de tes threads applicatifs en permanence.
Et pour les applications Java ? Avec la gestion de la JVM, c'est l'enfer à monitorer.
perf statest ton meilleur ami pour ça.C'est violent quand tu vois le pourcentage de misses. Ça calme direct les ardeurs sur la sur-parallélisation.
Super article. J'ai souvent vu des devs ignorer l'invalidation du cache L1/L2. Ils pensent que la RAM est infinie et instantanée.
Quelqu'un a un outil pour visualiser ces cache misses en temps réel ?
Laisse tomber
SchedSetaffinityen conteneur. C'est le meilleur moyen de se prendre desOOMKillsou des conflits avec le scheduler du host.Utilise le CPU Manager de Kubernetes en mode
static. Ça lie tes threads aux coeurs physiques de manière propre au niveau du cgroup.On utilise beaucoup de conteneurs avec Kubernetes. Est-ce que l'affinité CPU via
SchedSetaffinityest pertinente, ou le CPU Manager de K8s gère ça mieux ?Pas de flag magique, faut bosser sur les pools.
Pour Go, force ton
GOMAXPROCSau nombre de coeurs physiques. Pour Node, c'est plus complexe car c'est mono-thread par instance. Si tu as trop denclcs/savec Node, c'est que tu as trop de workers dans ton Cluster module.J'ai testé la commande
pidstat -w -I -p ALL 2 5sur un de mes serveurs en prod, et les chiffres sont affolants sur lesnclcs/s.Comment on réduit ça proprement sans tout réécrire ? Il y a des flags magiques pour limiter la casse côté runtime ?
Clairement. EEVDF est bien plus efficace pour les tâches interactives que l'ancien CFS. Mais attention, ça ne magique pas une architecture mal pensée.
Si ton code génère des milliers de changements de contexte involontaires, EEVDF ne fera que mieux gérer le désastre, mais le coût matériel du cache miss sera toujours là. Le problème reste applicatif, pas noyau.
Article solide. J'ai toujours vu des gens créer des pools de threads gigantesques en pensant que 'plus de threads = plus de vitesse'. C'est une erreur classique.
Est-ce que le passage à EEVDF change vraiment la donne pour des workloads typiquement orientés
microservicesen Go ou Node ?