Les variables CI/CD dans GitLab : Dynamiser vos automatisations
Le moteur de personnalisation de vos pipelines
Dans un pipeline automatisé, vous avez souvent besoin de manipuler des informations qui changent d'un projet à l'autre ou d'un environnement à l'autre. Pour gérer cela, GitLab utilise les Variables CI/CD.
Imaginez que vos variables sont des étiquettes intelligentes collées sur votre code. Au lieu d'écrire "en dur" le nom de votre serveur dans vos scripts, vous utilisez une étiquette nommée $CI_ENVIRONMENT_URL. Le système remplacera automatiquement cette étiquette par la bonne valeur au moment de l'exécution. De nos jours, cette flexibilité est la base de l'infrastructure as code.
Visualiser les variables en action
Il est très facile de voir ce que contiennent ces variables en ajoutant une simple commande d'affichage dans votre fichier .gitlab-ci.yml.
Exemple de configuration YAML
test_job:
stage: test
script:
- echo "Je travaille sur la branche $CI_COMMIT_REF_NAME"
- echo "L'ID du projet est $CI_PROJECT_ID"Sortie terminal :
Running with gitlab-runner 17.10.0
[...]
$ echo "Je travaille sur la branche $CI_COMMIT_REF_NAME"
Je travaille sur la branche main
$ echo "L'ID du projet est $CI_PROJECT_ID"
L'ID du projet est 456782
Job succeededListe des variables prédéfinies GitLab
GitLab fournit par défaut une liste impressionnante de variables prêtes à l'emploi que vous pouvez retrouver sur la documentation officielle. Voici les plus courantes pour piloter vos builds :
| Variable | Description |
|---|---|
| CI_COMMIT_REF_NAME | Le nom de la branche (ex: main) ou du tag utilisé pour le build. |
| CI_COMMIT_SHA | L'identifiant complet (hash) du commit en cours de traitement. |
| CI_JOB_ID | L'identifiant unique du job actuel dans GitLab. |
| CI_PROJECT_DIR | Le chemin complet où le dépôt a été cloné sur le Runner. |
| CI_REGISTRY_IMAGE | L'adresse du registre Docker propre à votre projet. |
| GITLAB_USER_EMAIL | L'adresse email de l'utilisateur qui a déclenché le pipeline. |
Variables de groupe et de projet
Au-delà des variables automatiques, vous pouvez créer vos propres variables (clés d'API, mots de passe de base de données) directement dans l'interface GitLab pour ne pas les afficher en clair dans votre code. Ces éléments critiques sont généralement gérés par les utilisateurs ayant le rôle Maintainer.
- Allez dans Settings > CI/CD.
- Dépliez la section Variables.
- Cliquez sur Add variable.
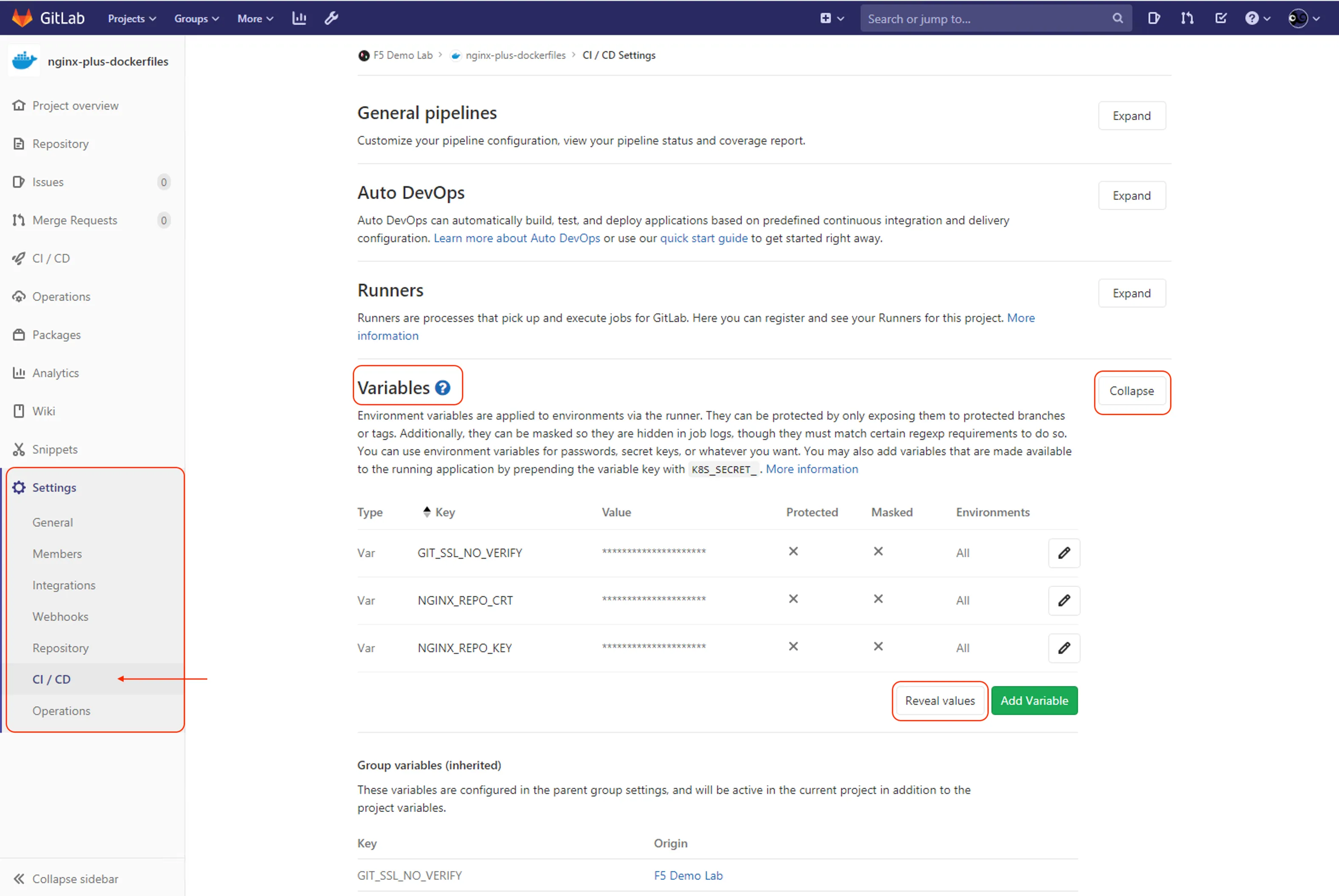
"Interface d'ajout de variables personnalisées dans GitLab"
Sécurité : Masked & Protected
Pour vos secrets, utilisez toujours l'option Masked. Cela permet de cacher la valeur de la variable dans les logs de la console (elle sera remplacée par [MASKED]) pour éviter que vos mots de passe ne soient visibles par toute l'équipe.
Conclusion
Les variables CI/CD transforment vos pipelines statiques en outils dynamiques capables de s'adapter à n'importe quelle situation. C'est l'outil indispensable pour gérer vos déploiements sur différents environnements (Staging, Production) sans erreur humaine.
Maintenant que vous savez manipuler les données de vos jobs, nous allons voir comment sécuriser tout cela. Dans le prochain chapitre, nous allons détailler les Permissions spécifiques à GitLab CI.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
22 commentaires
Pas de souci. Pense à bien tester tes pipelines sur une branche dédiée avant de push sur
mainpour éviter les fausses manips.Ok, le problème de scope était bien là. Merci.
T'as bien vérifié le scope ? Si elle est définie sur un autre groupe ou projet, elle ne sera pas dispo ici. Check aussi l'option Protected, elle empêche l'accès sur les branches non protégées.
J'ai une erreur 'variable not found' sur une variable que j'ai pourtant définie dans Settings > CI/CD.
Oui, ça renverra l'email du compte qui a fait le push ou le déclenchement. Si c'est un Deploy Token, c'est différent.
Est-ce que
GITLAB_USER_EMAILchange si c'est un bot qui déclenche le pipeline ?Utilise les
artifactsavec un fichierdotenv. C'est la méthode propre :Quelqu'un sait comment passer une variable dynamique d'un job à l'autre ?
Merci pour l'astuce sur le
CI_COMMIT_SHA. Ça m'a permis de taguer mes images Docker proprement.Utilise toujours le chemin absolu avec
$CI_PROJECT_DIR. C'est la seule façon de garantir que ton script ne se plante pas selon le répertoire de travail du runner.J'ai besoin d'accéder à
CI_PROJECT_DIRpour copier des fichiers de config, mais mon chemin est relatif. C'est risqué ?Utilise l'option Masked dans l'interface GitLab. Si tu veux vérifier que c'est bien masqué, fais juste un
echo $MA_VARIABLEdans le script, GitLab le remplacera par [MASKED].Comment je peux débugger les variables sans les afficher en clair dans les logs ? J'ai peur de leak mes API keys.
Regarde les permissions de ton registry. Ton projet a peut-être un accès limité. Vérifie aussi que ton runner est bien tagué sur le projet.
Oui, je fais bien
docker login -u $CI_REGISTRY_USER -p $CI_JOB_TOKEN $CI_REGISTRY. Toujours 403.Vous utilisez bien
$CI_REGISTRY_USERet$CI_REGISTRY_PASSWORDpour le login ? Ne jamais mettre de credentials en dur.Même problème ici. J'ai l'impression que le token n'est pas reconnu.
J'essaie d'utiliser
CI_REGISTRY_IMAGEpour builder mon image Docker mais mon runner refuse le login. C'est normal ?Ajoute ça dans ton
.gitlab-ci.ymlpour forcer l'inclusion des variables :Effectivement, je suis en merge request. Je dois faire quoi pour corriger ça ?
Vérifie ton runner. Si tu es en
detached merge request pipeline, certaines variables ne sont pas injectées par défaut. T'as quoi dans tes logs ?Super article. Par contre j'ai un souci avec
CI_COMMIT_REF_NAME, il me renvoie rien du tout dans mon script shell. Une idée ?