Le DevOps Face à sa Propre Limite
As-tu déjà ressenti cette impression que nos pipelines CI/CD, aussi sophistiqués soient-ils, ne sont finalement que des enchaînements de scripts glorifiés ? Nous avons passé des années à perfectionner l'automatisation, à embrasser GitOps comme une source unique de vérité, et pourtant, nous voilà souvent à gérer une complexité qui nous dépasse, où la moindre déviation du chemin nominal nécessite une intervention humaine.
Cette complexité croissante des systèmes distribués nous pousse vers une nouvelle frontière. L'automatisation déclarative, où l'on décrit un état désiré, atteint ses limites. Il est temps de passer à l'automatisation intentionnelle, où nous décrivons un objectif, et laissons une intelligence logicielle déterminer les étapes pour y parvenir et s'y maintenir.
C'est précisément ici qu'entrent en scène les Agents Autonomes. Il ne s'agit plus de simples scripts qui exécutent une liste de tâches, mais de véritables entités logicielles capables de percevoir leur environnement, de prendre des décisions et d'agir pour atteindre des objectifs de haut niveau, comme garantir une performance ou optimiser des coûts.
Qu'est-ce qu'un Agent DevOps Autonome ?
Pour bien saisir le changement de paradigme, il faut abandonner l'idée d'une séquence d'actions figée. Un agent ne suit pas une recette il cuisine en s'adaptant aux ingrédients disponibles et à l'appétit des convives, avec pour seul but de livrer un plat excellent.
Au-delà du Script, la Prise de Décision
La distinction fondamentale réside dans la capacité de décision. Un script de déploiement classique exécute une série de commandes : `build`, `test`, `push`, `deploy`. Si une étape échoue, il s'arrête. Il est prévisible, mais rigide et dénué de contexte. Il ne sait pas pourquoi il exécute ces tâches.
Un agent, lui, opère sur la base d'une intention. Son objectif pourrait être "Maintenir le service de paiement avec une latence inférieure à 100ms et un taux d'erreur sous 0.1%". Pour y parvenir, il peut déclencher un déploiement, mais aussi un rollback, un redimensionnement de l'infrastructure ou même l'activation d'un feature flag pour désactiver une fonctionnalité coûteuse, en choisissant l'action la plus pertinente en temps réel.
Cette approche dynamique transforme radicalement la gestion de production, passant d'une simple automatisation à une véritable Orchestration Intelligente. Les actions ne sont plus prédéfinies par un humain, mais déduites par la machine en fonction de l'état du système.
| Critère | Automatisation Classique (Script) | Orchestration par Agent Autonome |
|---|---|---|
| Logique | Impérative ("Fais ceci, puis cela") | Intentionnelle ("Atteins cet objectif") |
| Déclencheur | Événement prédéfini (ex: git push) | Analyse continue de l'état du système |
| Adaptabilité | Faible, nécessite une modification du code | Élevée, l'agent choisit l'action appropriée |
| Contexte | Aucun, exécute des tâches isolées | Prise en compte globale (métriques, logs, traces) |
Les Composants Clés d'un Agent
Pour qu'une telle entité puisse fonctionner, elle s'appuie sur une architecture interne bien définie, qui mime en quelque sorte un cycle de réflexion humain. Chaque agent, qu'il soit spécialisé dans la sécurité, la performance ou les coûts, partage une structure commune.
Concrètement, on retrouve presque toujours les mêmes briques logicielles qui lui permettent de percevoir, décider et agir de manière cohérente et informée.
- Moteur de Perception : Il se connecte à toutes les sources de données pertinentes. On parle ici des plateformes d'observabilité comme Prometheus pour les métriques, Loki pour les logs, ou Jaeger pour les traces distribuées. C'est le système sensoriel de l'agent.
- Moteur de Décision : Le cerveau de l'opération. Il peut s'agir d'un modèle de machine learning, d'un arbre de décision complexe ou, de plus en plus, d'un Large Language Model (LLM) entraîné sur des runbooks et des documentations techniques pour interpréter la situation et choisir la meilleure stratégie.
- Moteur d'Action : Une fois la décision prise, ce sont les "mains" de l'agent. Il utilise des API pour interagir avec l'environnement : l'API Kubernetes pour gérer les pods, le SDK d'un fournisseur cloud pour provisionner des ressources, ou une API interne pour basculer un feature flag.
- Base de Connaissances : La mémoire à long terme. Elle contient l'historique des actions passées, leurs résultats, la topologie du système et les bonnes pratiques encodées. C'est ce qui permet à l'agent d'apprendre et de s'améliorer avec le temps.
L'Écosystème en Action: Orchestrer une Flotte d'Agents
L'erreur serait de penser à un seul agent monolithique qui ferait tout. La puissance de ce modèle réside dans la collaboration d'une flotte d'agents spécialisés, chacun se concentrant sur un domaine précis : sécurité, coût, performance, déploiement. Le véritable défi est de les faire travailler ensemble de manière harmonieuse.
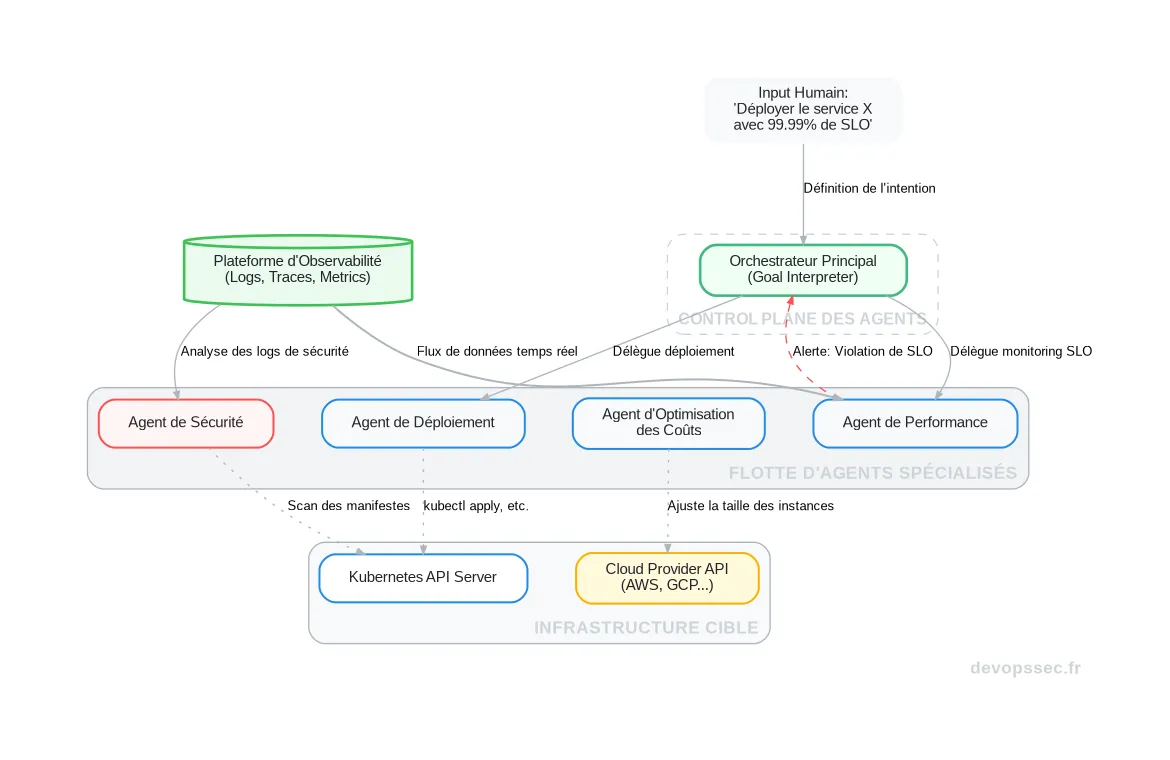
Ce schéma illustre parfaitement la séparation des responsabilités. Un opérateur humain définit un objectif de haut niveau auprès de l'Orchestrateur. Ce dernier traduit l'objectif en sous-tâches qu'il distribue aux agents spécialisés. Chaque agent utilise les données de la plateforme d'observabilité pour guider ses actions sur l'infrastructure, puis remonte son statut à l'orchestrateur, fermant ainsi la boucle de contrôle.
Limites et Risques: Le Paradoxe du Contrôle
Confier les clés de la production à des entités autonomes n'est pas sans risque. Le gain en agilité et en résilience s'accompagne de nouveaux défis. Le plus évident est le risque de décision erronée : un agent mal configuré ou s'appuyant sur un modèle "hallucinant" pourrait interpréter une situation de travers et provoquer une panne massive en tentant de la "réparer".
La sécurité est également une préoccupation majeure. Un agent disposant des droits pour modifier l'infrastructure devient une cible de choix. Le compromettre reviendrait à donner un accès administrateur complet à un attaquant. Il devient donc crucial de mettre en place une Gouvernance des Agents, avec des permissions granulaires, des audits constants et des mécanismes de "coupe-circuit" pour désactiver un agent au comportement suspect.
Enfin, il faut prendre en compte le coût caché. Faire tourner des modèles d'IA complexes pour la prise de décision consomme des ressources de calcul non négligeables. L'optimisation des coûts d'infrastructure pourrait paradoxalement être annulée par le coût de fonctionnement de la flotte d'agents elle-même.
Mettre en Place son Premier Agent: Un Scénario Pratique
La théorie est fascinante, mais comment aborder ce monde concrètement ? L'approche est bien plus centrée sur la déclaration d'intention que sur l'écriture de code impératif. Voyons un exemple simple : créer un agent chargé de garantir la stabilité d'un service après un déploiement.
Définir l'Intention (The Goal)
Tout commence par un fichier de manifeste, souvent en YAML, qui décrit l'objectif, les contraintes et les indicateurs à surveiller. Ce fichier devient le contrat que l'agent doit respecter. Il ne contient aucune logique de "comment faire", seulement le "quoi" et le "pourquoi".
apiVersion: agent.io/v1
kind: Goal
metadata:
name: payment-service-stability
spec:
selector:
app: payment-service
objective: "Maintain service stability post-deployment"
slis: # Service Level Indicators
- name: latency_p99
source: prometheus
query: 'histogram_quantile(0.99, sum(rate(http_requests_latency_seconds_bucket{app="payment-service"}[5m])))'
threshold: 0.1 # 100ms
- name: error_rate
source: prometheus
query: 'sum(rate(http_requests_total{app="payment-service", status_code=~"5.*"}[5m])) / sum(rate(http_requests_total{app="payment-service"}[5m]))'
threshold: 0.01 # 1%
actions:
- name: rollout_canary
- name: progressive_traffic_shifting
- name: full_rollback
- name: scale_up_replicasDans ce manifeste, nous donnons un nom à notre objectif, nous ciblons une application spécifique via un sélecteur, et nous définissons les indicateurs de performance (SLI) qui matérialisent la "stabilité". Nous listons également les actions que l'agent est autorisé à entreprendre.
Observer l'Agent au Travail
Une fois le manifeste appliqué, l'agent entre en action. Il se connecte aux sources de données et commence son cycle de perception-décision-action. Son journal d'événements est notre meilleure fenêtre pour comprendre son raisonnement et valider son comportement.
kubectl logs -f agent-controller-xyzRésultat:
[INFO] Goal 'payment-service-stability' loaded. Watching deployment 'payment-service'.
[INFO] New version 'v1.2.3' detected. Starting canary rollout.
[INFO] Shifting 10% of traffic to 'v1.2.3'. Monitoring SLIs.
[INFO] SLIs are stable. Latency: 45ms, Error Rate: 0.05%.
[INFO] Shifting 50% of traffic to 'v1.2.3'. Monitoring SLIs.
[WARN] SLI 'latency_p99' threshold breached. Current value: 124ms.
[INFO] Correlating latency spike with new version 'v1.2.3'. High confidence.
[INFO] Decision: Initiating rollback to previous stable version 'v1.2.2'.
[INFO] Executing action 'full_rollback'. Traffic shifted back to 100% on 'v1.2.2'.
[INFO] SLIs restored. Latency: 42ms, Error Rate: 0.04%.
[INFO] Goal 'payment-service-stability' is met. Awaiting next event.Ce log est extrêmement parlant. On y voit l'agent suivre une stratégie de déploiement progressive, détecter une anomalie, en identifier la cause probable, prendre une décision corrective de manière autonome, et vérifier que son action a bien eu l'effet escompté. Aucune intervention humaine n'a été nécessaire.
De l'importance de la simulation
Avant de lâcher un agent sur votre production, utilisez des environnements de "shadowing" ou des simulateurs. Configurez l'agent pour qu'il annonce les décisions qu'il aurait prises sans les exécuter réellement. Cela vous permet de valider sa logique et de bâtir la confiance sans risquer d'incident.
Conclusion: Votre Nouveau Rôle de Chef d'Orchestre
L'avènement des agents autonomes ne signe pas la fin du métier de DevOps, bien au contraire. Il le fait évoluer vers un rôle plus stratégique. Fini le temps passé à écrire et déboguer des kilomètres de scripts YAML ou de pipelines. Votre mission devient celle d'un architecte de systèmes cognitifs, d'un chef d'orchestre qui définit les objectifs business et les garde-fous.
Vous n'êtes plus celui qui tourne les manivelles, mais celui qui conçoit la machine intelligente qui les tourne. Il s'agit de définir les intentions, de fournir aux agents les bonnes données pour décider, d'auditer leurs actions et, surtout, de construire la confiance de toute l'organisation dans ce nouveau mode de fonctionnement.
C'est une transformation profonde qui demande de nouvelles compétences, notamment en analyse de systèmes complexes et en gouvernance de l'IA. Mais le jeu en vaut la chandelle : des systèmes plus résilients, plus performants et des équipes libérées pour se concentrer sur ce qui apporte réellement de la valeur.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
18 commentaires
Au début, oui, force le mode approval. L'agent propose, l'humain clique sur 'Valider' via une interface Slack ou autre.
Une fois que tu as 99% de confiance, tu enlèves le frein. Mais garde toujours une option d'urgence pour tout couper.
Le passage sur le 'paradoxe du contrôle' est très vrai. On finit par ne plus savoir pourquoi le cluster scale.
Tu conseilles de garder un 'human-in-the-loop' systématique au début ?
Commence simple : une boucle de contrôle en Python qui interroge Prometheus, et qui utilise les API de ton orchestrateur.
Pas besoin de LLM au début. L'autonomie commence par la boucle de contrôle, pas par le cerveau.
C'est quoi la stack recommandée pour débuter ? Je veux pas monter une usine à gaz pour rien.
On utilise des
Audit Logsdédiés. Chaque décision de l'agent est liée à un ID de 'raisonnement'.Tu peux ainsi rejouer la séquence pour voir pourquoi il a cru que c'était une bonne idée de faire un
rollout_canaryà 4h du mat.La gouvernance des agents, c'est le point noir. Comment tu audites ce qu'un agent a fait sans passer 3 heures à lire des logs JSON ?
Ne laisse jamais l'agent analyser le brut. Ajoute une couche de prétraitement avec des outils comme
vector.devpour structurer tes logs avant qu'ils arrivent dans le moteur de décision.Moins de bruit, moins d'hallucinations.
J'ai testé un POC similaire avec des agents en Go. Le plus dur c'est le
Moteur de Perception.Tu as des conseils pour éviter le bruit dans les logs quand l'agent analyse Loki ?
C'est là que l'orchestrateur intervient. Il a une hiérarchie de priorités. Dans le manifeste, tu peux définir des poids ou des domaines réservés.
Si conflit il y a, l'orchestrateur arbitre selon la politique que tu as fixée. On ne laisse pas les agents se battre pour les ressources sans supervision.
Sympa l'exemple du
manifeste. Tu gères comment les dépendances entre agents ?Si l'agent 'coût' décide de scale down et que l'agent 'performance' décide de scale up en même temps, c'est la bagarre.
Le coût est réel, c'est clair. Mais compare ça au coût d'une panne majeure de 2 heures parce qu'un script rigide n'a pas su réagir à une erreur non prévue.
L'idée n'est pas de tout mettre sous LLM. Utilise des modèles légers pour l'analyse courante et garde le LLM pour l'interprétation des incidents complexes.
Et niveau coût ? Faire tourner des LLM pour analyser du Prometheus toute la journée, ça chiffre vite en tokens ou en GPU.
Est-ce que c'est vraiment rentable par rapport à un bête script bash avec des seuils fixes ?
Absolument. Un agent qui n'a pas de coupe-circuit n'est pas un outil DevOps, c'est une bombe à retardement.
Tu dois coupler l'agent à un contrôleur externe qui vérifie des invariants métier. Si le taux d'erreur dépasse un seuil critique, le contrôleur passe l'agent en mode
read-onlyou le tue.Intéressant le log
kubectl logs -f agent-controller-xyz. Mais concrètement, comment tu empêches un agent de devenir fou si la source Prometheus est corrompue ?Tu as prévu des mécanismes de circuit-breaker pour couper l'agent instantanément ?
Pas besoin de réinventer la roue. Le secret c'est de rester sur des standards Kubernetes. On utilise souvent des
Custom Resource Definitionspour que l'orchestrateur communique l'état désiré aux agents.Ça permet de garder une trace immuable de ce qui a été demandé dans
etcd.Le concept de flotte d'agents spécialisés est intéressant, mais ça ne rajoute pas une couche de complexité réseau ingérable ?
Tu communiques comment entre les agents ? Un bus de messages type NATS ou c'est plus léger ?
C'est tout le cœur du problème. Le manifeste que je montre avec le type
Goalest là pour ça. Tu ne donnes pas les clés du camion à l'IA sans garde-fous.La confiance se construit par la simulation. Il faut faire tourner l'agent en mode shadow pendant des semaines avant de lui laisser trigger un
kubectl rollout undotout seul.Franchement, l'idée de passer de l'impératif à l'intentionnel sur le papier c'est beau, mais en prod, qui gère les hallucinations de l'agent ?
Si mon agent décide de faire un
full_rollbackparce qu'il a mal interprété une latence réseau temporaire, c'est moi qui me fais réveiller à 3h du mat.