L'IA Explicable au Cœur du DevOps : Construire la Confiance et la Transparence
L'intelligence artificielle n'est plus une curiosité futuriste dans nos stacks techniques, elle est devenue un composant actif, quasi invisible, qui optimise nos déploiements, anticipe les pannes et sécurise nos applications. Pourtant, une question fondamentale émerge de cette automatisation opaque : comment faire confiance à une décision que nous ne pouvons pas comprendre ?
Cette interrogation n'est pas philosophique, elle est au cœur des enjeux de résilience et de conformité de nos systèmes. Quand un algorithme décide de bloquer un déploiement ou de redimensionner un cluster de production, nous, les ingénieurs DevOps, devons être capables d'en auditer la logique. C'est ici qu'intervient une discipline cruciale : l'IA explicable.
Démystifier l'IA "Boîte Noire" : Qu'est-ce que l'XAI ?
Imagine une IA traditionnelle comme une boîte noire. Tu lui donnes des données en entrée, par exemple les logs de performance d'une application, et elle te sort une prédiction en sortie, comme "Risque de panne critique dans 30 minutes". Elle a souvent raison, mais elle est incapable de te dire sur quels signaux faibles ou quelles corrélations elle s'est basée pour arriver à cette conclusion.
L'IA explicable (XAI), ou Explainable AI, est une approche qui vise à briser cette opacité. Son objectif n'est pas seulement de fournir un résultat, mais aussi de générer une explication compréhensible par un humain. Elle transforme le dialogue de "le système va tomber" à "le système va tomber car la latence de la base de données a augmenté de 200% et le taux d'erreur 503 suit la même courbe, un schéma identifié lors de l'incident du mois dernier".
Du "Quoi" au "Pourquoi" : Une Révolution Conceptuelle
Cette transition de la prédiction à l'explication est fondamentale pour notre métier. Elle nous redonne le contrôle et la capacité de valider, de corriger et d'améliorer les systèmes autonomes que nous mettons en place. La confiance ne repose plus sur la foi en l'algorithme, mais sur une compréhension partagée des mécanismes de décision.
La différence est tangible sur des critères opérationnels clés qui impactent directement notre quotidien et nos responsabilités.
| Critère | IA "Boîte Noire" (Traditionnelle) | IA Explicable (XAI) |
|---|---|---|
| Transparence | Faible. La logique interne est une abstraction mathématique complexe. | Élevée. Fournit des justifications claires et des facteurs d'influence. |
| Audit & Conformité | Difficile. Impossible de retracer la cause d'une décision spécifique. | Simplifié. Chaque décision est accompagnée de son propre rapport d'audit. |
| Débogage | Complexe. On ne peut que modifier les données d'entrée pour influencer le résultat. | Ciblé. L'explication pointe directement vers les données qui ont causé le problème. |
| Confiance de l'équipe | Limitée. Les décisions sont acceptées avec scepticisme. | Renforcée. Les ingénieurs peuvent valider et s'approprier les actions de l'IA. |
Applications Concrètes de l'XAI dans vos Pipelines
La théorie est une chose, mais la véritable valeur de l'XAI se révèle lorsqu'elle s'ancre dans nos outils et processus du quotidien. Loin d'être un concept abstrait, elle apporte des solutions pragmatiques à des problèmes que nous rencontrons tous les jours dans la gestion de nos infrastructures et de nos applications.
Optimisation Intelligente des Ressources Kubernetes
L'autoscaling sur Kubernetes est puissant, mais souvent réactif et basé sur des métriques simples comme l'usage CPU. Une IA peut prendre des décisions plus fines en analysant des centaines de métriques. Mais que se passe-t-il si elle décide de provisionner dix nouveaux nœuds à 3h du matin ? Sans XAI, c'est un mystère coûteux.
Avec l'XAI, le système d'AIOps ne se contente pas d'agir, il communique sa logique. L'alerte Slack ne dit plus "Scaling up cluster" mais "Scaling up cluster: Prédiction d'un pic de trafic basé sur le comportement des utilisateurs des 3 dernières campagnes marketing. Facteurs principaux : +40% de requêtes sur le service 'panier' et latence API en hausse de 15%".
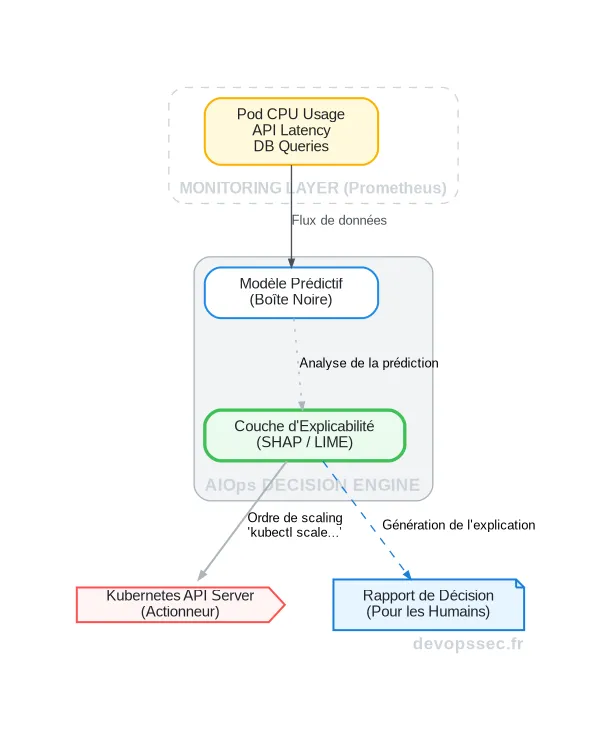
Ce schéma illustre parfaitement le processus. Les métriques brutes de Prometheus nourrissent un modèle prédictif qui suggère une action. Mais avant d'exécuter l'action via l'API Kubernetes, la couche XAI intercepte cette décision, l'analyse pour en extraire les facteurs déterminants, et communique cette justification à l'équipe via une alerte enrichie.
Sécuriser les Pipelines CI/CD avec une Transparence Inédite
L'intégration d'outils de sécurité (SAST, DAST) dans nos pipelines CI/CD est devenue une pratique standard. Désormais, des IA analysent les "patterns" de code pour détecter des vulnérabilités complexes que les outils traditionnels ignorent. Le problème est que ces IA peuvent générer des faux positifs et bloquer des livraisons légitimes sans explication claire.
L'XAI change la donne. Au lieu d'un simple "build failed: high-risk vulnerability detected", le développeur reçoit un rapport détaillé expliquant que son code ressemble à 92% au pattern d'une injection SQL de type "time-based blind", en pointant les variables spécifiques et les flux de données suspects qui ont motivé cette classification. La correction devient intuitive et la confiance dans l'outil est préservée.
Les bénéfices directs pour la chaîne de livraison sont multiples et immédiats.
- Réduction drastique du temps de correction des vulnérabilités.
- Formation continue des développeurs, qui comprennent la nature de la faille.
- Auditabilité totale des décisions de sécurité pour la conformité (SOC 2, ISO 27001).
- Diminution de la friction entre les équipes de sécurité et de développement.
Les Angles Morts de l'Explicabilité : Limites et Coûts Cachés
Malgré ses promesses, l'intégration de l'XAI n'est pas une solution magique et comporte son propre lot de défis. L'ignorer serait une erreur de jugement. La transparence algorithmique a un coût, à la fois technique et conceptuel, qu'il faut anticiper.
Premièrement, générer une explication consomme des ressources de calcul supplémentaires. Une analyse XAI peut ralentir un pipeline ou ajouter une latence à une décision d'autoscaling. Il faut donc trouver le bon équilibre entre la vitesse d'exécution et le besoin de clarté. Tout n'a pas besoin d'être expliqué en temps réel.
Deuxièmement, une explication n'est pas une preuve. Les techniques XAI comme LIME ou SHAP fournissent des approximations locales de la décision du modèle. Elles montrent les facteurs les plus influents pour une décision donnée, mais ne révèlent pas la logique globale et complexe du modèle. Une sur-interprétation de ces explications peut conduire à un faux sentiment de sécurité.
Attention à la complexité de l'outil
Mettre en place et maintenir une stack AIOps basée sur l'XAI demande des compétences pointues. Il ne s'agit pas juste de déployer un outil, mais de comprendre les modèles sous-jacents, de savoir interpréter les résultats et de configurer finement les seuils d'explicabilité pour éviter le bruit.
Vers une Automatisation Responsable
En définitive, l'IA explicable n'est pas une simple évolution technique, c'est un changement de paradigme culturel pour le DevOps. Elle nous force à passer d'une automatisation subie, où nous sommes de simples observateurs de systèmes autonomes, à une automatisation maîtrisée et collaborative, où l'IA devient un véritable partenaire dont nous pouvons questionner et valider les raisonnements.
L'enjeu final est la construction de systèmes non seulement performants et résilients, mais aussi fiables, auditables et dignes de confiance. Pour vous, jeunes ingénieurs qui construisez les infrastructures de demain, adopter les principes de l'XAI, c'est vous donner les moyens de garder le contrôle et de rester les véritables pilotes de systèmes de plus en plus complexes et intelligents.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
16 commentaires
Un script
bashne pourra jamais anticiper les comportements complexes que gère l'IA moderne. On ne joue pas dans la même cour.L'enjeu, c'est de garder la main sur des systèmes qui deviennent trop grands pour être gérés manuellement.
Je reste sceptique. La complexité introduite par ces outils dépasse largement le gain espéré. Je préfère un bon vieux
bashscript qui fait le job de manière prévisible.C'est pour ça que l'XAI doit pointer vers les données brutes. Tu peux toujours vérifier les logs
nginxou les tracesjaegerpour corréler.Et si ton explication est fausse à cause d'un biais dans tes données d'entraînement ? Tu fais confiance aveuglément à une IA qui t'explique pourquoi elle a tort ?
Le monitoring classique te dit 'quoi' (CPU à 90%), l'XAI te dit 'pourquoi' (pic de requêtes sur tel endpoint causé par telle release).
C'est cette différence qui fait gagner un temps fou en incident management.
Totalement d'accord. On finit avec une usine à gaz où personne ne comprend pourquoi le cluster scale. La transparence, c'est du monitoring bien configuré, pas de l'IA.
C'est bien beau dans la doc, mais en vrai, qui va maintenir les modèles ? Les DevOps sont déjà sous l'eau. Tu demandes une double compétence ingé système + data scientist.
Le monitoring du modèle fait partie de l'XAI. Si les facteurs d'influence deviennent incohérents, on déclenche une alerte de 'drift' avant même que les ressources ne soient impactées.
La maintenance de cette stack AIOps, c'est un enfer au quotidien. Tu as prévu quoi pour le monitoring de ton modèle ? Si le modèle dérive, toute ton infrastructure suit le mouvement.
Personne ne dit de laisser l'IA piloter sans surveillance. L'XAI est un outil d'aide à la décision pour l'humain.
Voici comment je structure mes messages d'alerte pour garder le contrôle :
Exactement. Le problème de l'XAI, c'est que c'est souvent corrélé à de la statistique, pas à de la preuve formelle. À ne jamais faire en prod sans un garde-fou humain strict.
L'argument sur la conformité SOC 2 est mignon, mais les auditeurs s'en foutent de tes justifications générées par IA. Ils veulent des preuves basées sur des logs immuables, pas des approximations locales.
C'est un arbitrage nécessaire. Si tu préfères un build rapide qui finit par casser la prod à cause d'une faille, libre à toi.
On peut très bien configurer le pipeline pour ne déclencher l'analyse XAI que sur des branches spécifiques ou certains types de changements critiques dans le
deployment.yaml.Sauf que ton explication, elle consomme des cycles CPU. Si ton pipeline CI/CD est déjà lent, injecter du LIME ou du SHAP pour justifier un rejet de PR, c'est tuer la productivité des devs.
Justement, l'XAI n'est pas là pour ajouter du bruit, mais pour éviter de passer 2 heures à chercher pourquoi un
horizontalpodautoscalera scale-up sans raison apparente.Le but, c'est d'avoir un log intelligible plutôt qu'une boîte noire qui te laisse deviner.
Encore un article qui vend du rêve. Tu parles de XAI pour Kubernetes, mais tu as déjà essayé de débugger une décision prise par un modèle en prod à 3h du matin ? C'est juste ajouter une couche de complexité inutile sur un cluster qui galère déjà.