L'IA quitte le Cloud : Pourquoi votre prochain défi DevOps se jouera en périphérie
Vous avez certainement remarqué cette tendance de fond : l'intelligence artificielle n'est plus l'apanage exclusif des puissants datacenters. Elle infuse désormais nos voitures, nos usines et même nos appareils domestiques. Cette migration massive du Cloud vers la "périphérie" (l'Edge) crée une rupture technologique majeure, et avec elle, un nouveau terrain de jeu pour nous, les ingénieurs DevOps.
Le défi n'est plus de déployer un modèle sur un cluster Kubernetes bien au chaud dans un VPC, mais d'orchestrer des milliers, voire des millions, de modèles d'IA sur une flotte d'appareils hétérogènes, souvent dotés de ressources limitées et d'une connectivité intermittente.
C'est ici qu'intervient une discipline à la fois passionnante et exigeante : le MLOps à la Périphérie. Il s'agit d'adapter les pratiques d'industrialisation du Machine Learning aux contraintes uniques de l'Edge Computing, pour garantir que l'IA puisse opérer de manière autonome, robuste et sécurisée, au plus près de l'action.
Comprendre le "Edge" : Plus qu'une simple délocalisation
Avant de plonger dans la tuyauterie, il est crucial de bien saisir ce qu'est réellement l'Edge Computing. Il ne s'agit pas simplement de "faire tourner des choses en dehors du Cloud". Il s'agit d'une philosophie architecturale qui rapproche le traitement des données de leur source de création, afin de réduire la latence et la dépendance à une connexion réseau permanente.
Cette approche est une réponse directe aux besoins des applications modernes qui exigent des réponses en temps réel, chose que l'aller-retour systématique vers un serveur distant ne peut tout simplement pas garantir de manière fiable.
Pourquoi l'IA s'y installe ?
La convergence entre l'IA et l'Edge n'est pas un hasard, mais une nécessité technique et business. Les modèles d'inférence, c'est-à-dire l'utilisation d'un modèle déjà entraîné pour faire une prédiction, sont de plus en plus optimisés pour fonctionner sur des processeurs à faible consommation.
Les avantages de cette décentralisation sont multiples et répondent à des problématiques très concrètes :
- Latence quasi-nulle : Pour une voiture autonome qui doit détecter un obstacle ou un bras robotique sur une chaîne de montage, la décision doit être instantanée. Attendre une réponse du Cloud est inenvisageable.
- Souveraineté et confidentialité des données : Traiter les données localement, comme les images d'une caméra de surveillance intelligente, évite de les envoyer sur des réseaux publics, renforçant ainsi drastiquement la sécurité et le respect de la vie privée.
- Fiabilité hors-ligne : Une usine connectée ou un champ agricole utilisant des drones ne peut pas cesser de fonctionner à cause d'une coupure internet. L'IA embarquée assure la continuité des opérations.
- Économie de bande passante : Envoyer des flux vidéo en continu vers le Cloud est extrêmement coûteux. Analyser ces flux en local et n'envoyer que les métadonnées pertinentes (comme une alerte) divise les coûts par cent, voire par mille.
Les contraintes inhérentes à la périphérie
Déployer à la périphérie est cependant un monde radicalement différent du confort prévisible du Cloud. Les ressources ne sont pas élastiques, l'environnement est souvent hostile et la diversité matérielle est la norme, non l'exception.
Pour mieux visualiser ce fossé, comparons les deux environnements sur quelques critères clés :
| Critère | Environnement Cloud | Environnement Edge |
|---|---|---|
| Ressources de calcul | Pratiquement illimitées, scalables à la demande. | Fortement contraintes (CPU, RAM, stockage). |
| Connectivité réseau | Très haute disponibilité, faible latence interne. | Intermittente, faible bande passante, parfois inexistante. |
| Hétérogénéité | Homogène, standardisé par le fournisseur de Cloud. | Extrêmement hétérogène (ARM, x86, GPU, TPU...). |
| Sécurité physique | Très élevée, accès contrôlé aux datacenters. | Faible, les appareils peuvent être volés ou altérés. |
| Maintenance | Gérée par le fournisseur, abstraite pour l'utilisateur. | Déploiement physique, mises à jour OTA (Over-The-Air). |
Le MLOps à l'épreuve de la Périphérie : Une nouvelle discipline
Le MLOps traditionnel vise à automatiser et industrialiser le cycle de vie des modèles de Machine Learning, un peu comme le DevOps le fait pour le logiciel. Il s'agit de créer des pipelines reproductibles pour l'entraînement, les tests, le déploiement et la surveillance des modèles.
Quand on applique ces principes à l'Edge, la complexité explose. Le pipeline doit non seulement gérer le modèle en lui-même, mais aussi sa distribution et son cycle de vie sur une flotte d'appareils distants, tout en tenant compte de leurs contraintes spécifiques.
L'architecture d'un pipeline MLOps pour le Edge
Un flux de travail MLOps pour l'Edge est fondamentalement hybride. Il combine la puissance du Cloud pour les tâches lourdes et l'agilité de l'Edge pour l'inférence. Le véritable enjeu est la synchronisation et l'orchestration entre ces deux mondes.
Concrètement, le cycle de vie complet se décompose en plusieurs étapes clés, qui forment une boucle de rétroaction continue entre le centre et la périphérie. Visualisons ce flux pour mieux en saisir la dynamique.
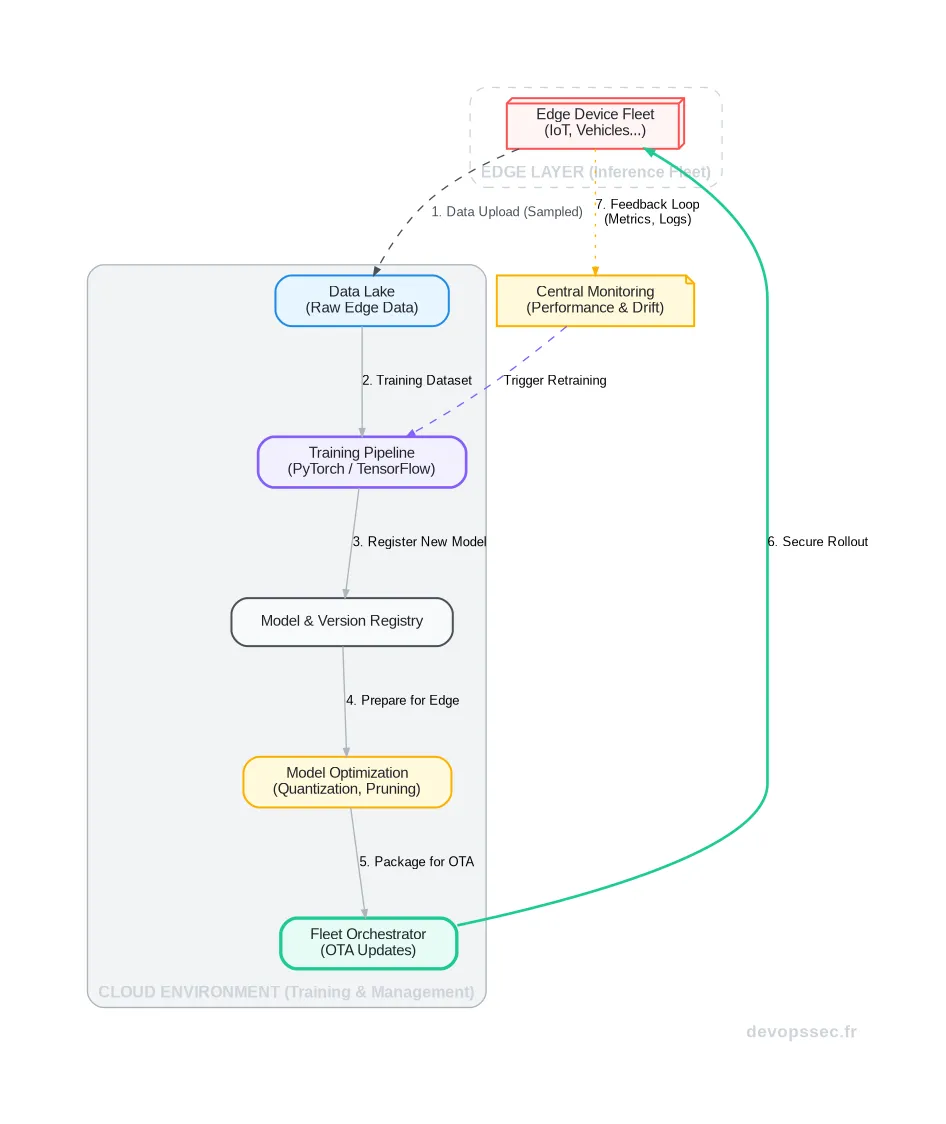
Ce schéma illustre bien la séparation des rôles. Le Cloud reste le cerveau de l'opération, là où les données sont analysées et les modèles sont créés. La périphérie, quant à elle, devient le bras armé, exécutant les modèles de manière autonome pour une réactivité maximale.
Déploiement et Orchestration : Le cœur du réacteur
Une fois le modèle optimisé (par exemple, converti au format TensorFlow Lite ou ONNX), comment le pousser de manière fiable et sécurisée sur des milliers d'appareils ? C'est le travail de l'orchestrateur de flotte. Des outils comme Kubernetes étendu à la périphérie avec KubeEdge, ou des services managés comme AWS IoT Greengrass et Azure IoT Edge, sont conçus pour cela.
Ils permettent de définir des déploiements de manière déclarative, en ciblant des groupes d'appareils selon leurs capacités matérielles ou leur localisation géographique. Voici à quoi pourrait ressembler un manifeste de déploiement très simplifié pour un orchestrateur fictif.
apiVersion: edge.mloops.io/v1
kind: ModelDeployment
metadata:
name: anomaly-detector-v2
spec:
# Selector to target devices with specific labels
targetFleet:
labels:
- "hardware:gpu-enabled"
- "location:factory-floor-A"
# The optimized model to deploy
model:
registry: my-registry/models
name: anomaly-detector
version: "2.1.0-quantized"
# Runtime configuration
runtime:
name: "TFLiteRuntime"
# Resource constraints for the device
resources:
limits:
cpu: "500m"
memory: "256Mi"
# Rollout strategy to avoid breaking the entire fleet
strategy:
type: "Canary"
canary:
steps:
- setWeight: 10
- pause: { duration: 15m }
- setWeight: 100Ce fichier YAML décrit non seulement le modèle à déployer, mais aussi sur quel type d'appareil le faire, avec quelles limites de ressources, et selon une stratégie de déploiement progressive (Canary) pour limiter les risques en cas de problème.
La sécurité et les coûts cachés : Le revers de la médaille
Toute cette puissance distribuée s'accompagne de nouveaux risques et de coûts qu'il faut anticiper. Décentraliser l'intelligence, c'est aussi décentraliser la surface d'attaque. La sécurité n'est plus seulement une affaire de pare-feu et de contrôle d'accès réseau.
[Ne sous-estimez jamais la sécurité physique]
Un appareil en périphérie peut être physiquement accessible. Un attaquant pourrait tenter d'extraire le modèle de la mémoire, de le modifier (empoisonnement), ou d'utiliser l'appareil comme une porte d'entrée vers le reste du réseau. La signature des modèles, le chiffrement du stockage et l'attestation matérielle (TPM) ne sont pas des options, mais des prérequis.
Au-delà de la sécurité, la gestion d'une flotte a un coût opérationnel non négligeable. La logistique des mises à jour Over-The-Air (OTA), la gestion des batteries, le remplacement du matériel défaillant et la surveillance de milliers de points de terminaison demandent des outils et des compétences spécifiques qui vont bien au-delà du déploiement logiciel.
L'Observabilité : Le radar de votre flotte de modèles
Dans le Cloud, si une application tombe, vous avez des logs centralisés et des métriques à portée de main. Mais comment savoir si un modèle de détection de défauts sur une machine au fin fond d'une usine commence à perdre en précision ? C'est le défi de l'Observabilité à la périphérie.
Il ne s'agit pas seulement de remonter des erreurs, mais de collecter des signaux faibles permettant de comprendre le comportement du modèle et de l'appareil dans leur environnement réel. C'est essentiel pour détecter la "dérive", ce phénomène où le modèle devient progressivement moins performant car les données qu'il rencontre dans la réalité s'éloignent de celles sur lesquelles il a été entraîné.
- Métriques du modèle : Suivre la distribution des prédictions, les scores de confiance. Si un modèle ne prédit soudainement plus qu'une seule classe, c'est un signal de problème.
- Métriques système : L'utilisation du CPU, de la RAM et la température de l'appareil. Une surchauffe peut dégrader les performances du modèle de manière silencieuse.
- Métriques de données d'entrée : Analyser les caractéristiques des données en entrée pour détecter les dérives (par exemple, si la luminosité moyenne des images change drastiquement).
La clé est de le faire intelligemment, en agrégeant les données sur l'appareil et en n'envoyant que des synthèses ou des alertes pour ne pas saturer des connexions réseau souvent limitées et coûteuses.
Conclusion : Vers une intelligence ambiante et maîtrisée
Le MLOps à la Périphérie est bien plus qu'une simple extension du MLOps traditionnel. C'est une discipline à part entière, au carrefour de l'ingénierie des systèmes embarqués, de l'infrastructure distribuée, de la sécurité et de la science des données.
Pour nous, ingénieurs DevOps, c'est une formidable opportunité de monter en compétence et de nous positionner au cœur de l'innovation. Maîtriser le déploiement, l'orchestration et la surveillance de l'IA dans le monde réel est une compétence qui devient chaque jour plus critique.
Le chemin est complexe, les outils sont encore en pleine maturation, mais le jeu en vaut la chandelle. Car c'est à la périphérie que l'intelligence artificielle tiendra véritablement ses promesses : devenir une aide ambiante, contextuelle et instantanée dans notre quotidien.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
25 commentaires
N'oubliez jamais que l'Edge, c'est avant tout de la contrainte. Si vous ne pouvez pas automatiser le rollback, ne déployez pas.
Un simple script bash qui tape dans
/sys/class/thermal/fait le taf.Si ça dépasse 80°C, tu réduis la fréquence d'inférence.
Quelle est la meilleure façon de monitorer la température CPU pour éviter le throttling ?
Désactive les ports USB au niveau du BIOS/firmware ou utilise de la colle forte. Le hardware c'est du code, faut le sécuriser pareil.
La sécurité physique est le point faible du Edge. Si quelqu'un branche un clavier sur mon port USB, c'est fini.
On utilise
Helmavec des valeurs injectées dynamiquement selon le type d'appareil.C'est simple et ça permet de gérer les versions proprement.
Merci pour le manifeste
ModelDeployment, c'est très clair.Vous utilisez quel moteur de template pour générer ça côté CI/CD ?
C'est mature. La plupart des runtimes comme
ONNX Runtimesont très stables.C'est devenu le standard pour éviter le lock-in avec TensorFlow ou PyTorch.
Tu parles du format ONNX, c'est vraiment prêt pour la prod ou c'est encore de la bidouille ?
Tu ne peux pas réentraîner sur l'Edge. On surveille la distribution des entrées.
Si les stats d'entrée divergent trop de celles du set d'entraînement, on déclenche une alerte pour forcer une mise à jour du modèle depuis le Cloud.
Comment tu gères la dérive des données (data drift) sans entraîner le modèle sur l'appareil ?
Pour des microcontrôleurs, oui, c'est trop lourd. KubeEdge c'est pour des gateways industrielles.
Si tu as moins de 512Mo de RAM, oublie Kubernetes et passe sur des scripts
systemdavec une registry locale.Je bosse avec KubeEdge. C'est pas un peu une usine à gaz pour des petits capteurs ?
Un déploiement sans limites de ressources sur un CPU ARM limité.
Le modèle a bouffé toute la RAM, le kernel a déclenché le OOM Killer, et l'appareil est devenu une brique physique. Toujours définir des limites.
C'est quoi la pire erreur que tu as vue sur un déploiement Edge ?
Utilise un système de fichiers
read-onlypour le système et une partition dédiéeoverlayfspour les modèles.Ça évite de corrompre tout l'OS en cas de crash.
Et pour le stockage des modèles sur l'appareil ?
Tu recommandes quoi comme format pour éviter la corruption sur les coupures de courant brutales ?
Pour la signature, ne réinvente pas la roue. Utilise
Cosignou des solutions de gestion de clés matérielles (TPM).L'idée est que le runtime vérifie le hash avant de charger le fichier dans la RAM.
Quels outils tu recommandes pour gérer la signature des modèles ?
J'ai déjà vu des gens faire des trucs horribles avec du
opensslmal configuré.C'est pour ça qu'on ne stream jamais les données brutes.
On fait de l'agrégation locale avec un petit agent qui envoie uniquement des résumés statiques via
PrometheusouMQTT. Le reste, c'est du bruit.L'observabilité dont tu parles est un enfer à scaler. Envoyer des métriques depuis 5000 capteurs en 4G, ça coûte une fortune.
Le rollback doit être atomique au niveau du filesystem.
On utilise souvent une partition A/B. Si le nouveau modèle ne passe pas les tests de santé au démarrage, le bootloader
U-Bootbascule automatiquement sur l'ancienne version.Le YAML de déploiement montre une stratégie Canary. Comment tu gères le rollback si l'appareil perd le réseau juste après le push ?
Tu touches le point sensible. Le MLOps à l'Edge c'est 20% de ML et 80% de gestion d'OS embarqué.
Si ton runtime
TFLiteRuntimeest instable, c'est souvent un problème de gestion des ressources kernel. Il faut isoler le processus avec descgroupsstricts.Article intéressant, mais on fait quoi quand le link
/dev/ttyou le bus I2C est instable sur le terrain ?Le MLOps à l'Edge c'est bien, mais si l'OS plante avant même de charger le modèle c'est mort.