Une page pour les gouverner toutes : l'illusion des 4 Ko
À chaque seconde qui s'écoule, vos serveurs de production accomplissent un miracle silencieux : traduire des milliards d'adresses de mémoire virtuelle en adresses physiques réelles. Pourtant, cette chorégraphie logicielle cache une taxe invisible mais dévastatrice sur vos performances CPU, causée par une relique du passé : la page standard de 4 Ko. À l'époque où les serveurs disposaient de 16 Mo de mémoire vive, découper la mémoire en petits blocs de 4 Ko était une excellente idée pour éviter le gaspillage. Aujourd'hui, sur une machine moderne équipée de 256 Go de RAM, ce découpage archaïque force le noyau Linux à jongler avec plus de 67 millions de pages individuelles, saturant les circuits de traduction du processeur.
Pour résoudre ce goulot d'étranglement matériel, les ingénieurs système exploitent les Hugepages, des blocs de mémoire de taille géante (généralement 2 Mo ou 1 Go sous Linux). Comprendre les Hugepages, ce n'est pas seulement activer une option dans un fichier de configuration, c'est plonger au cœur du silicium pour redéfinir la manière dont le noyau Linux dialogue avec vos barrettes de RAM. Cet article vous propose une immersion sans concession sous le capot de la gestion mémoire, pour transformer vos applications gourmandes en monstres de fluidité.
Genèse et Architecture de la Mémoire Virtuelle

Pour comprendre l'intérêt des Hugepages, il faut d'abord analyser la manière dont le processeur accède à la mémoire. Une application n'accède jamais directement à la RAM physique ; elle manipule des adresses virtuelles fournies par le système d'exploitation. C'est la MMU (Memory Management Unit), un composant matériel soudé au cœur du CPU, qui se charge de traduire ces adresses virtuelles en adresses physiques à la volée. Cette traduction s'appuie sur une structure de données arborescente stockée en RAM appelée la table des pages.
Le TLB et le fardeau des pages de 4 Ko
Parce que lire la table des pages en RAM à chaque accès mémoire est beaucoup trop lent, le processeur utilise un cache ultra-rapide et ultra-coûteux directement intégré dans ses circuits : le Translation Lookaside Buffer (TLB). Considérez le TLB comme un carnet d'adresses de poche contenant les traductions les plus récentes. Si l'adresse recherchée s'y trouve, c'est un TLB hit, et la traduction est quasi instantanée. Si elle n'y est pas, c'est un TLB miss : le CPU doit interrompre ses calculs, parcourir la lente table des pages en RAM, puis inscrire la nouvelle adresse dans le TLB en écrasant une entrée existante.
Avec des pages standard de 4 Ko, une application qui utilise 16 Go de mémoire vive nécessite 4 millions d'entrées dans la table des pages. Le TLB, dont la capacité physique dépasse rarement quelques milliers d'entrées sur les architectures modernes, se retrouve instantanément saturé. Le CPU passe alors une partie phénoménale de son temps à chercher où se trouvent les données plutôt qu'à exécuter du code applicatif. En passant à des Hugepages de 2 Mo, ces mêmes 16 Go de mémoire ne nécessitent plus que 8 192 entrées, qui tiennent désormais presque intégralement dans le cache du processeur.
Prérequis noyau pour l'activation des Hugepages
L'utilisation des Hugepages nécessite un support direct de la part du noyau Linux et une architecture matérielle compatible. Heureusement, la quasi-totalité des architectures x86_64 modernes supporte nativement des tailles de pages de 2 Mo et 1 Go. Du côté du noyau, les fonctionnalités de mémoire partagée et de pagination avancée doivent être activées. Vous pouvez vérifier la compatibilité de votre processeur en inspectant les drapeaux système renvoyés par le processeur.
Pour vous assurer que votre noyau est prêt à allouer des Hugepages, il suffit de vérifier la présence des flags pse (Page Size Extension, pour le support des pages de 2 Mo) et pdpe1gb (pour le support des pages de 1 Go) dans les informations du processeur. Cette étape préliminaire valide que le matériel sous-jacent est capable de découper l'espace d'adressage selon ces dimensions géantes.
Mécanismes Internes : Static vs Transparent Huge Pages (THP)
Le noyau Linux propose deux approches radicalement différentes pour gérer ces grands blocs de mémoire : la méthode statique et la méthode dynamique (appelée THP). Choisir la mauvaise approche pour votre charge de travail peut non seulement réduire à néant vos gains de performances, mais aussi provoquer des effondrements catastrophiques de votre système d'exploitation.
Le dilemme de la fragmentation mémoire
Pour allouer une Hugepage de 2 Mo ou de 1 Go, le noyau Linux doit impérativement trouver un espace d'adressage physique contigu dans la RAM. Si votre mémoire physique ressemble à un gruyère à cause de milliers de petites allocations de 4 Ko dispersées, le noyau sera incapable de rassembler assez d'espace d'un seul tenant pour créer une Hugepage, même s'il vous reste plusieurs gigaoctets de mémoire libre au total. C'est le phénomène de la fragmentation physique.
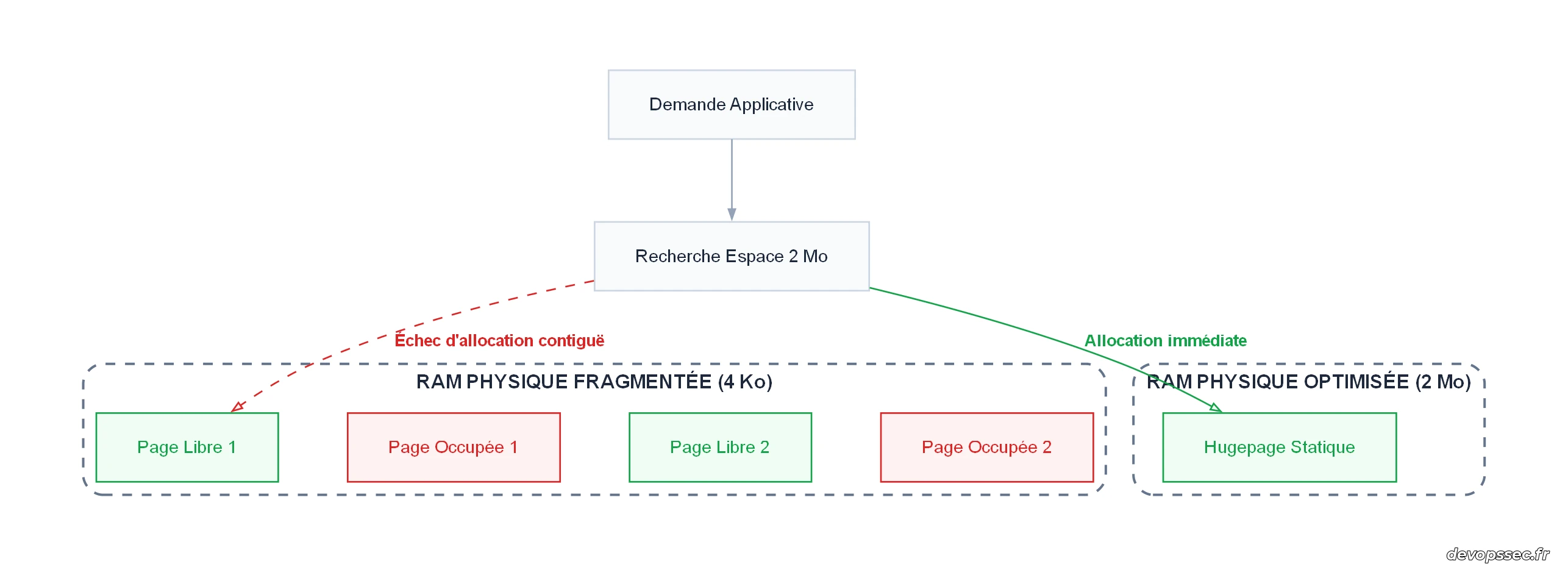
Le schéma ci-dessus met en lumière le défi majeur auquel fait face le gestionnaire de mémoire du noyau. Lorsque la RAM est fragmentée par des allocations standard désordonnées, la recherche d'un bloc contigu de 2 Mo échoue inévitablement, forçant le système à basculer sur des mécanismes de compactage coûteux en ressources CPU. À l'inverse, la réservation d'un espace dédié et étanche garantit une allocation immédiate et sans latence.
La guerre des tranchées : Static vs Transparent Huge Pages
Pour résoudre ce problème d'allocation, deux philosophies s'affrontent. La première, les Static Hugepages, consiste à demander au noyau de réserver un nombre fixe de Hugepages dès le démarrage du serveur. Cette mémoire est alors sanctuarisée : elle est retirée de la mémoire générale utilisable par le système et réservée exclusivement aux applications configurées pour l'utiliser. C'est l'approche la plus stable et la plus performante pour les charges de travail prévisibles.
La seconde approche, appelée Transparent Huge Pages (THP), est une tentative du noyau Linux d'automatiser ce processus. Un démon en arrière-plan (khugepaged) tente de repérer les allocations contiguës de 4 Ko pour les fusionner dynamiquement en Hugepages de 2 Mo sans que l'application n'ait à modifier son code. Si l'idée est séduisante sur le papier, elle s'avère catastrophique pour les bases de données. En effet, lorsque la mémoire est fragmentée, le démon THP bloque temporairement l'exécution de l'application pour réorganiser la RAM à la volée, provoquant des pics de latence massifs et imprévisibles.
Alerte Performance Production
Sur les serveurs hébergeant des bases de données comme PostgreSQL, Redis ou MongoDB, il est impératif de désactiver complètement les Transparent Huge Pages (THP) pour éviter des freezes applicatifs sporadiques liés aux opérations de compactage du noyau.
Cas d'Usage Avancé : Optimisation pour une Base de Données PostgreSQL
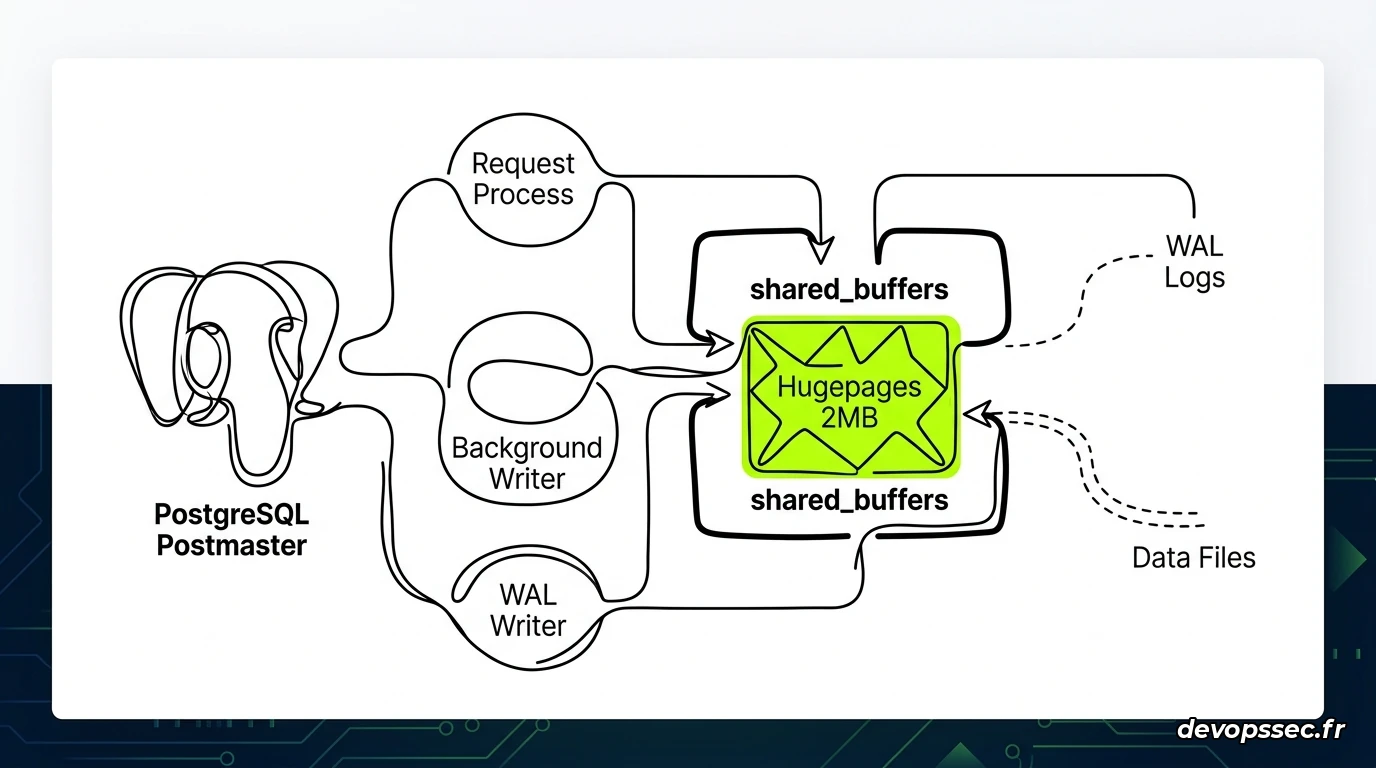
Mettons maintenant ces concepts en pratique en configurant un serveur de production hébergeant une base de données PostgreSQL de taille critique. PostgreSQL utilise une vaste zone de mémoire partagée appelée shared_buffers pour mettre en cache les tables et les index fréquemment consultés. C'est le candidat idéal pour l'implémentation de Hugepages statiques.
Dimensionnement et calcul de la mémoire
Avant d'activer quoi que ce soit, nous devons calculer précisément le nombre de Hugepages de 2 Mo dont notre instance PostgreSQL a besoin. Si nous réservons trop peu de pages, PostgreSQL refusera tout simplement de démarrer. Si nous en réservons trop, nous gaspillerons de la mémoire précieuse que le reste du système d'exploitation ne pourra jamais récupérer. La formule de base consiste à diviser la taille de notre zone de mémoire partagée par la taille d'une Hugepage, tout en ajoutant une marge de sécurité pour les processus internes de la base.
Pour un serveur doté de 64 Go de RAM, nous configurons généralement les shared_buffers à 25 % de la mémoire totale, soit 16 Go. Convertissons ces 16 Go en kilo-octets pour correspondre aux unités de notre système d'exploitation : 16 * 1024 * 1024 = 16 777 216 Ko. Une Hugepage standard mesurant 2 048 Ko, le besoin strict est de 16 777 216 / 2 048 = 8 192 pages. Pour éviter toute erreur d'allocation lors de l'initialisation des structures de contrôle de PostgreSQL, nous appliquerons une marge de sécurité d'environ 10 %, ce qui nous donne une cible de 9 011 pages.
Déploiement de la configuration de production
Nous allons maintenant configurer notre système Linux de manière pérenne. Nous devons d'abord configurer les paramètres de sécurité pour autoriser le groupe système de PostgreSQL à verrouiller de grands blocs de mémoire en RAM. Nous allons ensuite déclarer notre réservation de Hugepages statiques directement dans la configuration du noyau via l'outil sysctl, puis configurer PostgreSQL pour qu'il exige l'usage exclusif de ces pages réservées.
Commençons par modifier le fichier de sécurité des limites système pour notre utilisateur postgres afin qu'il puisse allouer de la mémoire partagée de manière illimitée :
# Ajout des règles de verrouillage mémoire dans /etc/security/limits.d/90-postgres-hugepages.conf
postgres soft memlock unlimited
postgres hard memlock unlimitedEnsuite, nous allons configurer le noyau pour qu'il réserve notre quota de Hugepages au démarrage de la machine, garantissant ainsi que nous disposerons d'un espace physique parfaitement contigu avant que la mémoire ne commence à se fragmenter. Ouvrez et éditez le fichier de configuration des paramètres système :
# Configuration des paramètres noyau dans /etc/sysctl.d/99-hugepages.conf
vm.nr_hugepages = 9011
# Réduction de l'agressivité de la récupération de mémoire pour éviter les swaps intempestifs
vm.swappiness = 10Résultat:
# Application immédiate des modifications système sans redémarrage
$ sudo sysctl -p /etc/sysctl.d/99-hugepages.conf
vm.nr_hugepages = 9011
vm.swappiness = 10La dernière étape consiste à configurer PostgreSQL pour qu'il utilise obligatoirement ces ressources. Dans le fichier de configuration de votre instance de base de données, ajustez les paramètres suivants pour imposer un comportement strict. Si le système d'exploitation ne peut pas fournir les Hugepages demandées, l'instance refusera de s'exécuter plutôt que de basculer silencieusement sur des pages standard dégradées :
# Configuration au sein de /etc/postgresql/shared/postgresql.conf
shared_buffers = 16GB
huge_pages = on # Options possibles : on, off, try. Nous forçons l'activation stricte.Après un redémarrage de l'instance PostgreSQL, le processus va s'associer directement au segment de mémoire partagée pré-alloué par le système. Les gains en production se feront immédiatement ressentir : réduction des cycles CPU consommés par le noyau (sys % dans votre outil htop) et augmentation globale du débit de transactions par seconde (TPS) grâce à l'élimination quasi totale des micro-latences induites par les échecs du TLB.
Diagnostic et Observabilité du Système
Une fois votre configuration déployée, vous devez être capable de valider son fonctionnement réel et de surveiller l'état de votre mémoire pour prévenir les défaillances. Le noyau Linux expose l'intégralité de ces mesures à travers son système de fichiers virtuel, ce qui nous permet d'inspecter l'état de la RAM en temps réel sans perturber la production.
Monitoring en temps réel avec le système de fichiers /proc
Le fichier spécial /proc/meminfo contient toutes les réponses à nos questions sur l'état d'allocation de la mémoire physique. Nous pouvons cibler spécifiquement les variables liées aux Hugepages pour nous assurer que nos configurations ont été correctement interprétées par le noyau Linux et que notre base de données les utilise activement.
Exécutons une commande de diagnostic pour inspecter les compteurs du gestionnaire de mémoire :
# Lecture ciblée des statistiques de mémoire globale
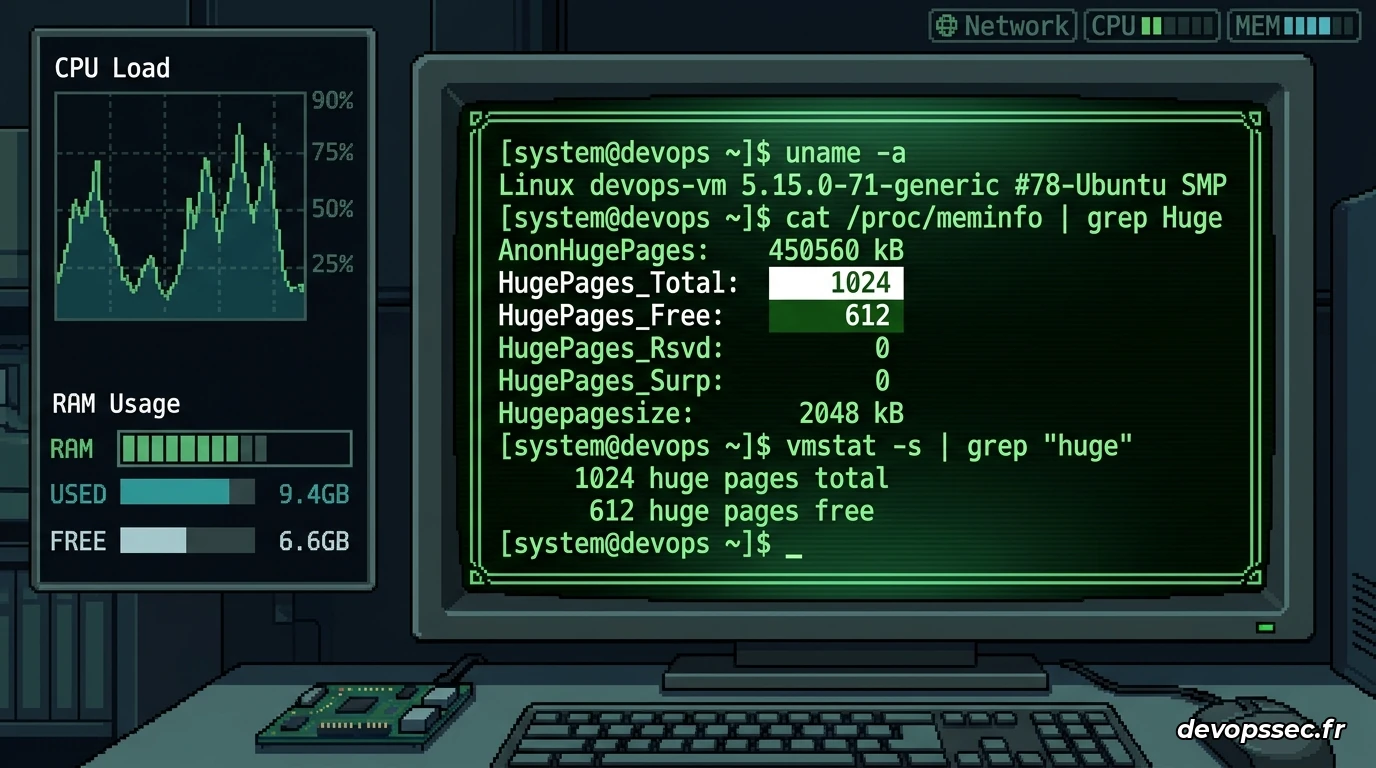
$ grep -i huge /proc/meminfoRésultat:
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 9011
HugePages_Free: 819
HugePages_Rsvd: 819
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 18454528 kBDécortiquons ces valeurs pour en comprendre la portée opérationnelle. Le paramètre HugePages_Total confirme que le noyau Linux a bien réservé nos 9 011 pages de 2 Mo au démarrage. La ligne HugePages_Free indique qu'il reste 819 pages disponibles et non encore utilisées pour l'écriture de données. Enfin, le compteur critique HugePages_Rsvd (Reserved) montre que 819 pages ont été promises à notre processus PostgreSQL pour ses besoins de traitement futurs. Cet équilibre parfait indique que notre base de données exploite pleinement le réservoir de mémoire rapide qui lui a été alloué, libérant ainsi le processeur de sa lourde charge de traduction d'adresses.
Maîtriser la mémoire pour libérer la puissance
La gestion de la mémoire sous Linux est un équilibre fragile entre abstraction logicielle et contraintes matérielles. En arrachant vos applications critiques à la tyrannie des pages par défaut de 4 Ko, vous réduisez considérablement l'empreinte du système d'exploitation sur vos performances CPU globales. L'adoption des Hugepages statiques, bien qu'exigeante en termes de rigueur opérationnelle et de calculs préalables, s'impose comme une étape incontournable pour quiconque souhaite pousser ses infrastructures de production dans leurs derniers retranchements.
En tant qu'ingénieur système senior, je ne peux que vous encourager à tester cette configuration sur vos environnements hors-production, à mesurer le taux d'occupation de votre cache TLB avant et après modification, et à observer vos graphiques d'utilisation CPU s'aplatir. Le voyage au cœur du noyau Linux est complexe, mais les gains d'efficacité énergétique et de vélocité applicative récompensent toujours ceux qui osent soulever le capot.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
D'ailleurs, pour ceux qui veulent automatiser, passez par un script d'init ou une unité systemd qui check le niveau de fragmentation avant d'appliquer les valeurs.
Ne faites pas ça à la main sur une infra critique sans un plan de rollback.
Tu as réservé 9011 * 2 Mo = ~18 Go de RAM d'un coup.
Si ton système n'avait pas assez de mémoire libre, le noyau a probablement tué des processus (OOM Killer) pour satisfaire ta demande de réservation. Toujours vérifier la RAM dispo avant de toucher au sysctl.
J'ai utilisé
vm.nr_hugepages = 9011comme suggéré, mais j'ai eu unOut of Memorymassif juste après.C'est normal que le noyau panique comme ça ?
Sur 16 Go, n'en réserve pas trop. Calcule tes
shared_buffers, ajoute une petite marge et c'est tout.C'est de la gestion de ressources, pas de la magie. Si tu réserves 8 Go sur 16, le système va souffrir, c'est évident.
Est-ce que ça vaut le coup sur des serveurs avec seulement 16 Go de RAM ?
J'ai peur que la réservation des Hugepages statiques me bloque tout le système pour le reste.
Si
AnonHugePagesest élevé, c'est que tes THP sont encore activés.Vérifie ton fichier de config :
Si c'est sur
[always]ou[madvise], coupe ça tout de suite.Merci pour l'astuce du
grep -i huge /proc/meminfo.Je viens de checker sur un serveur de prod, j'ai
AnonHugePagesà une valeur énorme. C'est pas censé être 0 si on a désactivé les THP ?Si tu es sur une instance cloud, c'est souvent bridé par l'hyperviseur.
Si ça n'apparaît pas dans
/proc/cpuinfo, c'est que ton instance ne supporte pas les pages de 1 Go. Reste sur du 2 Mo, c'est déjà très bien pour 99% des cas.Question bête : comment on vérifie que le flag
pdpe1gbest bien actif sur nos instances cloud ?J'ai fait un
grepsur/proc/cpuinfomais je ne vois rien.Totalement. THP c'est une hérésie sur des environnements multi-tenants.
Ça essaie de compacter la mémoire de tout le monde, ça lock des pages, et au final tu te retrouves avec des pics de latence sur tes applications à cause du démon
khugepagedqui s'excite.Petit retour d'expérience : désactiver les THP sur des clusters Kubernetes avec beaucoup de pods, c'est indispensable.
Sinon, les latences sur les accès disque sont injouables dès que la mémoire est un peu sollicitée.
On a vu des gains nets sur les temps de pause GC chez nous. Moins de TLB misses = moins de temps passé en mode kernel, donc le CPU est plus dispo pour le GC.
Par contre, attention à la config
-XX:+UseLargePagesdans les options de la JVM, sinon ça sert à rien.Quelqu'un a testé l'impact sur le garbage collector de Java avec les Hugepages ?
Sur nos grosses instances, on a l'impression que ça aide à réduire les pauses, mais c'est dur à quantifier.
Exactement. C'est pour ça qu'on les définit au boot via
sysctl.Si tu essaies d'allouer ça sur un serveur qui tourne depuis des lustres, tu vas juste avoir des erreurs d'allocation. Le reboot est ton meilleur ami ici.
Clair. Et pour la fragmentation, vous faites comment si le serveur tourne depuis 6 mois ?
Si la RAM est déjà en mode gruyère, le noyau va galérer à allouer les Hugepages statiques, non ?
C'est le jeu de la stabilité vs flexibilité. Si tu veux de la perf garantie, tu acceptes le risque de l'échec au boot.
Utilise
huge_pages = trydans tonpostgresql.confau début pour tester, mais en prod, leonest obligatoire pour éviter le mode dégradé silencieux.Super article. Par contre, le coup du
vm.nr_hugepagesqui empêche le démarrage de la DB si pas assez de RAM, c'est un coup à se faire réveiller par l'astreinte à 3h du mat.Y'a pas un moyen plus safe pour éviter de tout casser au reboot ?