Tissus Réseaux Intelligents : L'Ère de l'Opération par Intention
Vous avez passé des mois à perfectionner vos pipelines CI/CD et à orchestrer vos microservices avec une précision chirurgicale, mais une question persiste : comment le réseau, cette fondation invisible, peut-il suivre le rythme effréné de vos déploiements continus ? La réponse ne se trouve plus dans la configuration manuelle de routeurs, mais dans une approche radicalement nouvelle.
Nous entrons dans l'ère des tissus réseaux intelligents, une évolution où l'infrastructure ne se contente plus d'exécuter des ordres, mais comprend l'intention derrière chaque application. C'est une transformation profonde qui place le réseau au cœur de la stratégie DevOps, le faisant passer d'un goulot d'étranglement potentiel à un catalyseur d'agilité.
Le Tissu Réseau : Bien Plus qu'un Enchevêtrement de Câbles
Oubliez l'image traditionnelle du réseau comme une collection de boîtiers matériels gérés individuellement. Un tissu réseau (network fabric) moderne est une architecture logicielle qui superpose une couche d'intelligence et d'abstraction sur l'ensemble de l'infrastructure physique, qu'elle soit sur site, dans le cloud ou en périphérie.
Concrètement, il traite l'ensemble des commutateurs, routeurs et points d'accès comme une seule et unique entité logique. Cette vision unifiée permet une gestion centralisée et, surtout, une automatisation à grande échelle, ce qui était impensable avec les approches traditionnelles en silo.
L'Intention comme Moteur de l'Automatisation
Le véritable changement de paradigme réside dans le concept d'opération par intention (Intent-Based Networking ou IBN). Plutôt que de dicter au réseau une série de commandes impératives complexes et sujettes aux erreurs, vous lui déclarez un objectif métier de haut niveau.
Vous ne dites plus "Configure le VLAN 10 sur le port 5 du switch A et applique l'ACL 101". Vous exprimez une intention comme "Je veux que mon service de paiement puisse communiquer avec la base de données clients de manière sécurisée et avec une latence inférieure à 10ms".
Le système IBN se charge alors de traduire cette intention en configurations techniques concrètes, de les déployer sur le tissu réseau, de vérifier en continu que l'état souhaité est maintenu et de s'auto-corriger en cas de dérive ou d'incident. C'est le passage du "comment" au "quoi", libérant les équipes d'une charge opérationnelle immense.
De la Théorie à la Pratique : L'IBN dans la Chaîne DevOps
L'intégration de l'IBN dans une culture DevOps est naturelle car elle étend les principes de l'Infrastructure as Code (IaC) à la couche réseau. La politique réseau devient un simple fichier déclaratif, versionné dans un dépôt Git, au même titre que votre code applicatif ou vos manifestes Kubernetes.
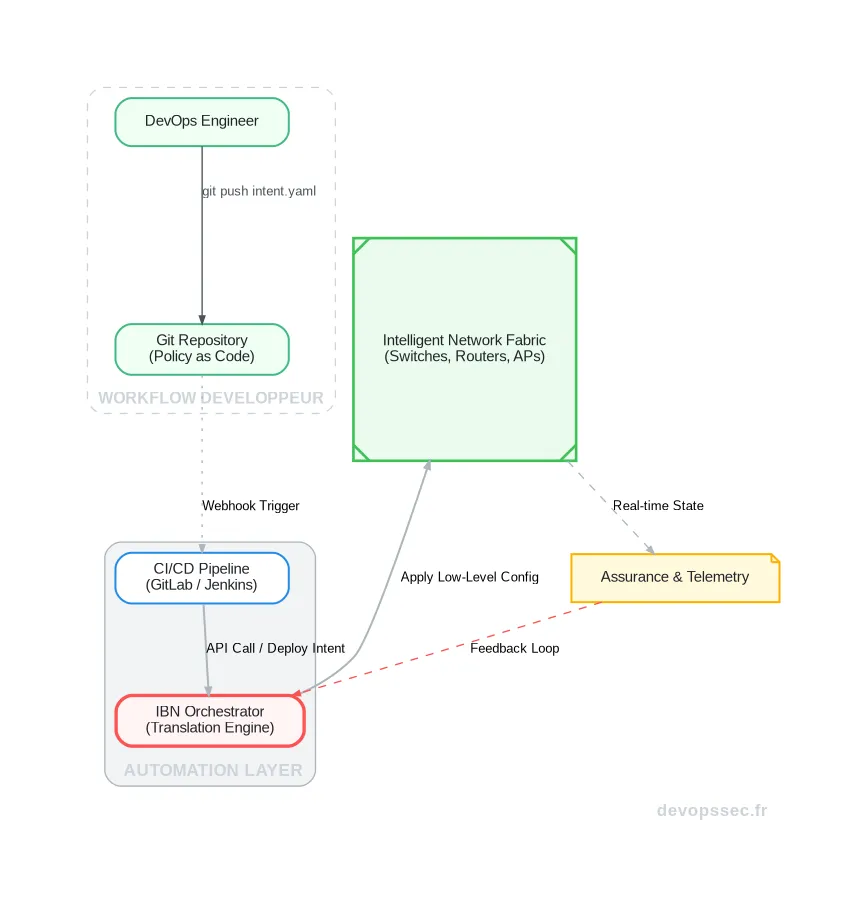
Ce schéma illustre parfaitement le cycle de vie d'une politique réseau. L'ingénieur DevOps décrit l'intention dans un fichier YAML et le pousse sur Git. Cette action déclenche un pipeline CI/CD qui valide la syntaxe puis transmet la demande à l'orchestrateur IBN. Ce dernier traduit l'intention en configuration de bas niveau et l'applique sur le tissu réseau physique, tout en recevant un retour constant des systèmes de monitoring pour garantir que l'état désiré est bien respecté.
Exemple de Déclaration d'Intention
Imaginons le déploiement d'un nouveau microservice de reporting qui doit accéder à une base de données analytique. Au lieu de créer des tickets pour l'équipe réseau, le développeur ajoute ce bloc à un fichier de configuration dans son dépôt de code.
# intents/reporting-service.yaml
- name: Allow reporting service to access analytics DB
intent:
source:
app_tier: microservice
name: reporting-v2
destination:
app_tier: database
name: analytics-prod-db
action: allow
service:
protocol: tcp
port: 5432
constraints:
latency: "low"
security_profile: "internal-encrypted"Ce fichier est non seulement lisible par un humain, mais il est surtout agnostique de l'infrastructure sous-jacente. L'orchestration se charge de trouver où se situent ces services et d'appliquer les bonnes règles, que les workloads tournent sur des VMs, des conteneurs ou des serveurs bare-metal.
Le rôle de la Télémétrie
La phase d'assurance est cruciale. Le tissu réseau collecte en permanence des milliers de points de données (télémétrie) pour vérifier que l'intention est respectée. Si la latence mesurée dépasse le seuil défini, le système peut automatiquement rerouter le trafic ou alerter les équipes.
Les Avantages Directs pour les Opérations et la Sécurité
L'adoption d'un tissu intelligent piloté par l'intention n'est pas qu'un exercice technique. Elle apporte des bénéfices concrets et mesurables qui transforment la manière dont les équipes collaborent et déploient des applications.
| Domaine | Approche Traditionnelle (Impérative) | Tissu Intelligent (Déclarative) |
|---|---|---|
| Déploiement | Scripts manuels, configuration par CLI, processus lent et sujet aux erreurs. | Politique réseau "as code", intégrée au pipeline CI/CD, déploiement en quelques minutes. |
| Sécurité | Règles de pare-feu statiques, difficiles à maintenir. Segmentation manuelle. | Micro-segmentation dynamique basée sur l'identité des applications, politique de "zero trust" native. |
| Dépannage | Analyse manuelle des logs sur de multiples équipements. Corrélation complexe. | Visibilité de bout en bout, diagnostic assisté par IA, auto-correction des problèmes courants. |
| Scalabilité | Ajouter un nouvel équipement nécessite une reconfiguration manuelle extensive. | Détection et intégration automatique de nouveaux nœuds ("zero-touch provisioning"). |
Attention à la Complexité Abstraite
Malgré ses promesses, cette technologie introduit une nouvelle couche d'abstraction qui a ses propres défis. Le système d'orchestration devient une pièce maîtresse de votre infrastructure, un "single point of failure" potentiel dont la maîtrise demande des compétences très pointues.
Il existe également un risque de dépendance vis-à-vis d'un fournisseur (vendor lock-in), car les solutions de tissus réseaux sont souvent propriétaires. Une analyse rigoureuse est nécessaire pour choisir une plateforme qui reste ouverte et interopérable.
Enfin, il est crucial de ne pas laisser cette abstraction occulter la nécessité pour les ingénieurs de conserver une compréhension fondamentale des principes réseaux. Un outil, aussi intelligent soit-il, ne remplacera jamais la capacité d'analyse d'un expert face à un problème complexe et inédit.
Conclusion : Le Réseau comme Partenaire Actif
Les tissus réseaux intelligents et l'opération par intention ne sont pas une simple tendance, mais la suite logique de l'évolution DevOps. Ils appliquent au réseau les mêmes principes d'automatisation, de déclaratif et de collaboration qui ont déjà fait leurs preuves pour le code et l'infrastructure serveur.
En transformant le réseau d'une entité passive et rigide en un système dynamique et conscient du contexte applicatif, nous permettons enfin à l'ensemble de la pile technologique de bouger à la même vitesse. Pour vous, jeune ingénieur, maîtriser ces concepts, c'est vous assurer de ne pas seulement suivre le mouvement, mais de le piloter.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
La qualité du modèle est effectivement le point critique. C'est pour ça qu'on itère sur les manifestes. On ne fait pas tout d'un coup, on migre service par service.
L'automatisation du réseau, c'est le graal. Mais attention, si votre modèle de données est pourri dès le départ, votre réseau sera juste automatiquement pourri.
Le jour où ton orchestrateur tombe, tu te retrouves avec une infrastructure en dette technique totale, incapable de faire une modification manuelle propre. Bon courage pour le support.
Jamais de secrets en clair. On utilise des outils comme
Vaultpour injecter les creds dynamiquement au moment du déploiement via des variables d'environnement.Ton schéma sur le cycle de vie est joli, mais il manque la gestion des secrets. Tu stockes tes credentials réseau dans ton repo Git ? C'est la faille de sécurité assurée.
Maîtriser les fondamentaux est indispensable, personne ne dit le contraire. Mais scaler sans abstraction, c'est foncer dans le mur. Voici comment on gère la sécurité par intention :
Le concept d'intention est louable mais en vrai, c'est juste une surcouche de complexité pour masquer l'incompétence des ops sur le réseau pur. Apprenez vos routes BGP avant de vouloir automatiser.
Le coup du
latency: "low"dans le YAML, c'est mignon. Mais comment le système mesure ça réellement ? Tu fais dupingen boucle ? C'est pas sérieux.Le pipeline CI/CD valide tout. Si le
lintou le test d'intégration échoue, rien n'est poussé. On ne laisse pas l'IA décider seule en prod, elle propose, l'humain valide via unePull Request.L'IA pour le routage, c'est le meilleur moyen de créer un incident majeur en prod. Qui valide le changement avant que l'orchestrateur ne pousse la config ?
J'ai vu des boîtes essayer de mettre ça en place. Le résultat ? Une équipe réseau qui ne sait plus configurer un VLAN à la main et qui est totalement démunie dès que l'IA hallucine sur une règle de routage.
C'est pour ça qu'on parle de tissus réseaux. L'orchestrateur fait le pont. Il parle
REST APIaux couches hautes etSNMPouSSHaux vieux équipements. C'est du taf, mais c'est le prix à payer pour l'agilité.Ok, l'idée de déclarer son intention est séduisante, mais dans un environnement hybride avec du legacy, c'est impossible à tenir. Tes switchs hardware ne supportent pas tous ce niveau d'abstraction.
On filtre à la source. Inutile de tout envoyer. Voici une approche simple pour ne garder que le nécessaire :
La télémétrie c'est bien, mais ça génère un volume de logs monstrueux. Vous gérez ça comment sans saturer le bus de données ?
Le risque de lock-in est réel. La parade, c'est de choisir des standards ouverts ou des APIs basées sur
gNMIouOpenConfig. L'objectif est de garder le contrôle tout en automatisant la couche répétitive.Totalement d'accord avec le VDD. On a testé des solutions SDN propriétaires, c'est une usine à gaz. Dès que t'as un edge case réseau, tu te retrouves coincé par l'abstraction.
Le problème de ton
reporting-service.yaml, c'est la dépendance au fournisseur. T'es en train de créer un vendor lock-in massif. Si ton outil IBN propriétaire change son API, tu réécris tout ton catalogue d'intentions ?C'est une critique valide. L'orchestrateur n'est pas magique. Il faut traiter ton état réseau comme ton état Kubernetes : si ça diverge, tu inspectes les logs de ton contrôleur. L'idée c'est justement de ne plus avoir à faire de
show running-configà la main sur 50 switchs.Encore un article qui vend du rêve avec l'IA et l'intention. En pratique, quand ton orchestrateur IBN plante en plein milieu d'un déploiement, tu fais quoi ? Tu pries pour que le
rollbackfonctionne ?