Briser le mur de la mémoire avec la désagrégation matérielle

Vous avez très certainement déjà observé vos nœuds d'exécution s'effondrer lamentablement sous le poids de traitements analytiques massifs ou de modèles d'apprentissage profond particulièrement voraces en mémoire vive. Historiquement, l'architecture même de nos infrastructures nous enfermait dans un modèle extrêmement rigide où la capacité de traitement était indissociablement liée à la mémoire physiquement soudée sur la carte mère. Par conséquent, dès qu'un processus exigeait un excédent de mémoire critique, la seule solution viable consistait à provisionner des machines lourdement surdimensionnées, gaspillant ainsi de précieuses ressources de calcul qui restaient fatalement inactives.
Aujourd'hui, l'industrie a opéré un virage fondamental pour pallier cette inefficacité chronique en désagrégeant totalement la mémoire du processeur central. C'est ici qu'intervient le protocole Compute Express Link, une technologie d'interconnexion qui permet de déporter la mémoire vive sur des modules d'extension externes tout en conservant une latence comparable à celle de la mémoire locale. En orchestrant ces modules sous forme de grappes indépendantes, il devient possible de provisionner de la mémoire à la volée pour n'importe quelle machine du réseau nécessitant un apport soudain de ressources volatiles.
Pour exploiter pleinement cette flexibilité au sein d'un cluster, nous devons nous appuyer sur l'interface Dynamic Resource Allocation de Kubernetes, qui offre une granularité de contrôle bien supérieure au système traditionnel de limites et requêtes. En combinant ces deux innovations, nous transformons la mémoire RAM d'une contrainte locale stricte en un service réseau provisionnable à la demande, idéal pour les charges de travail transitoires mais intenses. Ce paradigme modifie profondément notre approche de l'infrastructure as code, puisque l'orchestrateur ne cherche plus un nœud disposant d'assez de mémoire, mais demande activement au matériel d'allouer la mémoire nécessaire à un nœud spécifique avant d'y planifier le conteneur.
Comprendre la synergie architecturale entre l'orchestrateur et le matériel
Avant de plonger les mains dans les fichiers de configuration, il est crucial d'assimiler la cinématique d'allocation qui se joue en coulisses lorsqu'un conteneur réclame une portion de mémoire externe. Contrairement au classique plugin d'interface réseau ou de stockage, le système de gestion des ressources dynamiques nécessite l'intervention d'un pilote matériel spécifique tournant directement sur les nœuds de calcul. Ce pilote agit comme un intermédiaire privilégié entre l'API de notre orchestrateur et le commutateur matériel qui gère les différents bancs de mémoire physiques.
Concrètement, lorsqu'un objet de revendication de ressource est soumis au cluster, le contrôleur central évalue la demande et la transmet au pilote d'allocation approprié. Ce dernier interroge alors l'infrastructure matérielle sous-jacente pour réserver un bloc de mémoire exclusif, qu'il va ensuite exposer de manière sécurisée à la machine hôte hébergeant la charge de travail. Ce découplage garantit que la logique d'allocation reste parfaitement abstraite pour le développeur, tout en permettant aux administrateurs de définir des politiques de qualité de service extrêmement fines au niveau matériel.
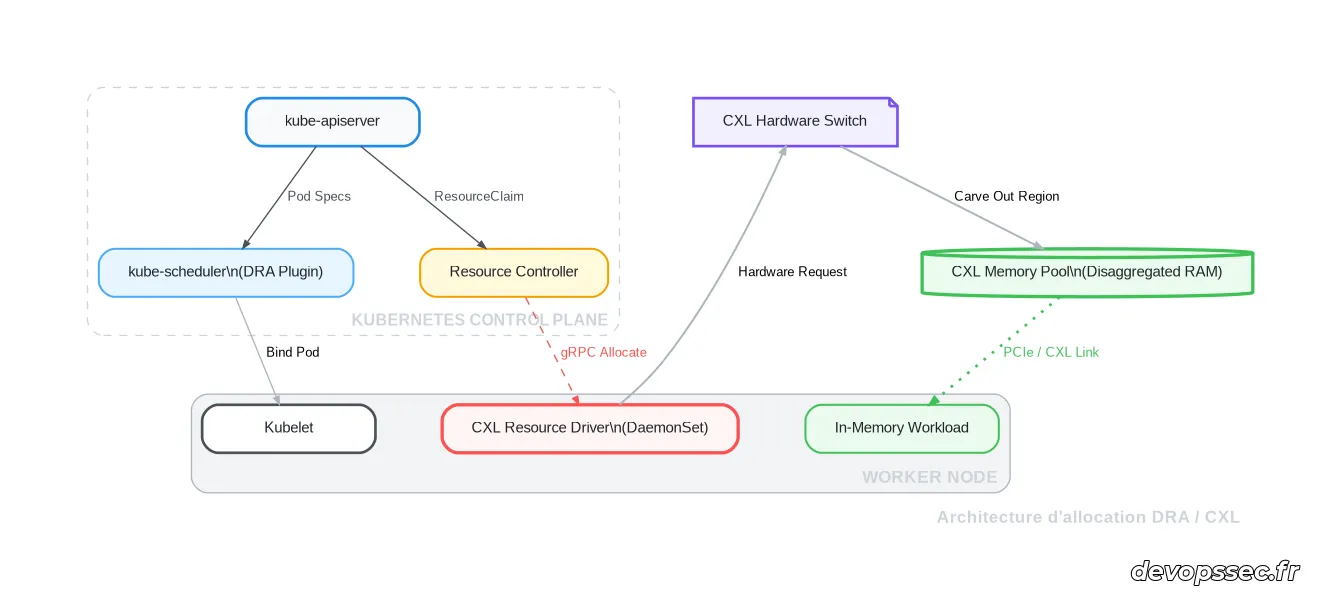
Déploiement pratique de l'allocation mémoire
L'implémentation de cette technologie requiert une séquence d'opérations rigoureuse, débutant systématiquement par la déclaration des ressources physiques auprès de l'orchestrateur. Il est impératif d'utiliser des manifestes descriptifs qui définissent la classe de ressource disponible, afin que le plan de contrôle puisse cartographier avec précision la topologie matérielle du centre de données. Nous allons décomposer ce processus en deux phases distinctes, allant de la configuration du pilote matériel jusqu'à la consommation effective par une application.
Configuration et déploiement du Resource Driver
La première étape de notre implémentation consiste à déployer le pilote d'allocation, souvent distribué sous la forme d'un service s'exécutant sur chaque nœud éligible. Ce composant est responsable de la communication bas niveau avec l'interface matérielle PCIe et nécessite des privilèges étendus pour manipuler les espaces d'adressage mémoire du noyau Linux. Sans lui, les requêtes de votre orchestrateur resteraient de simples intentions logiques incapables de se traduire par une quelconque commutation matérielle.
Pour définir la nature exacte de la ressource proposée, nous devons créer un objet natif spécifique nommé ResourceClass. Cet objet sert de modèle contractuel indiquant au plan de contrôle quel pilote est habilité à traiter ce type particulier de demande d'allocation externe. Observez attentivement la structure YAML suivante, qui lie formellement notre classe de ressource personnalisée au nom d'interface du pilote déployé sur nos machines.
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClass
metadata:
name: cxl-memory-high-performance
driverName: memory.cxl.hardware.vendor.com
parametersRef:
kind: CxlMemoryParameters
name: default-cxl-profile
apiGroup: vendor.cxl.apiUne fois ce fichier enregistré sous le nom resource-class.yaml dans votre répertoire d'infrastructure situé dans /opt/kubernetes/manifests, il convient de l'appliquer directement au sein du cluster. L'application de cette configuration informe immédiatement l'ordonnanceur qu'une nouvelle catégorie de ressources est potentiellement disponible pour les charges de travail entrantes. Nous utilisons l'utilitaire en ligne de commande standard pour injecter ce manifeste et vérifier son intégration dans l'état global du système.
Astuce de validation du pilote
Assurez-vous toujours que les modules noyau nécessaires (comme cxl_pci et cxl_mem) sont correctement chargés sur vos nœuds de travail avant d'appliquer la classe de ressource, sous peine de voir vos revendications bloquées indéfiniment à l'état "Pending".
Pour appliquer la configuration, exécutez la commande d'application standard et listez les classes de ressources reconnues par le serveur d'API. Cette vérification rapide est une étape de validation cruciale qui vous évitera de chercher à déboguer des erreurs complexes lors de la phase de lancement des conteneurs applicatifs.
Exécutez kubectl apply -f resource-class.yaml suivi d'une vérification d'état :
kubectl get resourceclassesRésultat:
NAME DRIVER AGE
cxl-memory-high-performance memory.cxl.hardware.vendor.com 15sInstanciation et liaison applicative avec un Pod
Maintenant que notre classe de ressource est reconnue et active, l'étape suivante consiste à réclamer une portion de ce pool mémoire via une ResourceClaim. Cet objet agit comme un bon de commande indépendant, stipulant la quantité exacte de mémoire externe souhaitée ainsi que les contraintes d'accès associées. Ce modèle permet une flexibilité remarquable, car la revendication est découplée de la définition du conteneur, favorisant ainsi la réutilisation du code d'infrastructure.
L'avantage majeur de cette approche réside dans la clarté de la séparation des responsabilités entre l'équipe gérant l'infrastructure matérielle et celle concevant l'application. La création de la revendication stipule uniquement un besoin métier quantifié, laissant à la logique interne du pilote le soin de trouver la région mémoire la plus appropriée. Le manifeste suivant illustre comment formuler cette demande de provisionnement pour un bloc massif de soixante-quatre gigaoctets de mémoire volatile désagrégée.
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaim
metadata:
name: analytic-memory-claim
spec:
resourceClassName: cxl-memory-high-performance
parametersRef:
kind: CxlMemoryRequest
name: sixty-four-gb-chunk
apiGroup: vendor.cxl.apiUne fois la ressource formellement réclamée, nous devons modifier la définition de notre charge de travail pour y intégrer cette nouvelle capacité d'adressage mémoire. Au lieu de définir des limites classiques dans la section des ressources du conteneur, nous référençons directement notre revendication fraîchement créée. Au moment de la création du pod, l'ordonnanceur bloquera l'exécution tant que le pilote matériel n'aura pas confirmé l'allocation effective et le verrouillage de la zone mémoire sur le commutateur externe.
Afin de bien comprendre les implications pratiques de cette configuration asynchrone, nous pouvons comparer les bénéfices immédiats obtenus par rapport à un provisionnement traditionnel basé sur la mémoire soudée au nœud d'exécution. Les différences architecturales sont substantielles et redéfinissent la manière dont nous devons envisager le dimensionnement de nos environnements de production intensifs.
| Caractéristique architecturale | Mémoire traditionnelle (Node RAM) | Memory Pooling externe |
|---|---|---|
| Granularité d'allocation | Fixée par la capacité physique de la machine hôte. | Dynamique et ajustable à la volée via l'API. |
| Impact sur le CPU | Le sur-provisionnement mémoire bloque des cœurs inactifs. | Isolation parfaite : CPU local, mémoire déportée. |
| Migration de charge | Nécessite de redémarrer le processus sur un gros nœud. | La mémoire peut être réaffectée matériellement sans déplacer le pod. |
Limites, coûts cachés et sécurité matérielle
Aussi séduisante que soit la perspective d'une mémoire infinie et élastique, cette architecture s'accompagne d'un ensemble de compromis techniques majeurs qu'un ingénieur se doit de maîtriser avec lucidité. Le premier frein incontestable réside dans la pénalité de latence inhérente au franchissement du bus externe et du commutateur matériel. Bien que les protocoles récents offrent des performances exceptionnelles, l'accès à une adresse mémoire déportée prendra toujours quelques nanosecondes supplémentaires par rapport à une mémoire cache locale, ce qui peut affecter les algorithmes ultra-sensibles aux délais de traitement très courts.
D'un point de vue purement sécuritaire, le partage d'un même composant matériel physique entre plusieurs machines hébergeant potentiellement des applications de niveaux de criticité différents soulève des questions épineuses. Le concept de voisinage bruyant, où un conteneur sature le contrôleur mémoire et dégrade les performances d'un autre processus isolé sur un nœud distinct, devient une réalité tangible sur ce type d'infrastructure désagrégée. De plus, les risques d'empoisonnement de la mémoire cache ou de fuite de données par canaux auxiliaires exigent que le contrôleur matériel applique des règles de cloisonnement extrêmement strictes au niveau matériel.
Enfin, l'adoption de ce paradigme implique une refonte massive et extrêmement onéreuse de l'équipement sous-jacent du centre de données. Non seulement les serveurs doivent être équipés de bus de communication de toute dernière génération, mais l'acquisition des baies de mémoire externes et des commutateurs intelligents représente un investissement en capital particulièrement lourd. Par conséquent, cette technologie de pointe doit être réservée en priorité à des cas d'usage spécifiques, générant un retour sur investissement mesurable, plutôt que déployée aveuglément pour répondre à de simples problématiques de développement mal optimisé.
- Augmentation de la latence : Impact direct sur les opérations de lecture/écriture nécessitant une synchronisation immédiate du registre CPU.
- Complexité de débogage : Les erreurs de pagination mémoire sont difficiles à tracer lorsqu'elles impliquent un composant réseau intermédiaire.
- Verrouillage fournisseur : Les implémentations matérielles actuelles s'appuient fortement sur des interfaces propriétaires limitant l'interopérabilité entre constructeurs.
- Coût financier : Une barrière à l'entrée élevée nécessitant des fermes de serveurs compatibles et des commutateurs spécialisés extrêmement coûteux.
Un tournant décisif pour l'infrastructure des données massives
En repoussant les frontières physiques traditionnelles du serveur informatique, la combinaison de la désagrégation matérielle et de l'orchestration avancée offre une réponse élégante aux défis posés par les charges de travail d'aujourd'hui. Les équipes opérationnelles disposent désormais d'outils leur permettant de provisionner la capacité volatile avec la même agilité qu'elles allouent du stockage bloc persistant, brisant définitivement le carcan des architectures monolithiques. L'introduction d'un modèle d'allocation dynamique modifie en profondeur l'ingénierie des plateformes en offrant une résilience et une efficacité inédites pour les traitements massivement parallèles.
Il appartient désormais aux architectes de s'emparer de ces nouvelles abstractions pour concevoir des systèmes où la puissance de calcul s'ajuste dynamiquement, en temps réel, aux véritables besoins des applications analytiques. Bien que le chemin vers une adoption généralisée de ces technologies nécessite d'atténuer encore certains risques de sécurité et de lisser les coûts d'intégration matérielle, les bénéfices opérationnels observés sur les environnements à très haute densité sont indéniables. En maîtrisant ces nouveaux leviers, vous ne gérez plus de simples machines, mais un véritable ordinateur géant et unifié où chaque ressource est consommée avec une précision chirurgicale.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
27 commentaires
Dernier conseil : avant de tout casser en prod, validez bien le chargement des modules avec
lsmod | grep cxl.Si les modules ne sont pas là, inutile d'essayer de créer le manifest
ResourceClass.Le CXL "pas cher" n'existe pas encore. Cherche des cartes d'évaluation de chez ASTC ou des serveurs de test chez les gros constructeurs.
Ne t'attends pas à trouver ça sur eBay.
Je vais essayer ça sur un lab. Vous conseillez quoi comme matériel pour débuter sans se ruiner ?
Le protocole CXL permet le chiffrement IDE (Integrity and Data Encryption).
Mais ça dépend de ton hardware. Si ton switch ne le supporte pas, tes données transitent en clair.
Niveau sécurité, c'est chiffré au repos sur le switch ?
Oui, via les
ResourceClaimTemplates. Tu peux restreindre l'usage par RBAC sur l'objet de claim.C'est possible de limiter l'accès à la mémoire CXL par namespace ?
As-tu bien configuré le
ResourceDriver? Le scheduler ne fait rien s'il n'a pas le plugin de tracking correspondant.J'ai testé la config, mais mon
kube-schedulerne semble pas voir la ressource.Le CXL est agnostique au CPU, c'est du PCIe. Tant que ton BIOS supporte le CXL 2.0 ou 3.0, ça passe.
Par contre, vérifie bien la version du firmware de ton contrôleur.
Vous avez des retours sur la compatibilité avec les CPU AMD EPYC ?
Pas si tu as des besoins fluctuants. Si tu as 100 nœuds qui ont besoin de 10GB de RAM en plus ponctuellement, tu ne vas pas acheter 100 machines pour ça.
Le pool centralisé permet de mutualiser.
Sympa l'article. Mais niveau coût, c'est pas plus simple de rajouter des nœuds avec beaucoup de RAM locale ?
Oui, le voisinage bruyant est réel. C'est pour ça qu'il faut bien définir les
parametersRefdans ton manifest.Est-ce qu'il y a un risque d'interférences entre deux conteneurs qui partagent le même pool CXL ?
Regarde les events de ton pod :
kubectl describe pod <nom>.Probablement un problème de permissions sur le device ou le driver qui n'arrive pas à communiquer avec le bus.
Petit souci de mon côté, j'ai mes pods qui restent en
Pendingalors que lekubectl get resourceclassesest OK.Si le switch tombe, la mémoire est coupée. Le kernel panique. C'est une erreur matérielle fatale.
Il faut gérer la haute disponibilité au niveau applicatif, pas au niveau du driver.
Vous gérez comment le failover si le switch CXL tombe ? Le pod crash instantanément ou le driver tente une reconnexion ?
C'est l'API standard pour le DRA (Dynamic Resource Allocation). Oui, c'est alpha, mais c'est le seul moyen d'avoir cette granularité.
Si tu veux du stable, reste sur du provisionnement statique et attends encore deux ans.
Je vois que vous utilisez
resource.k8s.io/v1alpha2. C'est pas un peu risqué pour du long terme ?À ne jamais faire en prod.
Le CXL est une ressource physique réservée. Si tu overcommit, tu vas juste te manger des OOM Killer à la chaîne dès que la charge monte.
Le
ResourceClassc'est sympa, mais est-ce qu'on peut faire de l'overcommit sur la mémoire CXL comme on le fait avec la RAM locale ?Oublie les packages officiels. Il faut compiler le driver avec les headers correspondant à ton noyau.
Vérifie bien que tes modules
cxl_pcietcxl_memsont chargés avant de lancer le daemon.J'ai testé le déploiement du driver sur un noyau 6.x. Ça demande de compiler le module à la main ou vous avez des packages propres pour Debian ?