L'illusion de la performance réseau standard
Un million de paquets par seconde sur un seul cœur processeur. C'est le mur invisible auquel se heurtent la plupart des applications réseau traditionnelles lorsqu'elles tentent de traiter du trafic massif. Dans une architecture classique, la carte réseau réceptionne une trame, déclenche une interruption matérielle, puis le noyau Linux alloue frénétiquement une structure complexe appelée sk_buff. Cette structure doit ensuite traverser des dizaines de couches logicielles, du pare-feu aux protocoles de transport, avant d'être finalement recopiée dans l'espace mémoire de votre application. Ce ballet incessant d'allocations mémoire et de changements de contexte entre l'espace noyau et l'espace utilisateur consomme des cycles processeurs précieux, transformant votre serveur surpuissant en un simple goulot d'étranglement.
Pour des environnements critiques comme le trading haute fréquence, la protection anti-DDoS ou les routeurs logiciels virtuels, cette latence induite par le système d'exploitation est inacceptable. C'est ici qu'intervient une rupture technologique majeure : le socket AF_XDP. Il ne s'agit pas d'une simple optimisation du noyau, mais d'un changement de paradigme radical. L'idée est de court-circuiter l'intégralité de la pile réseau Linux pour livrer la donnée brute, à la vitesse de l'éclair, directement depuis le pilote de la carte réseau jusqu'à votre code. En éliminant les intermédiaires, on redonne au processeur sa mission première : exécuter votre logique métier et non faire le facteur.
Les fondements d'AF_XDP et l'architecture du contournement
Pour comprendre l'intérêt de ce mécanisme, il faut remonter à ses origines. AF_XDP a été conçu pour s'intégrer nativement à eBPF (Extended Berkeley Packet Filter), une technologie qui permet d'exécuter du code sécurisé directement dans le noyau Linux sans en modifier le code source. Historiquement, les solutions de contournement de noyau exigeaient de remplacer les pilotes matériels par des modules propriétaires complexes. Avec AF_XDP, Linux propose enfin un standard officiel et maintenu en amont pour capturer les paquets dès leur arrivée sur la carte réseau (XDP signifie eXpress Data Path), bien avant qu'ils ne touchent le reste de la pile réseau.
Les prérequis pour exploiter cette puissance sont stricts mais devenus la norme sur les serveurs modernes. Il vous faut un noyau Linux supérieur ou égal à la version 4.18, bien que la version 5.4+ soit fortement recommandée pour bénéficier du support complet du mode Zéro-Copie (Zero-Copy). Votre carte réseau doit également disposer d'un pilote compatible XDP natif. Si ce n'est pas le cas, le système basculera en mode générique (SKB mode), ce qui annule la quasi-totalité des gains de performance, car le noyau continuera d'allouer de la mémoire en arrière-plan avant de transférer les paquets à XDP.
Anatomie d'un bypass chirurgical
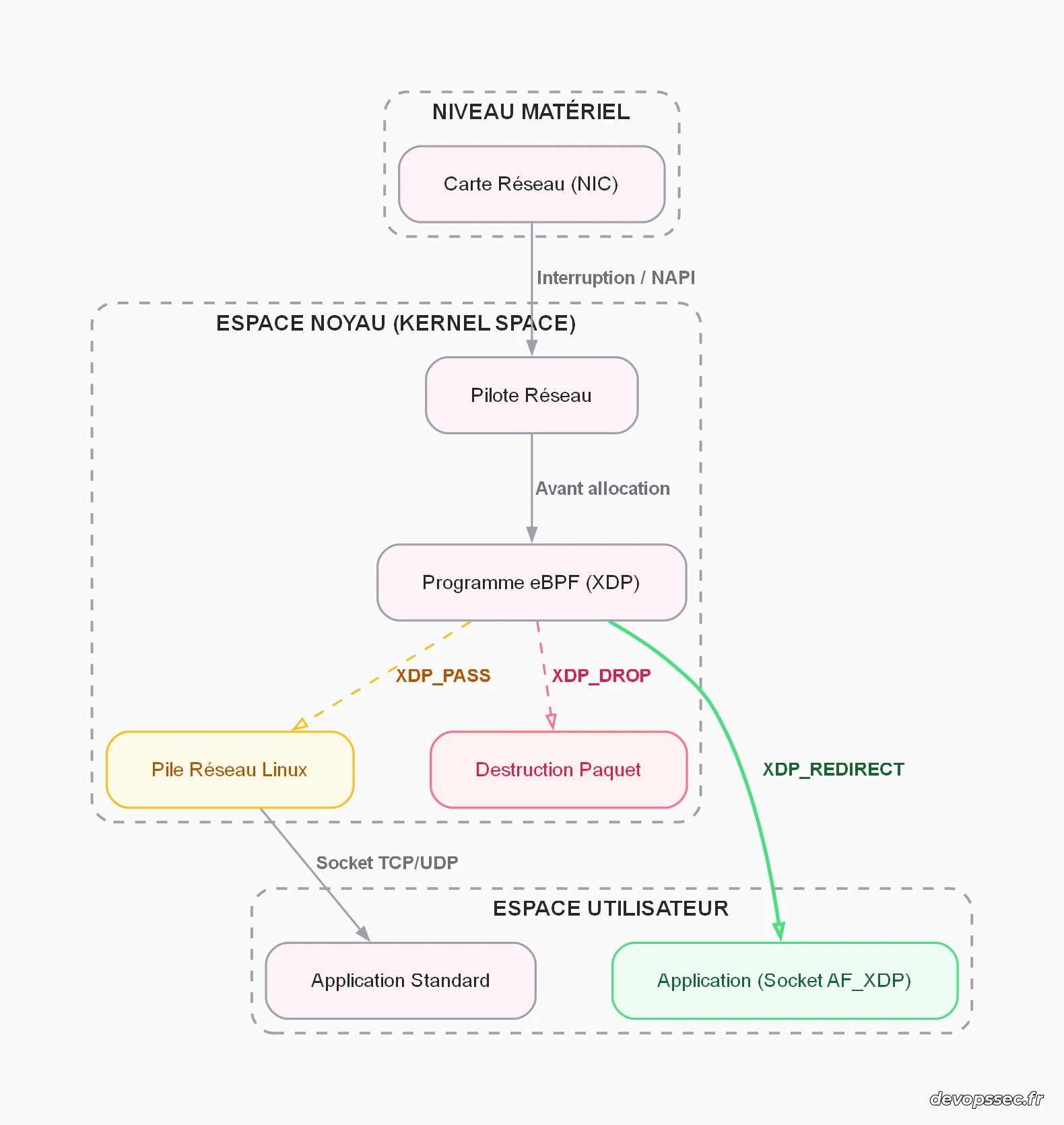
Ce schéma illustre la position stratégique du programme eBPF. Lorsqu'un paquet arrive sur la carte réseau, le pilote passe la main à notre petit programme eBPF avant même d'informer la pile réseau Linux. Ce programme agit comme un aiguilleur intraitable. Il lit les en-têtes du paquet et prend une décision instantanée. S'il renvoie le code de retour XDP_PASS, le paquet poursuit son chemin classique vers la pile réseau standard. S'il détecte un trafic malveillant, il renvoie XDP_DROP et le paquet est purement et simplement désintégré, offrant une protection anti-DDoS d'une redoutable efficacité. Enfin, la magie opère avec XDP_REDIRECT : le paquet est instantanément dévié vers notre socket AF_XDP dans l'espace utilisateur, sans jamais avoir été copié.
Configuration système et validation matérielle
Avant d'écrire la moindre ligne de code, il est impératif de s'assurer que l'environnement est apte à encaisser la charge. Le principal ennemi de la performance réseau est la migration des processus d'un cœur CPU à un autre. Vous devez épingler la file de réception matérielle (Receive Queue) de la carte réseau sur le même cœur CPU qui exécutera votre application AF_XDP.
Pour vérifier si votre carte réseau supporte le mode natif, vous pouvez interroger le système via la commande ethtool. L'objectif est de repérer les fonctionnalités liées à XDP. Assurez-vous également de désactiver le déchargement matériel du routage (LRO) ou le filtrage qui pourrait segmenter les paquets avant qu'XDP ne puisse les lire proprement.
Désactivation des optimisations antagonistes
Le mode "Generic Receive Offload" (GRO) ou "Large Receive Offload" (LRO) mis en place par défaut sur beaucoup d'interfaces réseau regroupe les paquets pour soulager la pile TCP/IP. Cependant, ces mécanismes sont totalement incompatibles avec XDP qui requiert l'accès au paquet brut tel qu'il est sur le fil de cuivre. Il faut impérativement les désactiver avec ethtool sous peine d'échec de chargement de votre programme eBPF.
UMEM et la mécanique des anneaux de mémoire

Au cœur de l'efficacité d'AF_XDP se trouve l'UMEM. Pour le vulgariser, imaginez l'UMEM comme un vaste terrain de stockage partagé entre le pilote de la carte réseau (dans le noyau) et votre application (dans l'espace utilisateur). Au lieu de se passer les colis de main en main, les deux entités se contentent de s'échanger des fiches cartonnées indiquant l'emplacement exact d'un colis sur le terrain. L'application réserve une large plage de mémoire continue lors de son lancement, puis l'enregistre auprès du noyau. Dès lors, la carte réseau écrit les données entrantes directement dans cette zone mémoire, évitant ainsi la fameuse pénalité de copie. La coordination de ce ballet logistique s'effectue via des structures d'attente circulaires très rapides appelées Ring Buffers.
Les deux acteurs (noyau et utilisateur) manipulent ces anneaux via des opérations de production et de consommation. Pour garantir une exécution sans verrou (lock-free) et donc sans latence, chaque anneau a un unique producteur et un unique consommateur. C'est l'architecture logicielle parfaite pour saturer le bus PCI Express sans jamais mettre un processus en attente.
Les quatre anneaux de la performance
L'architecture complète repose sur quatre anneaux distincts qui gèrent le cycle de vie complet d'un espace mémoire, de sa mise à disposition jusqu'à son recyclage. La maîtrise de ces quatre files est indispensable pour coder un programme stable qui ne fuit pas de la mémoire ou ne se retrouve pas paralysé par manque d'espace.
| Nom de l'anneau | Producteur | Consommateur | Rôle exact dans le cycle de vie |
|---|---|---|---|
| FILL Ring | Espace Utilisateur | Noyau (Pilote NIC) | L'application dépose les adresses mémoires vides disponibles pour que la carte réseau puisse y écrire les nouveaux paquets. |
| RX Ring | Noyau (Pilote NIC) | Espace Utilisateur | Le noyau dépose les adresses mémoires contenant les paquets fraîchement reçus. L'application y lit la taille et le contenu de la trame. |
| TX Ring | Espace Utilisateur | Noyau (Pilote NIC) | L'application dépose les adresses mémoires des paquets qu'elle a générés ou modifiés pour demander à la carte réseau de les expédier. |
| COMPLETION Ring | Noyau (Pilote NIC) | Espace Utilisateur | Le noyau confirme que l'envoi physique est terminé sur le fil. L'application sait alors qu'elle peut recycler cet espace mémoire dans le FILL Ring. |
Si votre application est trop lente pour traiter le RX Ring, la carte réseau se retrouvera rapidement à court d'adresses disponibles dans le FILL Ring. Elle commencera alors à écraser silencieusement les paquets entrants (drop matériel). C'est pourquoi la boucle d'interrogation (polling) de l'espace utilisateur doit être implémentée en C, C++ ou Rust, avec une attention maniaque portée à la prédiction de branchement et à la localité des données dans le cache L1 du processeur.
Implémentation haute performance en production
L'implémentation complète nécessite l'écriture de deux programmes qui vont se parler en permanence : le code eBPF injecté dans le noyau, et le daemon en espace utilisateur qui récupère la charge. Nous allons ici nous concentrer sur une configuration optimisée orientée réception. L'objectif de notre programme BPF est simpliste mais redoutable : intercepter le trafic d'une file matérielle spécifique et l'envoyer aveuglément dans le socket de notre application via une structure de données spéciale appelée BPF_MAP_TYPE_XSKMAP.
La déclaration de la map est cruciale. Elle lie un identifiant matériel (l'index de la file de la carte réseau) au descripteur de fichier de notre socket AF_XDP. C'est le point de jonction entre les deux mondes. Sans cette table de correspondance, le noyau ne saurait pas dans quel canal privé jeter le paquet intercepté.
Le programme eBPF : l'aiguilleur du ciel
Voici un exemple de code eBPF, compilé via clang vers une cible BPF. Notez l'utilisation de la macro SEC qui définit dans quelle section du binaire ELF le chargeur libbpf devra chercher le programme. Le code se contente de lire l'index de la file de réception, de chercher s'il existe un socket lié à cette file, et d'exécuter la fonction de redirection.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
/* Déclaration de la map liant la file matérielle au socket AF_XDP */
struct {
__uint(type, BPF_MAP_TYPE_XSKMAP);
__uint(max_entries, 64);
__type(key, int);
__type(value, int);
} xsks_map SEC(".maps");
SEC("xdp")
int xdp_redirect_to_socket(struct xdp_md *ctx)
{
/* On récupère le numéro de la file (queue) par laquelle le paquet est entré */
int index = ctx->rx_queue_index;
/* On vérifie si notre application écoute sur cette file spécifique */
if (bpf_map_lookup_elem(&xsks_map, &index)) {
/* Redirection immédiate, bypass total de la pile noyau */
return bpf_redirect_map(&xsks_map, index, 0);
}
/* Si aucun socket n'est branché, on laisse passer le trafic au noyau */
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";L'appel à bpf_redirect_map est le cœur du réacteur. Cette fonction de l'API eBPF est extrêmement optimisée en interne. Elle transfère la gestion du descripteur de paquet du contexte XDP directement vers le pointeur de l'UMEM assigné à la file en question. Ce code est injecté au niveau de la carte réseau via des appels système. Si le pilote matériel est compatible, l'instruction est traduite en langage machine natif via un compilateur JIT (Just-In-Time) directement dans le noyau.
L'espace utilisateur : consommer sans allouer
Du côté de l'application, l'initialisation est longue et fastidieuse car il faut allouer l'UMEM en mode aligné sur les pages systèmes, mmapper (monter en mémoire) les anneaux partagés et lier le socket. Je vais éluder le processus de configuration initial (la plomberie) pour me concentrer sur la boucle chaude de réception (le hot path). C'est ici que les performances se gagnent ou se perdent. La boucle lit des lots (batches) de paquets depuis le RX Ring, traite la donnée brute, et renvoie immédiatement l'emplacement mémoire au FILL Ring pour recyclage.
#include <xdp/xsk.h>
void process_network_loop(struct xsk_socket_info *xsk)
{
uint32_t idx_rx = 0;
uint32_t idx_fq = 0;
int rcvd;
while (1) {
/* Consommation depuis le RX Ring (réception par lots de 64 paquets max) */
rcvd = xsk_ring_cons__peek(&xsk->rx, 64, &idx_rx);
if (!rcvd)
continue;
/* Pré-réservation de 64 emplacements vides dans le FILL Ring pour recycler */
xsk_ring_prod__reserve(&xsk->umem->fq, rcvd, &idx_fq);
for (int i = 0; i < rcvd; i++) {
/* Récupération du descripteur réseau */
const struct xdp_desc *desc = xsk_ring_cons__rx_desc(&xsk->rx, idx_rx++);
/* Calcul du pointeur physique vers les octets bruts (Headers + Payload) */
uint64_t addr = desc->addr;
uint32_t len = desc->len;
char *pkt_data = xsk_umem__get_data(xsk->umem->buffer, addr);
/* --- LOGIQUE MÉTIER ICI (ex: parsing IP/UDP, détection de signature) --- */
/* Recyclage : on redonne l'adresse exacte au noyau via le FILL Ring */
*xsk_ring_prod__fill_addr(&xsk->umem->fq, idx_fq++) = addr;
}
/* Validation des pointeurs d'anneaux pour signaler au noyau que le travail est fait */
xsk_ring_cons__release(&xsk->rx, rcvd);
xsk_ring_prod__submit(&xsk->umem->fq, rcvd);
}
}Remarquez l'absence totale de la fonction malloc() ou free() dans cette boucle de traitement. Les paquets sont traités là où ils reposent physiquement en mémoire. Les pointeurs des anneaux (idx_rx et idx_fq) sont simplement incrémentés. Les fonctions de la librairie libxdp agissent comme des barrières mémoires (memory barriers) pour garantir que le processeur ne réorganise pas les instructions, ce qui pourrait amener l'application à lire un paquet avant que la carte réseau n'ait fini de l'écrire.
Observation système et debugging
Lorsqu'on bypass le système d'exploitation, on perd par définition la visibilité des outils standards. Si vous lancez un tcpdump sur votre interface réseau en espérant analyser les paquets déviés par AF_XDP, vous ferez face à un mur de silence. Les trames ont disparu avant d'arriver au point de capture du noyau. Il faut s'appuyer sur l'utilitaire bpftool pour inspecter l'état interne de nos programmes eBPF injectés.
$ bpftool prog showRésultat:
45: xdp name xdp_redirect_to_socket tag a816f5127d gpl
loaded_at 2026-05-25T14:32:01+0000 uid 0
xlated 152B jited 104B memlock 4096B map_ids 12
btf_id 41Ces logs nous confirment que notre programme portant l'identifiant 45 est bien chargé, et surtout, qu'il a été passé à la moulinette JIT (jited 104B). Le champ map_ids 12 indique qu'il communique bien avec notre table de routage matérielle. Si vous constatez des baisses de performance soudaines en production, le premier réflexe est de s'assurer que le driver réseau ne s'est pas mis en défaut et n'a pas basculé l'exécution d'eBPF sur le mode SKB (générique).
La brutalité et la beauté de la mémoire directe
Adopter le socket AF_XDP est un pari architectural lourd de conséquences. C'est accepter d'abandonner le confort ouaté de la pile TCP/IP fournie par Linux, ses algorithmes de contrôle de congestion méticuleusement affinés sur plusieurs décennies, et ses outils de diagnostic universels. Vous vous retrouvez avec une trame Ethernet nue, brute, dont vous devez gérer vous-même le routage, la somme de contrôle (checksum) IP, la reconstitution des paquets fragmentés, et l'acquittement des connexions.
Mais en échange de ce retour à l'âge de pierre du développement réseau, vous obtenez un pouvoir sans égal sur la machine physique. En maîtrisant la gestion asynchrone des Ring Buffers et l'UMEM partagée, une application modeste peut soudainement absorber des millions de trames par seconde sans faire cligner un seul cœur processeur. Le bypass du noyau n'est plus une magie réservée aux laboratoires obscurs des fabricants de cartes réseau : c'est un mécanisme chirurgical intégré et documenté, prêt à décupler les performances de vos infrastructures d'ingestion massive.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Dernier conseil : surveillez bien le
fill_addr. Si vous oubliez de remettre l'adresse dans leFILL Ring, votre application va juste s'arrêter de recevoir des paquets parce qu'elle n'a plus de mémoire disponible pour le NIC.Tu ne peux pas partager un
RX Ringentre plusieurs threads. Un socketAF_XDPest lié à une file unique. Si tu veux du multi-threading, il faut ouvrir un socket par file matérielle et répartir les queues avecRSS.Comment tu gères le recyclage des buffers dans le
FILL Ringsi t'as plusieurs threads qui consomment le même socket ?C'est le résultat normal quand on arrête de traiter le réseau comme un problème de soft pour le traiter comme un problème de flux matériel. Fais gaffe à la chauffe des CPUs maintenant.
Je confirme, le gain est massif. On est passé de 200k pps à 2M pps sur une machine de test. C'est juste indécent.
Parce que le noyau a besoin d'un type spécifique pour gérer les sockets
AF_XDP. C'est pas une simple map, c'est le pont entre le pilote et le socket. C'est là que la magie de la redirection opère.Pourquoi utiliser
BPF_MAP_TYPE_XSKMAPplutôt qu'un simple array ?Exact. Toujours allouer tes buffers
UMEMen tenant compte duMTU+ header L2. Si tu dépasse, c'est le crash assuré en espace utilisateur.On a galéré à cause du
MTU. Si le paquet est plus grand que la zoneUMEM, ça segfault. Faut toujours prévoir une marge dans l'allocation des buffers.C'est une bonne option, mais pour de la très haute perf, le C reste roi pour contrôler l'alignement mémoire et éviter les overheads du runtime. Si tu maîtrises ton
unsafeen Rust, ça passe.Pour les mecs qui font du Rust, y'a
libxdp-rsqui facilite grave la gestion des anneaux. Ça évite de se planter dans lesmemory barriers.Si le socket est fermé, le noyau repasse en mode
XDP_PASSou le programme eBPF échoue, donc le trafic suit le chemin normal. C'est pour ça que ton monitoring doit surveiller le FD du socket.Question bête : si je crash mon daemon user-space, le noyau continue de rediriger le trafic dans le vide ?
Si ton programme eBPF est trop lourd, tu vas exploser le temps d'exécution par paquet. Le noyau va te jeter ton programme direct au chargement. Ton code doit rester brutalement simple : lecture, check, redirect.
C'est quoi l'impact sur la charge CPU si on fait du
XDP_REDIRECTvers un socket, mais qu'on a un programme eBPF complexe à côté ?Passe sur une version 11 ou plus récente. Les macros
__uintet__typesont liées auxBTF(BPF Type Format). Sans ça, ton programme est illisible pour le loaderlibbpf.J'ai essayé de compiler le code eBPF avec une vieille version de
clang, ça a sauté direct. Faut quelle version minimum pour les macros__uint?En prod, on injecte des traces dans un
BPF_MAP_TYPE_PERF_EVENT_ARRAYou on utilisebpf_trace_printksi on est en phase de dev, même si c'est verbeux. Le plus fiable reste de monitorer les compteurs d'erreurs du NIC viaethtool -S.Le code C est propre, mais vous utilisez quoi pour le debug en prod ?
bpftoolc'est bien, mais pour suivre un flux précis dans la map, c'est limité.Tu peux utiliser la même
UMEMpour les deux. L'astuce est de bien gérer tes offsets dans les descripteurs. Par contre, fais gaffe à ne pas réutiliser une adresse avant que leCOMPLETION Ringn'ait confirmé que le NIC a fini d'envoyer le paquet.Petite question sur le
UMEM. Si je veux faire du zero-copy bidirectionnel, je dois avoir deux zones mémoires distinctes ou je peux partager la même entre RX et TX ?Pour ceux qui galèrent avec
ethtool, n'oubliez pas de virer leLROsinon le bpf_prog va juste rejeter le paquet. C'est l'erreur classique qui fait perdre 2h de debug.T'as probablement un souci de
batching. Si tu lis les paquets un par un, tu vas jamais tenir le débit. Il faut traiter par gros blocs dans tonwhile(1)pour minimiser les barrières mémoires. Vérifie aussi si t'as bien épinglé ton processus sur le cœur CPU qui gère la fileIRQ.J'ai testé l'implémentation sur du 100GbE. Le CPU monte en flèche dès que je sature le RX Ring. Une astuce pour éviter le drop matériel quand l'user-space décroche ?
Ouais, c'est une horreur. Le mode
SKBréintroduit la copie mémoire et le passage par la pile réseau standard. Tu perds tout l'intérêt du Zero-Copy. Si t'es enSKB, autant rester sur des sockets classiques, t'auras moins de complexité pour le même résultat médiocre.