Au-delà du Code : L'IA Transforme la Productivité de l'Ingénieur DevOps
Vous est-il déjà arrivé de passer des heures à déboguer un pipeline CI/CD pour une simple erreur de syntaxe ? Ou de vous noyer dans des milliers de lignes de logs pour identifier la cause racine d'un incident en pleine nuit ? Cette charge cognitive, ce "toil" répétitif, est le quotidien de beaucoup d'entre nous. Pourtant, une révolution silencieuse est en marche, transformant radicalement notre métier. L'intelligence artificielle n'est plus un gadget futuriste, mais un véritable co-pilote qui augmente nos capacités à chaque étape du cycle de vie logiciel.
Oubliez l'image de l'IA qui se contente de générer des snippets de code. Nous parlons aujourd'hui d'une assistance intelligente et contextuelle qui analyse, prédit et automatise des tâches complexes, nous libérant ainsi pour nous concentrer sur ce qui a une réelle valeur : l'architecture, l'innovation et la résilience des systèmes. Cet article n'est pas une fiction, c'est le descriptif de votre prochain environnement de travail.
L'IA comme Co-pilote Stratégique : De la Planification au Déploiement
Le cycle de vie DevOps commence bien avant la première ligne de code. Il s'agit d'un flux continu où la planification, le développement, les tests et l'intégration doivent être fluides. L'IA s'immisce dans cette phase "pré-production" pour agir comme un filet de sécurité intelligent et un accélérateur de qualité, réduisant drastiquement les frictions traditionnelles entre les équipes de développement et d'opérations.
Optimisation Intelligente des Pipelines CI/CD
La CI/CD, ou Intégration et Déploiement Continus, est l'autoroute sur laquelle nos applications voyagent de l'ordinateur du développeur jusqu'aux utilisateurs. Le moindre péage défectueux ou embouteillage peut paralyser toute la chaîne de valeur. Historiquement, l'optimisation de ces pipelines était un art empirique, basé sur l'expérience et de longues sessions d'essais-erreurs.
Aujourd'hui, des agents IA analysent en permanence l'historique de vos builds, les temps d'exécution de chaque étape et les dépendances entre les jobs. Ils sont capables de détecter des goulots d'étranglement invisibles à l'œil nu. Non seulement ils peuvent suggérer de paralléliser des tests lents, mais ils peuvent aussi réorganiser dynamiquement les étapes d'un pipeline en fonction du code qui a été modifié, pour ne lancer que les vérifications strictement nécessaires.
Par exemple, au lieu d'écrire manuellement un fichier .gitlab-ci.yml complexe, vous pourriez simplement décrire vos besoins. L'IA générerait alors une base de pipeline optimisée, incluant des étapes de cache intelligentes pour accélérer les installations de dépendances, une pratique souvent négligée par les juniors.
# Fichier .gitlab-ci.yml suggéré par une IA
# Analyse du code source : majoritairement du Node.js avec des tests Jest
stages:
- build
- test
- deploy
variables:
NODE_VERSION: "22.2.0"
cache:
key:
files:
- package-lock.json
paths:
- .npm/
install_dependencies:
stage: build
image: node:{NODE_VERSION}
script:
- npm ci --cache .npm --prefer-offline
artifacts:
paths:
- node_modules/
run_tests:
stage: test
image: node:{NODE_VERSION}
script:
- npm test -- --coverage
dependencies:
- install_dependenciesGénération de Tests et Sécurité Proactive
La qualité et la sécurité ne sont pas négociables. Pourtant, la rédaction de tests unitaires et d'intégration pertinents est une tâche chronophage que les équipes ont parfois tendance à écourter sous la pression des délais. L'IA change la donne en étant capable de lire le code fonctionnel et de générer automatiquement des scénarios de tests pertinents qui couvrent les cas nominaux et les cas limites.
Mais le véritable changement de paradigme se situe au niveau de la sécurité. L'approche traditionnelle consistait à utiliser des scanners de vulnérabilités (SAST/DAST) qui s'appuient sur des bases de données de failles connues. Désormais, l'AI-driven security scanning analyse la logique même de votre code pour y déceler des failles potentielles et des chemins d'attaque complexes qu'aucun outil classique n'aurait pu identifier, car ils n'existent dans aucune base de données.
| Approche Traditionnelle (SAST) | Approche Augmentée par l'IA |
|---|---|
| Basée sur des signatures de vulnérabilités connues (CVE). | Analyse contextuelle et sémantique du code. |
| Génère un nombre élevé de faux positifs. | Comprend l'intention du code et priorise les risques réels. |
| Inefficace contre les failles "zero-day" ou logiques. | Capable de modéliser des scénarios d'attaque complexes. |
| Nécessite une expertise humaine pour trier les alertes. | Fournit des explications et des suggestions de correction en langage naturel. |
La Révolution de l'Observabilité Augmentée
Une fois notre application en production, notre travail ne fait que commencer. La phase d'opération est cruciale, et c'est là que l'Observabilité entre en jeu. Il ne s'agit pas simplement de surveiller des dashboards et de recevoir des alertes. L'observabilité, c'est la capacité de poser n'importe quelle question sur l'état de votre système et d'obtenir une réponse, en se basant sur trois piliers : les logs (ce qui s'est passé), les métriques (les mesures de performance) et les traces (le parcours d'une requête).
Le volume de ces données est devenu si colossal que l'analyse humaine est tout simplement impossible. L'IA devient ici notre système nerveux central, capable de sentir une anomalie avant même qu'elle ne devienne un problème critique.
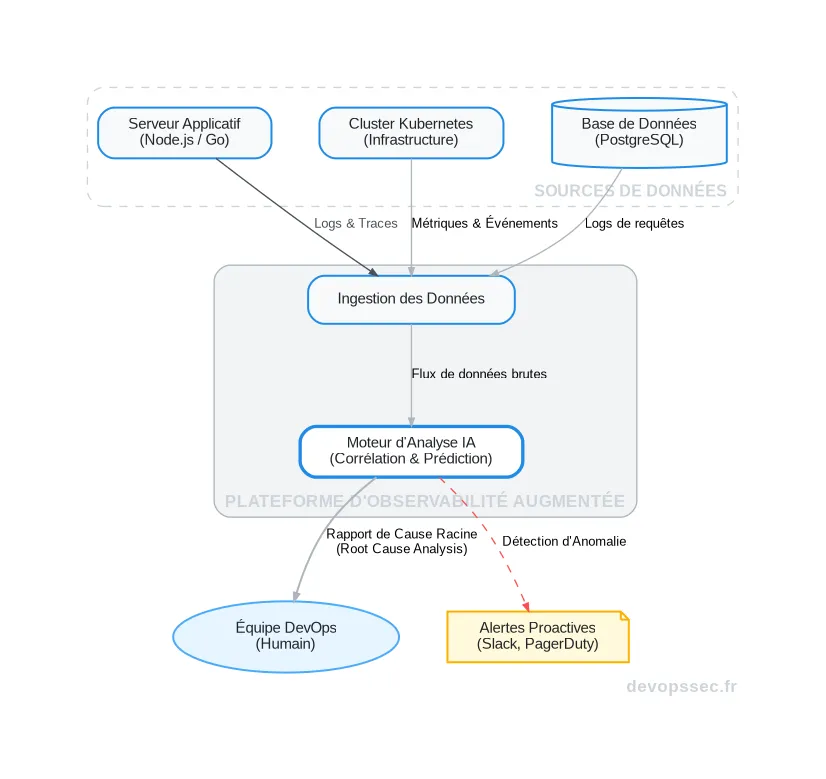
Ce schéma illustre parfaitement le flux moderne. Les différentes composantes de notre système (applications, infrastructure, bases de données) envoient un flux continu de données télémétriques vers une plateforme centralisée. C'est là que le moteur d'IA entre en action : il ne se contente pas d'agréger les données, il les met en corrélation pour identifier des schémas complexes et prédire les pannes avant qu'elles n'impactent les utilisateurs finaux.
Le Défi des Hallucinations et de la Confiance
Pourtant, il faut se garder de toute euphorie technologique. Les modèles d'IA, aussi puissants soient-ils, ne sont pas infaillibles. Ils peuvent "halluciner", c'est-à-dire générer des analyses plausibles mais complètement fausses, basées sur des corrélations statistiques erronées. Confier aveuglément la résolution d'un incident majeur à une IA pourrait conduire à des actions incorrectes, aggravant la situation.
L'enjeu n'est donc pas de remplacer l'ingénieur DevOps, mais de l'augmenter. L'IA propose une hypothèse de cause racine, documentée et argumentée, mais la décision finale et l'action corrective doivent toujours rester sous le contrôle d'un humain. Il faut aussi considérer les coûts cachés : la puissance de calcul nécessaire pour entraîner et faire tourner ces modèles est considérable, et l'expertise pour les maintenir est encore rare et chère.
L'Infrastructure as Code (IaC) à l'Ère de l'IA Générative
La gestion d'infrastructure a été révolutionnée une première fois par l'Infrastructure as Code (IaC). Cette pratique consiste à définir et provisionner des serveurs, réseaux et autres ressources cloud via des fichiers de configuration lisibles par l'homme (comme avec Terraform, OpenTofu ou Ansible), plutôt que par des clics dans une interface web. Cela a apporté la reproductibilité, le versionnage et l'automatisation.
L'IA générative apporte la seconde révolution. Fini le temps où il fallait apprendre par cœur la syntaxe complexe du HCL de Terraform ou du YAML d'Ansible. Désormais, un ingénieur peut décrire en langage naturel l'infrastructure souhaitée, et un modèle d'IA génère le code correspondant. La barrière à l'entrée s'effondre, et la vitesse de prototypage explose.
Exemple de prompt pour une IA d'IaC
La commande pourrait être aussi simple que : "Génère-moi un fichier Terraform pour déployer une machine virtuelle EC2 de type t3.micro sur AWS dans la région eu-west-3, utilisant la dernière AMI Ubuntu LTS. Elle doit se trouver dans un VPC avec un sous-réseau public et un groupe de sécurité qui autorise le trafic entrant sur les ports 22 et 80 depuis n'importe où."
Résultat:
# main.tf généré par l'IA
provider "aws" {
region = "eu-west-3"
}
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-jammy-22.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"] # Canonical
}
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
map_public_ip_on_launch = true
}
resource "aws_security_group" "web_sg" {
name = "web-server-sg"
vpc_id = aws_vpc.main.id
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
subnet_id = aws_subnet.public.id
security_groups = [aws_security_group.web_sg.name]
tags = {
Name = "WebServer-Generated-by-AI"
}
}Conclusion : L'Ingénieur DevOps Augmenté, Pas Remplacé
L'intégration de l'intelligence artificielle dans nos métiers ne signe pas la fin de l'ingénieur DevOps, bien au contraire. Elle annonce la fin des tâches à faible valeur ajoutée, de la maintenance répétitive et de la résolution d'incidents par épuisement. L'IA prend en charge le bruit, le volume et la complexité, nous permettant de nous élever pour nous concentrer sur des problématiques plus stratégiques.
Votre rôle, en tant que nouvelle génération d'ingénieurs, ne sera plus de savoir comment écrire un playbook Ansible complexe par cœur, mais de savoir comment piloter ces outils intelligents, comment valider leurs suggestions et comment concevoir des systèmes résilients et évolutifs qui tirent parti de cette nouvelle puissance. Le DevOps de demain est un métier de superviseur, d'architecte et d'innovateur. Embrassez ces outils, car ils ne sont pas une menace, mais le plus grand levier de productivité que notre profession ait jamais connu.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
23 commentaires
La clé, c'est de rester le maître à bord. L'IA est un outil, pas ton remplaçant. Si tu comprends pas ce que le code généré fait, ne le merge jamais.
Il faut toujours coupler ça avec un outil de scan type
gitleaksdans ton pipeline. Ne fais jamais confiance aveuglément à un snippet généré, surtout quand ça touche aux credentials.Et pour la sécurité des secrets ? J'ai peur que l'IA en génère dans le code par mégarde.
C'est pour ça que l'IA est utile. Elle peut analyser ton
package-lock.jsonet te proposer la config de cache optimale automatiquement. C'est du gain de temps pur.T'as mentionné le cache dans le pipeline. C'est souvent mal configuré, même sans IA.
Peu importe, la logique reste la même. L'IA génère du HCL, après c'est à toi de le versionner proprement.
Vous utilisez quels outils pour l'IaC avec IA ? Terraform ou OpenTofu ?
C'est exactement ça. Moins de temps passé à débugger un espace manquant dans un
config.yaml, c'est plus de temps pour améliorer l'architecture réseau.L'argument sur la "charge cognitive" est le meilleur. On passe trop de temps à gérer du yaml boilerplate.
Oui, mais ne laisse pas l'IA agir seule. Utilise un agent pour parser les logs et te faire un résumé des erreurs récurrentes. Exemple de script rapide :
Est-ce qu'on peut automatiser la lecture des logs avec ça ? Je suis noyé sous les logs Kubernetes.
La règle d'or : si le code généré te semble trop beau pour être vrai, vérifie les dépendances. L'IA a une connaissance figée à la date de son entraînement, elle ne connaît pas toujours les dernières versions patchées.
Le problème des hallucinations sur le code est réel. J'ai eu une suggestion qui utilisait une librairie Python obsolète. Faut être très vigilant.
C'est puissant pour générer des alertes
promqlcomplexes. Au lieu de galérer avec les fonctionsrate()ousum_over_time(), tu décris ton besoin en langage naturel et ça sort la requête.En parlant d'observabilité, vous avez des retours sur l'intégration avec Prometheus ?
Exact. L'IA oublie souvent le contexte global de ton projet. Voici comment je complète généralement le bloc pour forcer la gestion du state :
J'ai testé le bloc IaC pour Terraform. Ça génère bien, mais ça oublie systématiquement le backend S3 pour le state. C'est dangereux si on ne fait pas gaffe.
Ça dépend de ton scale. Pour des petits projets, tu peux utiliser des API tierces. Pour du gros, tu fais tourner des modèles locaux type Llama 3 sur ton infra à ne jamais exposer sur le net.
Et pour le coût de l'inférence ? Si je dois passer mon code dans un modèle à chaque push, ça va douiller sévère en token ou en GPU, non ?
Carrément. Un scanner classique voit un
os.systemet hurle. Une IA comprend si la variable passée est hardcodée ou vient d'un input utilisateur non filtré.Tu passes de "alert fatigue" à des rapports exploitables.
La comparaison avec le SAST traditionnel est pertinente. Les faux positifs, c'est vraiment l'enfer sur les outils type SonarQube. L'approche sémantique change vraiment la donne en prod ?
C'est là que le bât blesse. L'IA ne remplace pas la revue de code. Le
.gitlab-ci.ymlgénéré doit être traité comme n'importe quelle PR : tu relis, tu testes, tu valides.Le gain, c'est de ne pas se taper la doc de 50 pages pour une config de base.
Article intéressant, mais je reste sceptique sur la partie CI/CD. Utiliser une IA pour générer le
.gitlab-ci.yml, c'est bien beau, mais qui maintient le bazar quand le modèle hallucine sur une variable d'environnement ?