Le Chaos Engineering a-t-il vraiment pour but de tout casser ?
Vous avez passé des semaines, voire des mois, à polir votre infrastructure, à optimiser vos pipelines CI/CD et à mettre en place une surveillance méticuleuse. Pourtant, un matin, une latence imprévue sur une API tierce met à mal tout votre système. C'est dans ce contexte que la simple prévention ne suffit plus et qu'une approche plus radicale, presque contre-intuitive, prend tout son sens.
Imaginez un instant que vous puissiez déclencher volontairement des pannes contrôlées, non pas pour saboter votre production, mais pour la rendre plus forte. C'est exactement la promesse du Chaos Engineering, une discipline qui ne se contente plus de réagir aux incidents, mais qui les anticipe en les provoquant pour bâtir une confiance absolue dans la robustesse de vos applications.
Loin d'être une simple mode, cette pratique est devenue le pilier des systèmes distribués modernes, car elle transforme notre rapport à l'échec. L'échec n'est plus un accident à éviter à tout prix, mais une donnée d'entrée, une opportunité d'apprentissage pour construire des architectures véritablement auto-réparatrices.
Comprendre l'essence du Chaos Engineering
Pour bien saisir cette philosophie, il faut abandonner l'idée que le Chaos Engineering est une forme de test destructif aléatoire. Au contraire, il s'agit d'une expérimentation scientifique rigoureuse menée sur un système distribué afin de renforcer la confiance en sa capacité à supporter des conditions turbulentes en production.
L'objectif n'est pas de trouver des bugs, ce qui est le rôle des tests traditionnels, mais de découvrir les faiblesses systémiques cachées dans l'interaction complexe entre vos microservices, vos bases de données et votre infrastructure réseau.
La philosophie : Accepter l'inévitable
Le postulat de départ est simple : dans un système complexe, les pannes sont inévitables. Un disque dur va lâcher, un réseau va devenir instable, une API externe ne répondra plus. Plutôt que de vivre dans la crainte de ces événements, le Chaos Engineering nous invite à les simuler de manière proactive dans un environnement contrôlé.
Cette approche permet de révéler des points de défaillance que personne n'aurait pu anticiper sur un schéma d'architecture. Elle force les équipes à concevoir des mécanismes de résilience, comme les circuit breakers, les reintentions (retries) avec backoff exponentiel ou les stratégies de fallback, qui permettent au système de se dégrader gracieusement plutôt que de s'effondrer brutalement.
Chaos Engineering vs Tests traditionnels
Il est crucial de ne pas confondre ces deux approches, car elles répondent à des questions fondamentalement différentes. Les tests traditionnels valident un comportement attendu dans des conditions connues, tandis que le Chaos Engineering explore l'inconnu pour révéler des comportements émergents inattendus.
| Critère | Tests Traditionnels (Intégration, E2E) | Chaos Engineering |
|---|---|---|
| Objectif | Vérifier que le code fait ce qu'il est censé faire (comportement connu). | Découvrir les faiblesses du système face à des conditions imprévues. |
| Environnement | Staging, pré-production, environnements isolés. | Idéalement en production, sur un périmètre contrôlé (blast radius). |
| Hypothèse | Le système doit passer le test dans des conditions nominales. | Le système restera stable malgré l'injection d'une panne spécifique. |
| Résultat | Un binaire : le test passe ou échoue. | Un apprentissage sur la robustesse et les points de défaillance du système. |
Mettre en pratique le Chaos Engineering moderne
L'ère où le Chaos Engineering se résumait à un script maison qui arrêtait des machines virtuelles au hasard est révolue. Aujourd'hui, des plateformes sophistiquées permettent de mener des expériences ciblées, automatisées et intégrées directement dans les pipelines de déploiement continu.
Le principe du moindre impact
Commencez toujours petit. Votre première expérience ne devrait pas consister à couper une base de données en production. Ciblez plutôt un service non critique, sur un faible pourcentage du trafic, et observez attentivement les métriques. L'objectif est de gagner en confiance, pas de créer un incident majeur.
Les étapes d'une expérience de chaos
Une expérience de chaos bien menée suit toujours un protocole scientifique qui garantit la sécurité et la pertinence des résultats. Il ne s'agit jamais d'agir à l'aveugle. Chaque étape est cruciale pour transformer une simple panne en une leçon précieuse pour toute l'équipe.
- Définir l'état stable : Avant toute chose, il faut savoir à quoi ressemble un système en bonne santé. Cela passe par la définition de métriques clés (Key Performance Indicators), comme le taux d'erreur, la latence ou le débit de requêtes.
- Formuler une hypothèse : On émet une supposition mesurable. Par exemple : "Si nous introduisons 100ms de latence sur l'API de paiement, le taux de conversion des paniers ne devrait pas chuter de plus de 5% grâce à notre mécanisme de cache."
- Injecter la défaillance : C'est le cœur de l'expérience. On utilise un outil pour simuler la panne (latence réseau, consommation CPU, arrêt d'un pod Kubernetes). L'impact, ou "blast radius", doit être strictement contrôlé.
- Vérifier l'hypothèse : On observe les métriques définies à la première étape. L'état du système a-t-il dévié de son état stable comme prévu ? L'hypothèse est-elle validée ou réfutée ?
- Apprendre et améliorer : C'est la phase la plus importante. Si l'hypothèse est réfutée, on a découvert une vulnérabilité. L'équipe doit alors travailler sur un correctif, puis ré-exécuter l'expérience pour valider l'amélioration.
Exemple concret avec LitmusChaos sur Kubernetes
Imaginons que nous voulions tester la résilience de notre application front-end si le pod du service de "recommandations" venait à disparaître. Avec un outil comme LitmusChaos, qui s'intègre nativement à Kubernetes, on peut définir cette expérience de manière déclarative en YAML.
Le fichier pod-delete.yaml pourrait ressembler à ceci. Il cible une application via son label app=recommendation-svc et spécifie que l'expérience doit durer 30 secondes, avec un intervalle de 10 secondes entre les actions.
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: frontend-resilience
namespace: default
spec:
appinfo:
appns: 'default'
applabel: 'app=frontend'
appkind: 'deployment'
chaosServiceAccount: litmus-admin
experiments:
- name: pod-delete
spec:
components:
env:
- name: TOTAL_CHAOS_DURATION
value: '30' # en secondes
- name: CHAOS_INTERVAL
value: '10' # en secondes
- name: APP_NAMESPACE
value: 'production'
- name: APP_LABEL
value: 'app=recommendation-svc'Après l'application de ce manifeste avec kubectl apply -f pod-delete.yaml, l'opérateur Litmus se chargera de tuer aléatoirement un pod correspondant au label ciblé, nous permettant d'observer si notre front-end gère correctement l'absence de ce service.
Architecture résiliente : penser le chaos en amont
Le Chaos Engineering est bien plus efficace lorsque les systèmes sont conçus dès le départ pour être résilients. Tenter de renforcer une architecture monolithique fragile a posteriori est une tâche herculéenne. Une architecture moderne, pensée pour le cloud et les systèmes distribués, intègre nativement les mécanismes de défense contre les pannes.
Cela implique de penser en termes de "cellules" autonomes, de couplage faible et de communication asynchrone. L'idée est que la défaillance d'un composant ne doit jamais entraîner un effondrement en cascade, un peu comme les cloisons étanches d'un navire qui empêchent une seule brèche de le couler entièrement.
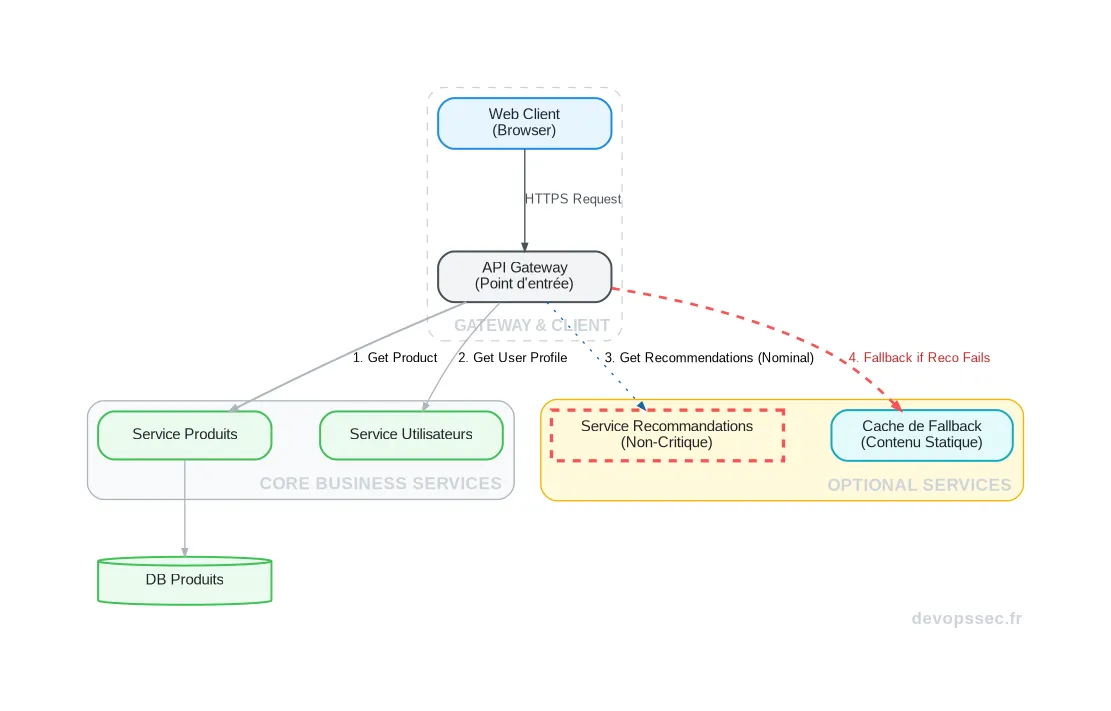
Ce schéma illustre parfaitement un pattern de résilience. L'API Gateway tente d'abord d'appeler le service de recommandations. Si ce dernier échoue (comme simulé par une expérience de chaos), au lieu de retourner une erreur 500, elle se rabat sur un cache de fallback pour afficher un contenu statique. L'expérience utilisateur est légèrement dégradée, mais le service principal reste entièrement fonctionnel.
Le rôle indispensable de l'Observabilité
Lancer des expériences de chaos sans une pile d'Observabilité mature, c'est comme naviguer en pleine tempête sans boussole ni carte. Pour comprendre l'impact de vos pannes simulées, vous avez besoin des trois piliers de l'observabilité qui travaillent de concert.
- Les Métriques (Metrics) : Ce sont vos indicateurs de haut niveau (CPU, RAM, latence, taux d'erreur). Ils vous disent "quelque chose ne va pas".
- Les Traces (Tracing) : Elles suivent le parcours d'une requête à travers tous vos microservices. Elles vous disent "voici où se situe le problème".
- Les Logs : Ce sont les enregistrements détaillés des événements. Ils vous disent "voici exactement pourquoi le problème est survenu".
Sans cette visibilité complète, vous ne pourrez jamais corréler la panne injectée avec son impact réel sur le système, rendant toute l'expérience inutile et potentiellement dangereuse.
Conclusion : Bâtir la confiance, pas le chaos
En définitive, le Chaos Engineering, malgré son nom intimidant, est une discipline profondément constructive. Son but ultime n'est pas de semer la pagaille, mais de construire une confiance inébranlable dans la capacité de vos systèmes à résister aux turbulences inévitables du monde réel.
En adoptant cette pratique, vous ne faites pas que corriger des faiblesses techniques. Vous instillez une culture de la résilience au sein de vos équipes, où chaque ingénieur apprend à anticiper les pannes et à concevoir des logiciels qui non seulement survivent, mais prospèrent face à l'imprévu. C'est un changement de paradigme fondamental qui transforme la fragilité en robustesse, une ligne de code à la fois.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Si ça marche pour toi, continue. Mais n'attends pas une coupure réseau réelle pour voir si tes services redémarrent correctement dans le bon ordre avec tes
depends_on.Bref, c'est encore un truc pour gros clusters. Pour mon docker-compose, je vais continuer à faire mes tests de résilience manuellement avec
docker stop.Tu utilises le Traffic Shadowing ou des en-têtes HTTP spécifiques pour que seule une fraction de tes requêtes soit acheminée vers les instances "chaosées".
La notion de "blast radius" est trop vague. Comment tu définis ça concrètement sans impacter les utilisateurs réels ?
Bien vu. Voici un exemple minimaliste de
Rolenécessaire pour autoriser la suppression de pods :Le YAML présenté est incomplet. Il manque la gestion des permissions RBAC pour que le
chaosServiceAccountpuisse réellement agir sur les pods.C'est souvent le problème. Le Chaos Engineering est la seule discipline où tu dois prouver la valeur d'une absence de panne. C'est contre-intuitif pour le management.
J'ai essayé de convaincre mon CTO. Sa réponse : "Si ça marche, on ne touche pas". Le Chaos Engineering est une vente difficile quand on n'a pas eu de grosse panne récente.
Vous parlez de "cellules autonomes" comme chez Netflix. C'est bien joli, mais on n'a pas tous leur budget R&D. Pour une PME, c'est du luxe.
C'est vrai, mais c'est le prix à payer pour la haute disponibilité. Il faut monitorer le taux d'utilisation des fallbacks comme n'importe quelle autre métrique métier.
Exactement. La complexité du fallback est souvent sous-estimée. C'est l'enfer à maintenir sur le long terme.
Le problème c'est que le fallback devient souvent une autre source de bugs. On finit avec un système qui fonctionne en mode dégradé permanent sans que personne ne s'en rende compte.
Si ça échoue, tu isoles le composant et tu implémentes un mécanisme de fallback. Exemple typique pour une API :
On peut voir un exemple concret de ce qu'on fait quand le test échoue et que le système ne reprend pas son état stable automatiquement ?
Les
StatefulSetdemandent une attention particulière. Tu aurais dû limiter le périmètre de l'expérience avec des labels plus stricts. C'est là que la rigueur scientifique intervient.J'ai testé Litmus en staging, ça a foutu le bazar dans les dépendances
StatefulSet. Résultat : 2 heures de debug pour rien. Je reste sceptique sur l'automatisation de ce genre de tests.C'est un investissement, pas un coût. La résilience n'est pas une fonctionnalité qu'on ajoute, c'est une culture. Si ton équipe ne comprend pas comment le système réagit, tu ne corrigeras jamais les vrais problèmes de fond.
L'article parle de résilience, mais on oublie souvent que le Chaos Engineering coûte une blinde en temps ingénieur. On pourrait utiliser ce temps pour corriger les bugs connus au lieu de chercher des pannes hypothétiques.
L'observabilité, c'est bien, mais si ton backend de logs est saturé par l'expérience, tu perds toute visibilité sur l'impact réel. C'est le serpent qui se mord la queue.
Parce qu'un script bash ne te donne pas l'observabilité intégrée ni le contrôle du blast radius. Avec Litmus, tu peux définir des conditions d'arrêt automatique si les métriques dépassent un seuil.
Le YAML de
ChaosEngineest verbeux à mourir. On a déjà assez de manifestes à maintenir aveckustomize. Pourquoi ne pas juste utiliser un script bash simple pour tuer un process ?Justement, si ton pool SQL sature à cause d'un pod en moins, tu viens de découvrir une vulnérabilité critique. Mieux vaut le savoir via une simulation qu'à 3h du matin lors d'une vraie panne.
"Si ton système est fragile..." c'est facile à dire quand on n'a pas 10 ans de dette technique sur le dos. Dans mon infra, un
pod-deleteinopiné peut saturer le pool de connexions SQL et tout faire tomber. Vos théories sont mignonnes.Le but n'est pas de créer des pannes pour le plaisir, mais de prouver que vos circuit breakers fonctionnent réellement. Si tu as peur de tester en prod, c'est que ton système est déjà trop fragile pour être en ligne.
D'accord avec 1. On a déjà assez de mal à garder nos clusters stables sans qu'un outil vienne tuer des pods pour le plaisir. Qui gère le support quand l'automatisation casse tout un dimanche ?