Avez-vous déjà regardé votre facture cloud en vous demandant si chaque euro dépensé servait réellement la performance ?
Dans notre écosystème tech, la course à la fonctionnalité a longtemps éclipsé une réalité de plus en plus prégnante : le coût et l'impact environnemental de nos infrastructures. On déploie, on scale, on innove, mais souvent sans une conscience aiguë des ressources que nous consommons réellement.
Pourtant, une nouvelle vague de fond est en train de redéfinir les standards de l'excellence opérationnelle. Il ne s'agit plus seulement de livrer vite, mais de livrer de manière intelligente, rentable et responsable. C'est ici qu'intervient une dualité puissante : le FinOps et le GreenOps.
Loin d'être de simples buzzwords, ces deux disciplines sont les piliers d'une infrastructure cloud durable et maîtrisée. Elles ne s'opposent pas ; au contraire, elles se nourrissent l'une l'autre pour créer un cercle vertueux où la performance financière rencontre la responsabilité écologique.
Le FinOps, ou l'Art de Maîtriser sa Facture Cloud
Avant de plonger dans les outils, il est essentiel de comprendre que le FinOps n'est pas une simple mission de "cost-killing" agressive. C'est avant tout une transformation culturelle qui vise à responsabiliser chaque équipe sur sa consommation de ressources cloud.
Comprendre la philosophie FinOps au-delà de la réduction des coûts
Le FinOps instaure un dialogue permanent entre les équipes techniques, financières et le management. L'objectif n'est pas de dépenser moins à tout prix, mais de dépenser mieux, en s'assurant que chaque ressource provisionnée apporte une valeur métier tangible.
Concrètement, cela signifie que les développeurs et les ops doivent intégrer la dimension financière dans leurs décisions techniques quotidiennes. Choisir une instance plus puissante n'est plus un simple choix technique, mais une décision avec un impact budgétaire qui doit être justifié.
Cette approche collaborative repose sur trois phases itératives :
- Informer : Rendre la consommation du cloud visible et compréhensible pour tous, grâce à des tableaux de bord et un tagging méticuleux.
- Optimiser : Identifier les gaspillages (ressources zombies, surdimensionnement) et appliquer les corrections nécessaires.
- Opérer : Automatiser et intégrer les bonnes pratiques de gestion des coûts directement dans les processus CI/CD et les décisions d'architecture.
Mettre en place une stratégie FinOps concrète
Passer de la théorie à la pratique demande de la méthode. La première étape, non négociable, est d'établir une stratégie de "tagging" rigoureuse. Sans labels cohérents sur vos ressources (par projet, par équipe, par environnement), toute tentative d'analyse des coûts est vouée à l'échec.
Une fois cette visibilité acquise, vous pouvez vous attaquer au surdimensionnement, le fameux "rightsizing". Il s'agit d'analyser l'utilisation réelle des CPU, de la RAM et du disque de vos machines virtuelles ou de vos pods Kubernetes pour les ajuster à la taille la plus juste.
Enfin, l'automatisation est votre meilleure alliée pour pérenniser vos efforts. Mettez en place des scripts pour éteindre les environnements de développement le soir et le week-end, ou utilisez des politiques pour supprimer automatiquement les volumes de stockage non attachés.
| Action FinOps | Impact Direct | Outils Associés |
|---|---|---|
| Tagging des ressources | Visibilité et répartition des coûts par projet/équipe | AWS Cost Explorer, Azure Cost Management, GCP Billing |
| Rightsizing des instances | Réduction du coût des ressources surprovisionnées | CloudWatch, Azure Monitor, Outils tiers (Cloudability, Densify) |
| Planification (Scheduling) | Arrêt des ressources non critiques hors heures ouvrées | AWS Instance Scheduler, Azure Automation, Scripts personnalisés |
| Utilisation d'instances Spot/Préemptives | Coûts jusqu'à 90% inférieurs pour les charges de travail tolérantes aux pannes | Amazon EC2 Spot, Azure Spot VMs, Google Cloud Preemptible VMs |
Le GreenOps, le Pendant Écologique de l'Optimisation
Si le FinOps s'occupe de la santé financière de votre infrastructure, le GreenOps, lui, se concentre sur sa santé environnementale. Les deux sont intimement liés, car une ressource qui ne tourne pas ne consomme ni argent, ni énergie.
Qu'est-ce que le GreenOps et pourquoi devient-il crucial ?
Le GreenOps est une discipline émergente qui consiste à appliquer les principes DevOps pour mesurer, analyser et réduire l'empreinte carbone des infrastructures informatiques. Il ne s'agit plus seulement de performance applicative, mais aussi de performance énergétique.
L'urgence climatique et la pression sociétale poussent les entreprises à intégrer des objectifs de durabilité dans leur stratégie. Le GreenOps fournit le cadre et les outils pour traduire ces ambitions en actions techniques concrètes, en agissant sur la consommation électrique des serveurs, le refroidissement des datacenters et l'efficacité du code.
Adopter le GreenOps, c'est reconnaître que chaque ligne de code, chaque requête en base de données et chaque conteneur déployé a un impact physique sur la planète. C'est un changement de paradigme qui pousse à concevoir des applications non seulement performantes, mais aussi sobres énergétiquement.
Techniques et outils pour une infrastructure plus verte
La première action GreenOps, souvent la plus simple, est de choisir judicieusement la région de votre fournisseur cloud. Privilégiez les régions alimentées majoritairement par des énergies renouvelables. La plupart des grands acteurs du cloud communiquent désormais sur le mix énergétique de leurs datacenters.
Ensuite, travaillez sur l'efficacité de vos applications. Un code optimisé qui exécute une tâche plus rapidement consomme moins de cycles CPU et donc moins d'énergie. Des outils de profilage applicatif (APM) peuvent vous aider à identifier les goulots d'étranglement énergivores dans votre code.
L'architecture de vos systèmes joue également un rôle clé. Adopter une architecture orientée événements ou des technologies serverless peut considérablement réduire la consommation à vide, puisque les ressources ne sont sollicitées qu'en cas de besoin réel, contrairement à un serveur traditionnellement allumé en permanence.
Mesurer pour progresser
Des outils open source comme Cloud Carbon Footprint (développé par ThoughtWorks) ou Scaphandre permettent d'estimer les émissions de CO2 de votre infrastructure cloud. Les intégrer dans vos dashboards de monitoring est un premier pas essentiel pour rendre cet impact visible.
La Synergie Gagnante : Quand FinOps rencontre GreenOps
Vous l'aurez compris, ces deux approches ne sont pas des silos. Elles forment un duo puissant où les optimisations de l'une bénéficient presque systématiquement à l'autre. C'est une stratégie de "double gain".
Un cercle vertueux pour la performance et la responsabilité
Chaque fois que vous réalisez une action FinOps, comme le "rightsizing" d'une instance ou la suppression d'une ressource zombie, vous réduisez non seulement la facture mais aussi la consommation d'énergie associée. Moins de CPU et de RAM alloués signifient directement moins d'électricité consommée par les serveurs et les systèmes de refroidissement.
Cette synergie crée une culture de l'efficience. Les équipes ne cherchent plus seulement à optimiser pour le coût ou pour la performance, mais pour un équilibre global. Le Cloud TCO (Total Cost of Ownership) s'enrichit ainsi d'une nouvelle dimension : le coût environnemental.
Le schéma ci-dessous illustre comment ces deux pratiques peuvent être intégrées dans une pipeline CI/CD moderne pour prendre des décisions éclairées avant même le déploiement en production.
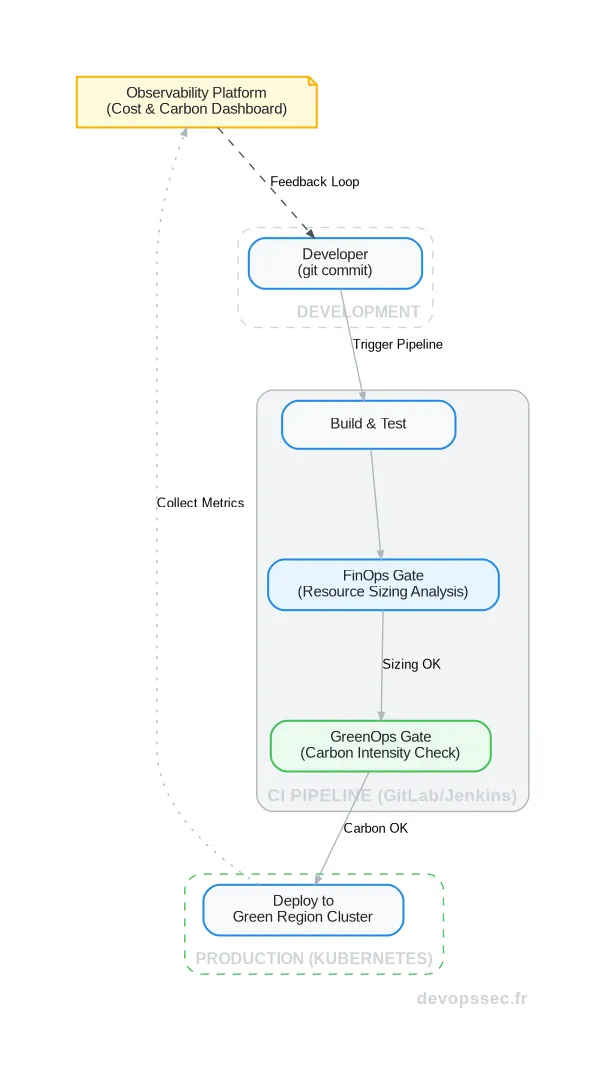
Ce flux montre que les vérifications FinOps et GreenOps deviennent des portes de qualité (quality gates) à part entière dans la chaîne de déploiement, empêchant le code ou l'infrastructure non optimisés d'atteindre la production.
Les limites et les coûts cachés de cette double approche
Cependant, il serait naïf de penser que cette transition est sans effort. La mise en place d'une culture FinOps et GreenOps représente un investissement initial non négligeable. Il faut du temps pour former les équipes, mettre en place les bons outils de monitoring et définir des processus de gouvernance clairs.
De plus, la mesure de l'empreinte carbone n'est pas une science exacte. Elle repose sur des estimations et des modèles fournis par les fournisseurs cloud, qui peuvent manquer de transparence ou de granularité. Il y a un risque de se focaliser sur des métriques imparfaites.
Enfin, l'optimisation à outrance peut avoir des effets pervers. Un "rightsizing" trop agressif peut dégrader les performances et la résilience de vos applications lors de pics de charge imprévus. L'objectif est de trouver le juste équilibre entre sobriété et qualité de service, un arbitrage qui demande une surveillance constante.
Le Futur du Cloud est Responsable et Rentable
Le temps où l'on pouvait consommer des ressources cloud sans compter est révolu. La double pression économique et écologique nous oblige à repenser fondamentalement notre rapport à l'infrastructure. Le DevOps doit évoluer pour intégrer nativement ces préoccupations.
Le FinOps et le GreenOps ne sont pas des contraintes, mais des opportunités de construire des systèmes plus élégants, plus efficients et plus résilients. En tant que nouvelle génération de professionnels de la tech, vous avez le pouvoir et le devoir de porter cette vision.
Commencez petit : identifiez une ressource "zombie" dans votre projet, proposez de choisir une région cloud plus verte pour le prochain service, ou ajoutez simplement un widget de coût au dashboard de votre équipe. Chaque petite action contribue à bâtir un futur où la technologie rime avec responsabilité.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
21 commentaires
N'oubliez jamais que l'infrastructure la plus écologique est celle que vous n'avez pas besoin de provisionner.
Avant de chercher à optimiser vos déploiements, posez-vous la question : est-ce que ce service est vraiment nécessaire pour l'utilisateur final ?
Justement, en startup, le FinOps est vital. Si tu brûles ton cash en serveurs inutiles, tu meurs plus vite.
Le GreenOps est juste le sous-produit naturel d'une gestion financière saine. Pas besoin d'outils complexes, juste de supprimer ce qui ne sert à rien.
Tout ça c'est bien beau pour les grosses boîtes. Dans une startup, on n'a ni le temps ni les ressources pour faire du GreenOps. On survit, c'est tout.
C'est pour ça qu'il faut coupler les outils des fournisseurs avec des solutions open source comme Cloud Carbon Footprint.
Ne jamais se fier à une seule source de vérité. Multiplie les points de vue pour avoir une vision réaliste de ton empreinte.
Comment tu gères le fait que les métriques cloud sont biaisées ? Les fournisseurs ont tout intérêt à ce qu'on consomme plus.
Tu as raison. La technique ne remplace jamais la revue de code. Si un dev met 100Gi de RAM pour un microservice qui fait du Hello World, c'est au reviewer de bloquer la PR.
Le script est juste une sécurité pour éviter les oublis grossiers, pas pour remplacer le bon sens.
C'est trop basique ton script. Un vrai dev contournera ça en mettant des valeurs absurdes juste pour passer le check. Il faut analyser la valeur métier pas juste la présence de lignes dans le YAML.
Voici un exemple simple à insérer dans ton pipeline pour checker les limites de ressources avant le déploiement :
Est-ce que tu peux nous montrer un exemple de ton pipeline CI/CD avec les quality gates FinOps ? Je suis curieux de voir comment tu bloques un déploiement sans faire hurler les devs.
Le serverless n'est pas une solution miracle, c'est un outil. Si tu as une charge constante, une instance bien dimensionnée sera toujours plus efficiente.
Mais pour du traitement asynchrone, le serverless gagne haut la main en termes d'efficience énergétique.
Le serverless est cité comme solution écologique. C'est une blague ? Les cold starts et l'opacité totale sur ce qui tourne derrière, c'est l'opposé de la maîtrise.
Vous parlez d'automatisation mais personne ne parle du coût de maintenance des scripts.
Gérer les arrêts/relances via
cronou des fonctions Lambda, c'est ajouter de la dette technique. Faut maintenir ces scripts aussi.La question n'est pas de gagner 3 euros. C'est de changer la culture. Quand les devs voient la corrélation entre une requête SQL mal optimisée et la consommation CPU, ils codent mieux.
C'est une boucle de feedback, pas juste une feuille Excel.
Perso, j'ai mis en place
scaphandrepour monitorer la conso énergétique. C'est instructif mais ça demande un temps de conf de dingue.Est-ce que ça vaut vraiment le coup de passer 2 jours à configurer ça pour économiser 3 euros de courant par mois ?
Parler de GreenOps alors qu'on tourne sur des instances surdimensionnées, c'est du greenwashing. Le vrai gain, c'est de supprimer les services inutiles, pas de mettre des widgets de CO2.
Je n'ai jamais dit qu'il fallait mettre la base de données sur du Spot. C'est pour les charges de travail tolérantes aux pannes.
Si ton architecture ne supporte pas le crash d'un nœud, c'est que ton problème n'est pas le coût, mais la résilience.
Utiliser des instances Spot pour tout et n'importe quoi c'est du suicide pour la prod. J'ai déjà vu des clusters entiers tomber parce que le fournisseur a repris les instances en pleine nuit.
D'accord avec toi. Le rightsizing ne doit jamais se faire à l'aveugle. Il faut baser les seuils sur des métriques réelles de
cpu_usageet non sur des limites théoriques.Si tu as peur de la casse, utilise l'auto-scaling horizontal (HPA) au lieu de chercher à dimensionner manuellement tes instances.
Le rightsizing c'est bien, mais avec le bursting des instances cloud, tu te fais toujours avoir.
Si je limite trop les CPU, mon app plante dès qu'il y a un pic de requêtes. C'est l'éternel compromis entre économie et disponibilité.
C'est une réalité. La solution, c'est d'intégrer le tagging dans tes
terraformouhelmcharts dès le début.Si la ressource n'a pas de tag, elle est détruite automatiquement par un script. Tu verras que les devs deviennent très vite disciplinés quand leur environnement de test dégage.
Encore un article qui survole le sujet. Le tagging, c'est bien joli sur le papier, mais en vrai, tu te retrouves avec 300 ressources non taguées par des devs qui s'en foutent.
Comment tu gères la gouvernance quand t'as pas une équipe dédiée pour traquer les oublis via
kubectl get pods --all-namespaces --show-labels?