L'Ère du Developer Productivity Engineering : Propulser l'Innovation DevOps
On a longtemps cru que le DevOps se résumait à l'automatisation des déploiements. Pourtant, le marché a mûri. Aujourd'hui, la vraie performance ne se mesure plus seulement à la vitesse de livraison, mais à la fluidité de l'expérience de ceux qui construisent le logiciel : les développeurs.
C'est dans ce contexte qu'émerge une discipline fondamentale, une véritable philosophie qui place l'ingénieur au centre de l'échiquier. Bienvenue dans l'ère du Developer Productivity Engineering (DPE), l'art de supprimer la friction pour libérer la créativité.
Le DPE, au-delà de l'outillage
Le Developer Productivity Engineering, ou DPE, n'est pas une nouvelle collection d'outils à la mode, mais une approche systémique visant à optimiser l'ensemble du cycle de vie du développement. Son objectif est de maximiser l'efficacité et la satisfaction des équipes techniques en s'attaquant à toutes les sources de ralentissement.
Il s'agit de considérer le temps et la charge cognitive des développeurs comme les ressources les plus précieuses de l'entreprise. Chaque minute passée à attendre un build, à débugger un environnement local instable ou à chercher une information est une minute perdue pour l'innovation.
Pourquoi cette discipline est-elle devenue cruciale ?
La complexité des architectures modernes, avec les microservices, le cloud natif et la multiplication des dépendances, a considérablement alourdi la charge mentale des développeurs. Le DPE répond à cette problématique en créant un écosystème de développement optimisé et cohérent.
Concrètement, la mission d'une équipe DPE s'articule autour de plusieurs axes fondamentaux qui transforment radicalement le quotidien des ingénieurs.
- Réduire les boucles de feedback : Fournir des retours sur la qualité du code, les tests et le déploiement en quelques minutes, et non en heures.
- Automatiser les tâches à faible valeur ajoutée : Éliminer le "toil", ces tâches manuelles, répétitives et sans valeur créative, comme la configuration d'environnements ou la gestion des dépendances.
- Fiabiliser et accélérer l'outillage : S'assurer que la chaîne d'intégration continue, les builds locaux et les tests sont non seulement rapides, mais aussi déterministes et fiables.
- Améliorer l'accès à l'information : Centraliser la documentation, les métriques de performance et les logs pour que le débogage et la compréhension du système soient intuitifs.
Les trois piliers d'une stratégie DPE réussie
Pour mettre en place une initiative DPE efficace, il faut agir sur trois leviers complémentaires. Isoler l'un de ces piliers sans considérer les autres ne produira que des résultats limités. C'est leur synergie qui crée un véritable cercle vertueux de productivité.
| Pilier | Objectif Principal | Exemples d'actions concrètes |
|---|---|---|
| Outillage et Automatisation | Fournir une chaîne d'outils rapide, fiable et intégrée. | Builds incrémentiels, caching distribué, gestion centralisée des secrets, environnements de prévisualisation à la demande. |
| Télémétrie et Observabilité | Mesurer pour améliorer. Rendre visible l'invisible. | Analyse de la durée des builds, suivi de la fiabilité des tests (flaky tests), collecte de métriques sur l'expérience développeur (DX). |
| Culture et Documentation | Favoriser le partage, l'autonomie et la connaissance. | Création de templates de projets ("starters"), documentation vivante et automatisée, mise en place de processus de contribution clairs. |
La chaîne d'outils au service de l'efficacité
Au cœur du DPE se trouve la chaîne d'outils, et plus particulièrement le pipeline de CI/CD. Mais ici, on ne parle plus seulement d'intégration et de déploiement continus. On parle d'une chaîne intelligente, consciente du contexte, qui sert de copilote au développeur.
Une CI/CD optimisée pour le feedback rapide
L'objectif premier d'un pipeline DPE est de réduire le temps entre une commande git push et l'obtention d'un retour clair et actionnable. Chaque seconde gagnée est une seconde de concentration préservée pour le développeur. Cela passe par des techniques avancées comme le caching des dépendances et des couches de build.
Imaginez un pipeline qui ne reconstruit que ce qui a changé, qui exécute les tests en parallèle sur plusieurs agents et qui provisionne un environnement de prévisualisation éphémère pour chaque pull request. C'est la promesse d'une CI/CD pensée pour la productivité.
# .gitlab-ci.yml - Exemple de pipeline avec optimisation DPE
stages:
- build
- test
- review
variables:
# Utilisation d'une image Docker optimisée et mise en cache
DOCKER_IMAGE: 'my-registry/app-builder:1.2.0'
build-app:
stage: build
image: $DOCKER_IMAGE
script:
- echo "Building the application..."
- ./scripts/build.sh
cache:
key: "$CI_COMMIT_REF_SLUG"
paths:
- node_modules/
- build/
policy: pull-push # Pousse le cache seulement si le job réussit
parallel-tests:
stage: test
image: $DOCKET_IMAGE
parallel: 4 # Exécute 4 jobs de test en parallèle
script:
- echo "Running tests partition {$CI_NODE_INDEX}/{$CI_NODE_TOTAL}"
- ./scripts/run_tests.sh --partition=$CI_NODE_INDEX --total=$CI_NODE_TOTAL
cache:
key: "$CI_COMMIT_REF_SLUG"
paths:
- node_modules/
- build/
policy: pull # Récupère le cache du build, mais ne le modifie pas
deploy-review-app:
stage: review
script:
- ./scripts/deploy_preview_env.sh --branch=$CI_COMMIT_REF_NAME
environment:
name: review/$CI_COMMIT_REF_NAME
url: https://$CI_COMMIT_REF_SLUG.review.example.com
on_stop: stop-review-app
stop-review-app:
stage: review
script:
- ./scripts/destroy_preview_env.sh --branch=$CI_COMMIT_REF_NAME
when: manual
environment:
name: review/$CI_COMMIT_REF_NAME
action: stopCe pipeline illustre des concepts clés : le caching pour éviter de retélécharger les dépendances à chaque fois, et la parallélisation pour diviser le temps d'exécution des tests par quatre. L'environnement de revue dynamique permet une validation fonctionnelle immédiate, sans attendre une mise en production.
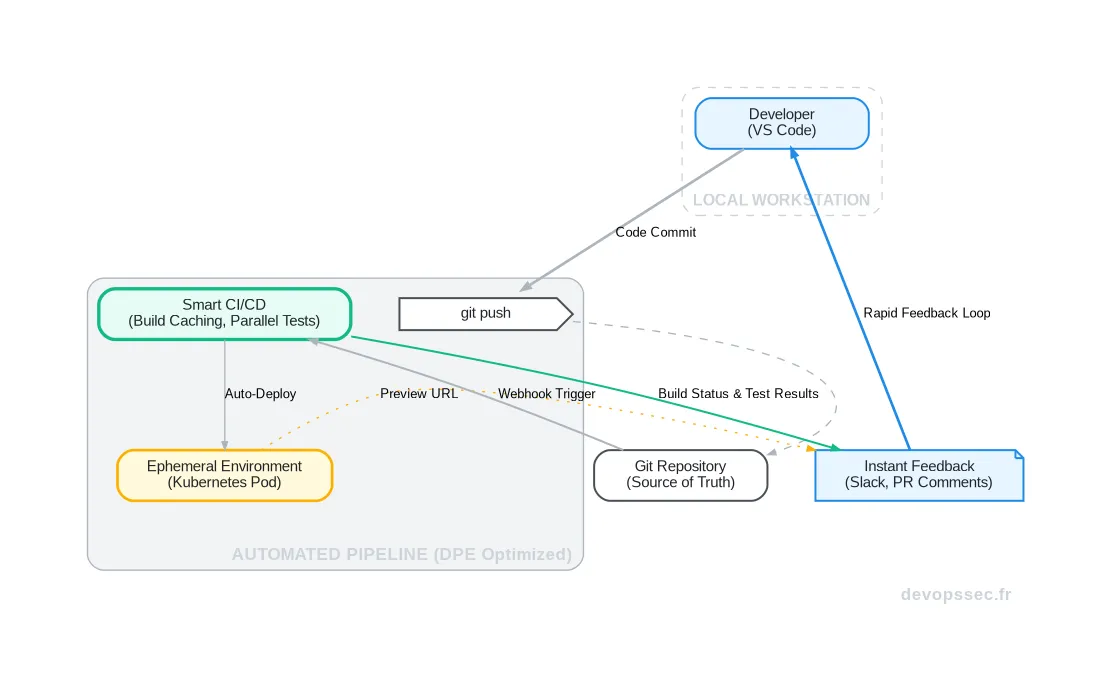
Ce schéma illustre parfaitement la boucle de feedback rapide que le DPE cherche à instaurer. Le développeur pousse son code et reçoit quasi-instantanément un ensemble complet d'informations : le statut du build, les résultats des tests et une URL fonctionnelle pour valider son travail. La friction est minimisée, le cycle itératif est accéléré.
Les Risques et Coûts cachés du DPE
Si la promesse du DPE est séduisante, sa mise en œuvre n'est pas sans défis. L'un des principaux risques est de tomber dans le piège de la sur-ingénierie, en construisant des usines à gaz pour résoudre des problèmes simples. Une équipe DPE doit rester pragmatique et toujours mesurer l'impact réel de ses initiatives.
Par ailleurs, la création d'une équipe dédiée au DPE représente un investissement significatif. Ces ingénieurs, souvent très expérimentés, ne travaillent pas directement sur le produit final, ce qui peut rendre la justification de leur coût difficile auprès du management. Leur R.O.I. se mesure indirectement, par l'accélération de toutes les autres équipes.
Commencez petit et mesurez tout
N'essayez pas de tout révolutionner d'un coup. Identifiez le principal point de friction de vos équipes (ex: la lenteur des builds locaux) et concentrez-vous dessus. Mettez en place des métriques claires avant et après votre intervention pour prouver la valeur ajoutée de votre action.
Enfin, l'Observabilité du processus de développement lui-même est un domaine complexe. Collecter les bonnes métriques sans devenir intrusif est un équilibre délicat. L'objectif est d'aider les développeurs, pas de les surveiller. La transparence et la communication sont essentielles pour obtenir leur adhésion.
Conclusion : Un investissement dans votre capital humain
En définitive, le Developer Productivity Engineering est bien plus qu'une simple tendance technique. C'est un changement de paradigme qui reconnaît que la ressource la plus précieuse d'une organisation technologique est le temps et l'énergie de ses ingénieurs.
Investir dans le DPE, c'est investir dans un environnement de travail où la frustration laisse place à la fluidité, où l'attente est remplacée par l'action, et où la créativité peut enfin s'exprimer sans entraves. C'est la clé pour attirer, retenir les meilleurs talents et, finalement, livrer plus rapidement des produits de meilleure qualité.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
25 commentaires
On continue d'itérer sur ces points. Le retour sur l'investissement du DPE se voit sur le long terme, quand les devs arrêtent de se plaindre de la lenteur de la CI et se concentrent sur la valeur métier.
La théorie sert à aligner les équipes. Sans vision commune, chacun fait son petit script dans son coin, et on se retrouve avec une dette technique monstrueuse sur l'outillage.
Le DPE, c'est juste redonner aux devs le contrôle sur leur environnement. Si tu leur donnes des outils qui marchent sans friction, ils seront plus efficaces, point. Pas besoin de théoriser autant.
Parce que le cache natif ne suffit pas dans une CI distribuée. Il faut le persister, le partager entre agents et le purger intelligemment. C'est là que le DPE intervient.
L'article mentionne le "caching des dépendances". Si vous utilisez
npmouyarn, le cache est déjà géré nativement. Pourquoi en faire tout un plat dans une stratégie DPE ?Je suis d'accord, le DPE n'exclut pas la qualité du code. Mais si le développeur est frustré par un build lent, il n'aura aucune motivation pour optimiser quoi que ce soit. C'est une question d'environnement de travail.
C'est ça. Priorités inversées. Le DPE devrait commencer par apprendre aux devs à écrire du code qui performe, pas juste à faire des pipelines de build ultra-rapides pour du code médiocre.
Le danger avec votre approche, c'est la sur-ingénierie. J'ai vu des équipes passer des semaines à optimiser un pipeline pour gagner 30 secondes par build, alors que le code lui-même est lent à cause d'une requête N+1 dans la base de données.
L'humain oublie, le code non. Si la doc est générée depuis le code, elle est au moins cohérente. On ne cherche pas à remplacer l'humain, mais à éviter qu'il perde du temps sur des tâches automatisables.
+1. Et la doc automatisée, c'est souvent du vent. Rien ne vaut un
README.mdmis à jour par un humain qui comprend ce qu'il a écrit.Le DPE c'est surtout un truc pour les grosses boîtes avec trop de cash. En startup, on fait du
docker-compose upet basta. Arrêtez de nous vendre des solutions de niveau FAANG pour nos projets de taille moyenne.C'est une question de compromis. Soit tu paies en cloud, soit tu paies en temps dev. Le calcul est souvent en faveur du cloud si tu diminues le temps d'attente pour une validation.
Le souci avec les "environnements éphémères" cités dans l'article, c'est le coût en cloud. Si chaque PR génère un env, tu exploses ta facture
awsà la fin du mois. Qui paie la note ?Le refactoring prend du temps. Le DPE permet de libérer ce temps en automatisant le toil. C'est un cercle vertueux, pas une excuse. On ne peut pas tout réécrire du jour au lendemain.
Exactement. On passe notre temps à automatiser des trucs qui ne devraient même pas exister. Le DPE ça sonne comme une excuse pour ne pas refactorer le legacy.
200 microservices, c'est déjà un échec architectural en soi, pas un problème de DPE. Vous essayez de mettre des pansements sur une jambe de bois.
C'est exactement le point : commencer par le simple. Le DPE c'est une culture, pas une montagne de tools. Si ton
package-lock.jsonsuffit, c'est parfait. Mais quand tu as 200 microservices, tu as besoin d'une stratégie globale.Pour ceux qui veulent voir à quoi ressemble une gestion de cache correcte sans tomber dans le complexe, voilà ce qu'on fait pour éviter les erreurs de build :
C'est simple, efficace, pas besoin d'une équipe dédiée de 5 personnes pour maintenir ça.
La télémétrie, c'est bien, mais qui regarde les métriques ? On finit avec 50 dashboards
grafanaque personne ne consulte. C'est du bruit. Il faut des alertes actionnables, pas des statistiques pour flatter le management.Les tests instables sont le symptôme d'une mauvaise architecture. Le DPE permet justement d'exposer ces problèmes via la télémétrie. Si un test est instable, on ne le cache pas, on le rend visible dans les dashboards pour le corriger.
D'accord avec @3. L'exemple du pipeline avec
parallel-testsc'est mignon, mais en prod, tes tests deviennent dépendants entre eux et tu te retrouves avec des flaky tests à n'en plus finir. Comment tu gères ça avec ton DPE ?"Réduire la charge cognitive", joli mot. En vrai, c'est souvent rajouter une couche d'abstraction supplémentaire avec des outils propriétaires. J'ai vu des équipes passer plus de temps à maintenir leur usine à gaz de CI qu'à coder des features.
Le DPE ne remplace pas le DevOps, il le cadre. Le but n'est pas de faire des outils pour le plaisir, mais de réduire la charge cognitive. Si ton build prend 30 minutes, le développeur perd son focus. C'est ça qu'on attaque.
Le problème c'est pas l'outil, c'est la complexité qu'on ajoute. Le DPE ça finit toujours par créer une équipe dédiée qui fait des outils que personne ne veut utiliser. Si tu dois faire un
cachedistribué pour ton build, c'est que ton architecture est déjà trop couplée.Encore un énième buzzword pour dire qu'on doit mieux configurer nos pipelines. Le DPE, c'est juste du DevOps avec un budget marketing en plus. On a déjà
jenkinsougitlab-ci, faut juste arrêter de pondre des scripts shell de 500 lignes.