CPU cache misses : Le tueur silencieux de vos perfs
Votre moniteur de ressources système affiche un processeur saturé à 100 %, mais vos débits applicatifs s'effondrent lamentablement. Avant de blâmer votre framework asynchrone, d'accuser la base de données ou de provisionner des instances cloud hors de prix, vous devez lever le capot et observer ce qui se passe réellement au niveau du silicium. La triste réalité des architectures matérielles modernes est que votre processeur passe la majeure partie de son temps à ne rien faire, suspendu dans le vide en attendant que les données arrivent de la mémoire vive.
Ce phénomène d'attente, provoqué par les accès mémoire non optimisés, déclenche ce que l'on appelle des défauts de cache ou cache misses. Comprendre et maîtriser ce goulot d'étranglement invisible est la compétence ultime qui sépare les développeurs d'applications des ingénieurs système chevronnés capables de concevoir des systèmes à haute performance.
L'architecture mémoire moderne et la genèse du cache CPU
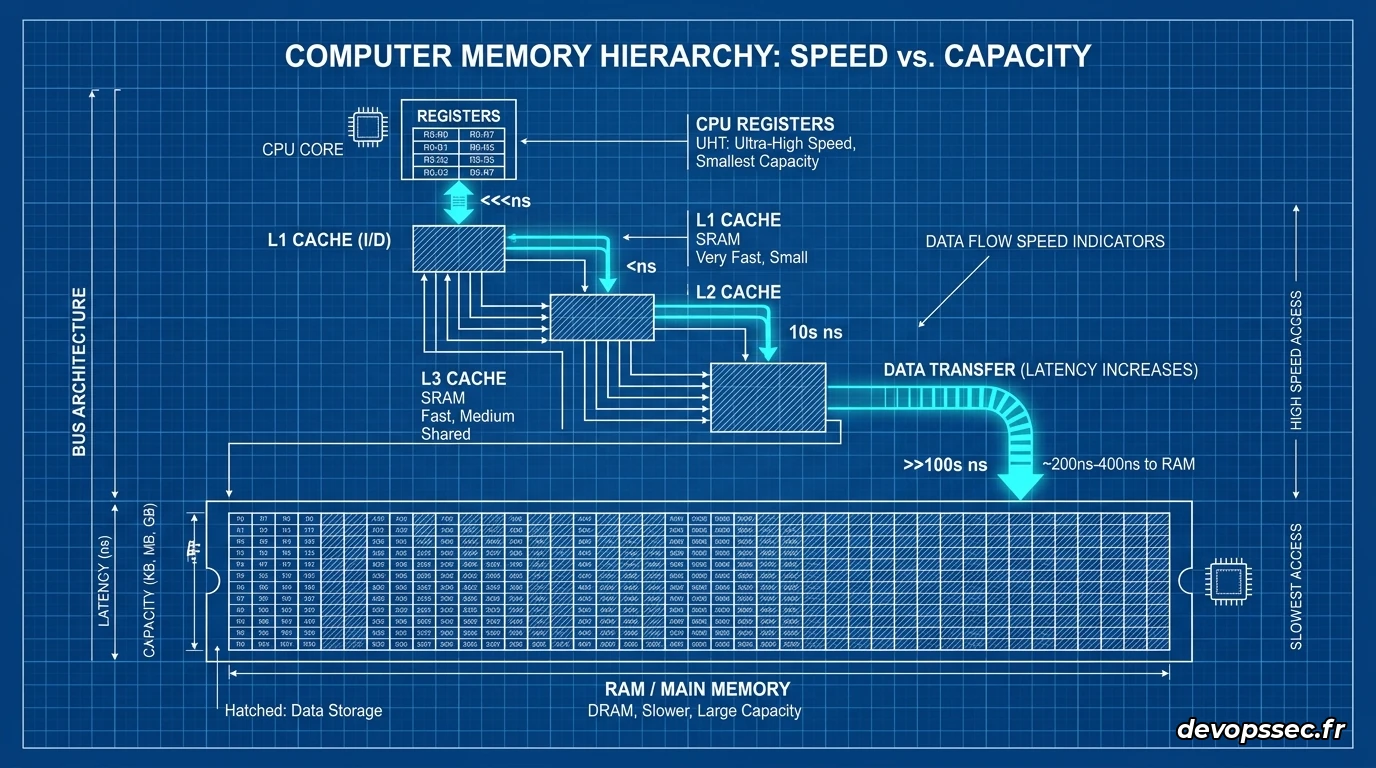
Le fossé technologique entre calcul et stockage
Au cours des dernières décennies, la vitesse de calcul de nos processeurs a augmenté de manière exponentielle, tandis que le temps d'accès à la mémoire RAM n'a progressé que très lentement. Pour combler ce fossé physique, les constructeurs ont intégré une hiérarchie de mémoire ultra-rapide directement sur la puce du processeur : les caches L1, L2 et L3.
Pour comprendre la physique du système, imaginez que le CPU est un chef cuisinier d'élite capable de découper un légume en une microseconde. Si les ingrédients sont sur sa planche de découpe (les registres), le travail est instantané. S'il doit ouvrir le tiroir juste sous son plan de travail (le cache L1), cela lui prend quatre secondes. S'il doit aller chercher un ingrédient dans le réfrigérateur au fond de la cuisine (le cache L3), cela demande une minute. Mais si l'ingrédient est resté au supermarché à l'autre bout de la ville (la mémoire RAM), le chef doit s'arrêter et attendre plusieurs heures.
Pour exploiter cette architecture matérielle, votre système d'exploitation Linux doit être configuré pour permettre l'accès aux compteurs de performance matériels du CPU. Le prérequis système indispensable est de configurer le niveau de restriction de l'API de profilage du noyau via la commande sysctl en positionnant la valeur kernel.perf_event_paranoid à 1 ou -1.
La localité des données et le fonctionnement de la cache line
Le processeur ne récupère jamais une information octet par octet dans la mémoire principale. Lorsqu'il a besoin d'une variable spécifique, le contrôleur mémoire rapatrie un bloc entier de données contiguës appelé cache line, dont la taille standard sur la quasi-totalité des architectures x86_64 et ARM64 modernes est de 64 octets.
Cette stratégie matérielle repose sur le principe de la localité spatiale, qui postule que si votre programme accède à une adresse mémoire spécifique, il y a de fortes chances qu'il accède très bientôt aux adresses adjacentes. Si vos structures de données sont éparpillées de manière désordonnée dans la mémoire, chaque lecture provoquera un voyage coûteux vers la RAM, détruisant l'efficacité de vos caches et gaspillant de précieuses lignes de cache pour des données inutilisées.

Le schéma ci-dessus illustre le cheminement des données et le coût temporel associé à chaque niveau d'interconnexion. Lorsqu'une donnée est présente dans le cache L1, le processeur l'exploite en un cycle d'horloge. À l'inverse, un échec de cache de dernier niveau (LLC, ou Last Level Cache) force le processeur à traverser le bus système pour interroger la RAM, une opération asymétrique majeure qui fige l'exécution de vos instructions durant des centaines de cycles.
Mesurer l'impact des cache misses en production
Le diagnostic de bas niveau avec perf-stat
Pour mesurer précisément ces frictions matérielles sans altérer le comportement de votre binaire, l'outil natif de l'écosystème Linux perf est indispensable. Il permet de lire directement les compteurs matériels PMU (Performance Monitoring Unit) intégrés au processeur.
En exécutant la commande d'analyse sur votre binaire en production, vous pouvez isoler les cycles CPU perdus en attente d'instructions ou de données.
perf stat -e L1-dcache-loads,L1-dcache-load-misses,LLC-loads,LLC-load-misses ./mon_application_highperfRésultat de la collecte système :
Performance counter stats for './mon_application_highperf':
1 452 301 240 L1-dcache-loads
185 240 102 L1-dcache-load-misses # 12.75% of all L1-dcache accesses
45 102 340 LLC-loads
9 845 101 LLC-load-misses # 21.83% of all LL-cache accesses
1.452031405 seconds time elapsedL'analyse de ce rapport révèle un problème critique : plus de 12 % des accès au cache de premier niveau échouent, et près de 22 % des requêtes vers le cache de dernier niveau (LLC) se transforment en requêtes directes vers la mémoire RAM. Une telle proportion signifie que votre processeur passe près de la moitié de son temps d'exécution à attendre des transferts d'octets.
Grille d'évaluation des métriques de cache
Pour vous aider à diagnostiquer la santé de vos applications, le tableau suivant résume les seuils d'alerte généralement admis par les ingénieurs système lors de l'analyse des métriques de cache.
| Métrique CPU | Zone Nominale | Zone de Danger | Impact Système Direct |
|---|---|---|---|
| Taux de miss L1 dcache | Moins de 5 % | Supérieur à 10 % | Perte d'efficacité des calculs intensifs sur les boucles de données. |
| Taux de miss LLC (L3) | Moins de 2 % | Supérieur à 5 % | Saturation du bus mémoire, latences extrêmes sur les requêtes d'I/O. |
| Instructions par Cycle (IPC) | Supérieur à 1.5 | Inférieur à 0.8 | Le processeur est inactif (stalled) la majorité du temps. |
Stratégies d'optimisation : Le Data-Oriented Design

La transition de la programmation objet vers l'orientation données
La programmation orientée objet traditionnelle nous pousse à concevoir nos systèmes sous forme de structures regroupant toutes les propriétés d'une entité métier. C'est l'approche dite de tableau de structures (Array of Structures ou AoS). Malheureusement, si vous devez uniquement mettre à jour un attribut de statut sur des millions d'entités, cette disposition mémoire force le CPU à charger également l'intégralité des autres données inutiles de chaque entité dans vos lignes de cache.
La méthodologie du Data-Oriented Design résout ce problème en réorganisant les données sous forme de structure de tableaux (Structure of Arrays ou SoA). Dans cette configuration, les attributs similaires sont regroupés de manière contiguë en mémoire vive. Lorsque le processeur effectue des opérations de mise à jour, chaque ligne de cache de 64 octets importée contient exclusivement les valeurs utiles, optimisant drastiquement le rendement de vos pipelines d'exécution.
Voici un exemple concret d'implémentation en langage Rust comparant les deux approches de gestion mémoire pour un système de traitement de données géographiques à haute performance.
// Approche classique AoS (Array of Structures) - Mauvaise gestion du cache
struct NodeAoS {
latitude: f64, // 8 octets
longitude: f64, // 8 octets
id: u64, // 8 octets
label: String, // 24 octets (pointeur, taille, capacité)
is_active: bool, // 1 octet
}
// Approche optimisée SoA (Structure of Arrays) - Cache-friendly
struct NodeSoA {
latitudes: Vec<f64>,
longitudes: Vec<f64>,
ids: Vec<u64>,
labels: Vec<String>,
active_flags: Vec<bool>,
}
impl NodeSoA {
// Calcule la distance moyenne uniquement pour les nœuds actifs
fn compute_average_latitude(&self) -> f64 {
let mut sum = 0.0;
let mut count = 0;
// Ici, le processeur charge des lignes de cache remplies à 100% de f64 contigus
// Aucun octet lié aux labels ou aux IDs ne vient polluer le cache L1
for (i, &lat) in self.latitudes.iter().enumerate() {
if self.active_flags[i] {
sum += lat;
count += 1;
}
}
if count == 0 { 0.0 } else { sum / (count as f64) }
}
}Dans l'approche SoA présentée ci-dessus, lors de l'itération sur les latitudes, le processeur peut charger huit valeurs décimales double précision en une seule lecture de ligne de cache de 64 octets. Si nous avions utilisé le modèle AoS, chaque nœud aurait nécessité l'importation de 64 octets en mémoire pour ne lire au final qu'un seul élément utile de 8 octets, gaspillant ainsi près de 87 % de la bande passante de notre cache.
Le piège perfide du faux partage en environnement multithread
Lorsque vous écrivez des applications concurrentes, une autre anomalie de performance redoutable liée au cache système peut survenir : le faux partage (false sharing). Ce problème survient lorsque deux processeurs distincts exécutant des threads différents modifient des variables indépendantes, mais que ces variables résident par mégarde à l'intérieur de la même ligne de cache de 64 octets.
Chaque fois qu'un processeur modifie une variable, le protocole de cohérence de cache du matériel (comme MESI) force l'invalidation immédiate de la ligne de cache entière pour tous les autres cœurs du système. Par conséquent, même si vos threads ne partagent logiquement aucune donnée, ils passent leur temps à s'échanger des droits d'écriture exclusifs sur la mémoire physique, effondrant les performances de votre architecture parallélisée.
Alerte Performance : Éviter le False Sharing
Pour prémunir vos architectures multithreads contre le faux partage, vous devez aligner explicitement vos variables concurrentes sensibles sur des frontières de lignes de cache de 64 octets. En Rust ou en C/C++, utilisez les attributs d'alignement matériel comme #[repr(align(64))] ou alignas(64) pour forcer le compilateur à isoler ces structures sur des lignes de cache indépendantes.
Maîtriser la mémoire pour libérer le processeur
Optimiser un système ne se limite plus aujourd'hui à réduire la complexité algorithmique brute de votre code. L'écart physique persistant entre la vitesse des processeurs et celle de la mémoire vive impose une rigueur absolue dans la façon dont vous agencez vos données en mémoire.
En adoptant les concepts de la localité des données, en traquant les défauts de cache avec perf et en restructurant vos objets complexes selon les principes de l'orientation données, vous éliminerez le goulot d'étranglement le plus pénalisant des architectures modernes. C'est à ce niveau de précision que se conçoivent les systèmes résilients et hautement performants de demain.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
Exactement. On a été trop longtemps protégés par la loi de Moore, mais là, on a atteint un plateau.
Maintenant, il faut comprendre le métal pour aller plus vite.
Le Data-Oriented Design, c'est le futur. Plus on avance, plus on comprend que le hardware dicte la loi.
Facile, utilise
alignas. Voici comment faire :Avec ça, ton compteur est tout seul sur sa ligne de cache.
Vous auriez un exemple de code pour aligner une structure en C++ ?
C'est très probable. Plus tu as de threads qui écrivent sur des variables adjacentes, plus le ping-pong entre les caches est violent.
Vérifie tes alignements de structures, c'est souvent là que ça se joue.
Je n'avais jamais pensé au false sharing. C'est pour ça que mes perfs s'écroulent dès que j'ajoute un thread de plus ?
C'est le problème classique. Si le cloud provider bloque, tu es coincé.
La solution c'est de demander une exception de sécurité ou d'utiliser des outils de profiling qui tournent en sidecar avec accès privilégié si la politique le permet.
Comment tu gères le
kernel.perf_event_paranoidsi t'es sur un cluster Kubernetes managé ?Souvent on n'a pas accès au sysctl du host.
JSON est une catastrophe pour les cache misses. Sérialiser/désérialiser des objets, c'est l'ennemi.
Si tu peux, passe sur du binaire type Protobuf ou FlatBuffers, c'est beaucoup plus proche de la mémoire.
Super instructif. Je vais enfin pouvoir justifier pourquoi je refuse de passer certains objets en JSON trop complexe dans des boucles critiques.
C'est un choix d'ingénierie arbitraire qui est devenu le standard industriel sur x86_64 et ARM64.
C'est le compromis idéal entre la latence de bus et la complexité des contrôleurs mémoire. C'est gravé dans le silicium, tu ne peux pas le changer.
Petite question bête : pourquoi 64 octets et pas une autre valeur ?
C'est lié à quoi exactement sur les architectures modernes ?
Clairement. Le GC est une machine à cache miss : il scanne les pointeurs partout en mémoire.
Si tu veux des mesures fiables, essaie de mesurer hors des cycles de GC ou utilise
GOGC=offpour un test de charge isolé.J'ai testé
perf statsur mon binaire Go, mais les chiffres me semblent bizarres.Est-ce que le garbage collector peut fausser les résultats de cache miss ?
C'est un compromis. Tu gagnes en perf brute ce que tu perds en lisibilité immédiate.
Garde le AoS pour la logique métier simple et passe au SoA uniquement sur les hot paths de ton application où le CPU passe 90% de son temps.
Le passage à SoA (Structure of Arrays) me fait peur pour la maintenance du code.
C'est pas un enfer à lire pour les nouveaux arrivants qui sont habitués aux objets classiques ?
Exactement. Avec
alignas(64), tu forces le compilateur à isoler tes données sur une ligne de cache dédiée.Ça empêche le protocole MESI de invalider le cache de l'autre thread inutilement. C'est radical.
Excellent article. J'ai un cas de false sharing violent sur un compteur de métriques thread-safe.
Si je comprends bien, le simple fait de mettre
alignas(64)sur ma struct devrait calmer le jeu côté CPU ?L'overhead est quasi nul, c'est du hardware pur. Le PMU (Performance Monitoring Unit) compte les événements en temps réel sans injecter de code supplémentaire.
Vas-y tranquille sur la prod, c'est indispensable pour voir si ton code est propre.
J'ai toujours cru que mon app ramait à cause de la DB. Je tombe des nues avec cette histoire de cache misses.
La commande
perf stat, c'est bien sûr les serveurs de prod ? Pas trop de overhead ?