L'Ère des Tests Auto-Évolutifs : Quand l'IA Réécrit la Qualité DevOps
Vous avez déjà ressenti cette frustration ? Pousser une modification de code minime, et voir le pipeline CI/CD s'allumer en rouge à cause d'un test qui échoue sans raison apparente. Cette époque, où la qualité logicielle était un goulot d'étranglement réactif, est en train de s'achever.
Nous entrons dans une phase fascinante où l'assurance qualité n'est plus une simple vérification, mais une collaboration intelligente et proactive. L'intelligence artificielle ne se contente plus d'analyser des données elle s'intègre au cœur de nos processus pour générer, réparer et optimiser nos stratégies de test en temps réel.
Oubliez les suites de tests monolithiques et fragiles. Imaginez plutôt un système de tests vivant, qui apprend de chaque commit, de chaque déploiement et de chaque interaction utilisateur pour renforcer continuellement la résilience de vos applications. C'est la promesse des Tests Auto-Évolutifs.
Anatomie d'un Pipeline de Test Augmenté par l'IA
Pour bien comprendre cette révolution, il faut revenir aux fondations. Le pipeline CI/CD, ou Intégration et Déploiement Continus, est l'autoroute automatisée qui prend le code d'un développeur pour le livrer en production. Traditionnellement, les tests y forment une série de péages, des points de contrôle statiques qui valident la qualité à chaque étape.
L'IA vient transformer ces péages en postes d'aiguillage intelligents. Au lieu de simplement exécuter une liste prédéfinie de vérifications, le système analyse le contexte du changement pour orchestrer une stratégie de test dynamique, parfaitement adaptée à la situation.
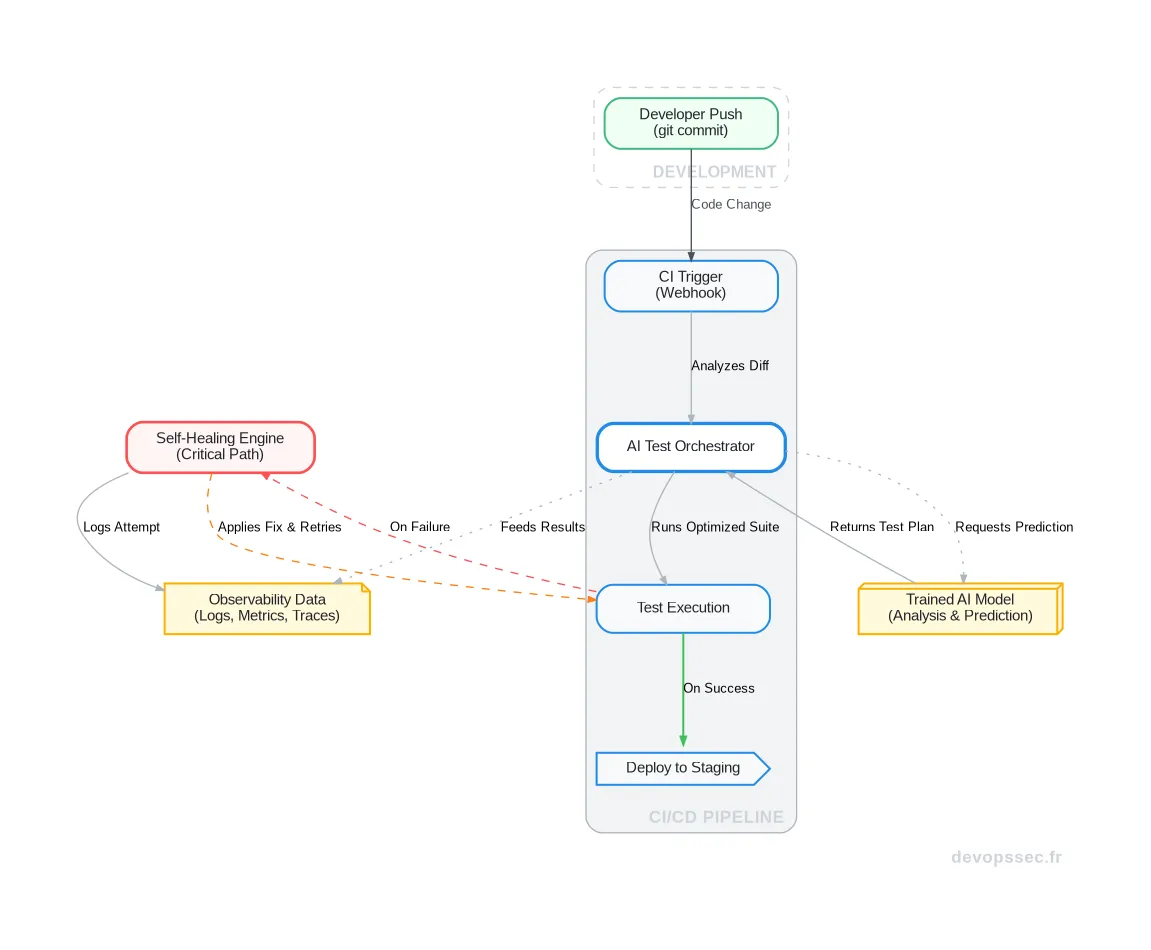
Ce schéma illustre parfaitement le nouveau rôle central de l'IA. L'orchestrateur ne se contente pas d'exécuter des tests, il dialogue avec un modèle prédictif. Il analyse le code source, identifie les risques, puis commande une suite de tests sur mesure avant de décider de la marche à suivre, y compris la réparation autonome en cas d'échec.
La Génération Automatique de Cas de Test
Le premier super-pouvoir de ce nouveau paradigme est la capacité de l'IA à écrire des tests. En analysant le "diff", c'est-à-dire les lignes de code qui ont été ajoutées ou modifiées, le modèle est capable de comprendre l'intention du développeur et de générer des tests pertinents.
Concrètement, l'IA ne se contente pas de viser une couverture de code de 100%. Elle va plus loin en se basant sur les données d'utilisation réelles (issues de votre plateforme d'observabilité) pour créer des scénarios de tests qui miment le comportement de vos utilisateurs, couvrant ainsi les "happy paths" comme les cas les plus tordus.
Imaginez un fichier de configuration pour votre pipeline où vous activez cette fonctionnalité. La syntaxe pourrait ressembler à ceci, définissant les stratégies de génération à appliquer.
# .gitlab-ci.yml
stages:
- test
ai_augmented_tests:
stage: test
image: test-runner:latest
script:
- run-test-suite --enable-ai
rules:
- if: $CI_MERGE_REQUEST_IID
ai_testing_config:
generation_strategy: 'diff_and_usage_based'
# Niveaux : 'critical_path', 'full', 'exploratory'
coverage_level: 'critical_path'
# Le moteur IA tentera jusqu'à 2 fois de réparer un test qui échoue
self_healing_attempts: 2Le Self-Healing : La Fin des Tests Flaky ?
Parlons maintenant du fléau des équipes DevOps : les tests "flaky" ou instables. Ces tests échouent de manière intermittente sans aucune raison logique, polluant les résultats et érodant la confiance dans le processus de qualité. Le Self-Healing, ou auto-réparation, est la réponse de l'IA à ce problème.
Lorsqu'un test d'interface utilisateur (End-to-End) échoue parce qu'un sélecteur CSS a changé suite à un refactoring, l'ancienne méthode consistait à créer un ticket pour qu'un développeur le corrige manuellement. Aujourd'hui, le moteur de Self-Healing intervient instantanément.
Il analyse le DOM de la page, compare l'ancien sélecteur avec la nouvelle structure, et en déduit le nouveau chemin d'accès correct. Il met alors à jour le test à la volée, le relance pour confirmer la correction, et consigne l'opération. La boucle est bouclée en quelques secondes, sans intervention humaine.
| Caractéristique | Approche Traditionnelle | Approche Self-Healing |
|---|---|---|
| Détection de l'échec | Rapport de test rouge dans le pipeline | Rapport de test orange (échec initial) |
| Analyse de la cause | Manuelle, par un ingénieur QA ou un développeur | Automatique, par analyse de logs et du contexte (DOM, API) |
| Temps de résolution | De quelques minutes à plusieurs heures | Quelques secondes |
| Impact sur le pipeline | Blocage complet du déploiement | Micro-ralentissement, puis reprise automatique |
L'Optimisation Continue : Tester Mieux, Pas Forcément Plus
L'ajout de l'intelligence artificielle ne signifie pas simplement empiler plus de tests. Au contraire, l'un des bénéfices les plus importants est l'optimisation. Le but est d'atteindre une confiance maximale dans la qualité du logiciel avec un effort de test minimal.
C'est ici qu'intervient le concept de Test Impact Analysis (TIA). Grâce à une cartographie précise des dépendances dans le code, l'IA sait exactement quelles parties de l'application sont affectées par une modification. Elle ne lance alors que le sous-ensemble de tests strictement nécessaire pour valider ce changement.
Le résultat est spectaculaire. Des pipelines qui prenaient autrefois 45 minutes pour exécuter des milliers de tests peuvent voir leur durée réduite à moins de 5 minutes, tout en maintenant, voire en améliorant, le niveau de confiance dans la livraison.
Les Limites et les Coûts Cachés de l'IA-Driven Testing
Adopter cette technologie n'est cependant pas une solution magique. Il est crucial d'être conscient des contreparties et des nouveaux défis qu'elle introduit. La première considération est le coût computationnel. Entraîner et faire tourner des modèles d'IA, même spécialisés, demande une puissance de calcul non négligeable qui peut se traduire par une augmentation de votre facture cloud.
Ensuite, il y a le risque de la "boîte noire". Si une IA répare un test de manière incorrecte ou génère des tests peu pertinents, il peut être complexe de diagnostiquer l'origine du problème. Une supervision humaine et des mécanismes de validation restent indispensables pour maintenir la confiance dans le système.
Enfin, la sécurité des modèles IA devient un enjeu majeur. Un modèle d'IA compromis pourrait être manipulé pour ignorer délibérément des tests de sécurité critiques ou, pire, pour suggérer des corrections de code qui introduisent de nouvelles vulnérabilités. La gouvernance et la surveillance de ces modèles sont donc aussi importantes que leur performance.
Notre conseil pour bien démarrer
Ne cherchez pas à tout automatiser d'un coup. Commencez par appliquer l'IA sur un périmètre restreint et bien compris, comme le Self-Healing pour vos tests End-to-End les plus instables. Mesurez le gain de temps et de fiabilité, puis étendez progressivement son champ d'action.
Conclusion : Vers une Qualité Proactive
Nous sommes à un point de bascule. La qualité logicielle n'est plus une discipline qui cherche à trouver des bugs après coup, mais une force proactive qui anticipe les risques et renforce la résilience du code avant même qu'il ne soit écrit.
L'objectif ultime de cette synergie entre DevOps et IA n'est pas de remplacer les ingénieurs qualité. Il s'agit de les augmenter, de leur retirer les tâches répétitives et à faible valeur ajoutée pour qu'ils puissent se concentrer là où l'intelligence humaine excelle : la créativité, l'exploration de cas limites et la compréhension profonde de l'expérience utilisateur.
En intégrant des systèmes de tests auto-évolutifs, nous ne faisons pas que livrer du code plus vite. Nous construisons des fondations logicielles plus robustes, plus sécurisées et, finalement, plus fiables, pour bâtir les applications de demain.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
C'est exactement ce qui arrive. On travaille sur des plugins qui font le pont entre le moteur IA et les runners que tu cites pour éviter de sortir du flux habituel.
Pour moi, le vrai gain serait d'intégrer ça directement dans
jestoucypress, pas via un outil externe qui rajoute de la latence.Pas forcément. Dans une équipe de 50 personnes, tu ne contrôles pas chaque commit. Le
self_healingest une assurance, pas une excuse pour coder comme un cochon.En gros, tu vends une solution pour corriger des tests qui sont mal écrits dès le départ ? Si tes sélecteurs CSS changent tout le temps, t'as un souci de design system, pas de pipeline.
On utilise des modèles locaux ou des instances privées. Rien ne sort de notre infra. C'est la base pour éviter le leak de ton code source vers des tiers.
Je rejoins le 9. Qui audite le modèle ? C'est quoi la gouvernance derrière ces choix d'auto-réparation ?
Le jour où le modèle d'IA est corrompu et ignore un test de sécurité, on sera bien avancés. La sécurité des modèles est un point trop survolé dans ton article.
Tiens, voilà à quoi ressemble une sortie de log typique quand le moteur détecte un changement de sélecteur :
Est-ce qu'on peut voir un exemple concret de log quand l'IA répare un test ? Parce que là c'est très théorique.
C'est vrai, l'IA ne remplace pas une bonne gestion de contrats API. Mais ça aide sur 80% des petits changements d'UI qui polluent nos pipelines.
Le
self_healingsur le DOM, c'est bien gentil, mais si ton backend change son contrat API, l'IA ne pourra rien faire. C'est du maquillage de façade.J'ai essayé un truc similaire. Au début c'est beau, mais dès que tu changes un peu ton architecture micro-services, l'IA devient folle et génère des tests totalement hors-sujet.
Parce que le TIA classique est statique et devient vite obsolète. L'IA apprend des dépendances réelles et du comportement utilisateur, ce que tes outils de coverage ne voient jamais.
Le
Test Impact Analysisexiste depuis des lustres sans IA. On faisait ça avec des outils de couverture de code classiques. Pourquoi tout mettre sur le dos de l'IA ?Et le coût computationnel ? Tu as calculé combien ça consomme en GPU sur le long terme pour analyser chaque
diffà chaque commit ? C'est une usine à gaz pour des gains marginaux.L'IA ne génère pas du code binaire, elle génère des scripts. Tu peux auditer le résultat. L'objectif est de réduire la charge cognitive du dev, pas de lui enlever le contrôle.
Exactement. On a déjà assez de mal avec les
flaky testsclassiques sans ajouter une couche d'IA non déterministe par-dessus. Gérer l'état est un enfer, pourquoi complexifier ça ?Le problème c'est la boîte noire. Comment tu débugues un test généré par IA qui échoue aléatoirement ? Si je ne peux pas lire le code du test, je ne peux pas faire confiance à la suite.
C'est pour ça que la stratégie n'est pas de laisser l'IA décider seule. On garde des garde-fous. Le
self_healingne remplace pas la review, il évite juste de bloquer le pipeline pour un sélecteur qui a bougé de deux div.Encore un article qui vend du rêve avec l'IA. Tu parles de
self_healing_attemptsdans ton.gitlab-ci.yml, mais concrètement, si ton IA répare mal un test UI, tu te retrouves avec un faux positif massif en prod. C'est dangereux.