Comprendre le drame du OOMKilled et préparer son environnement
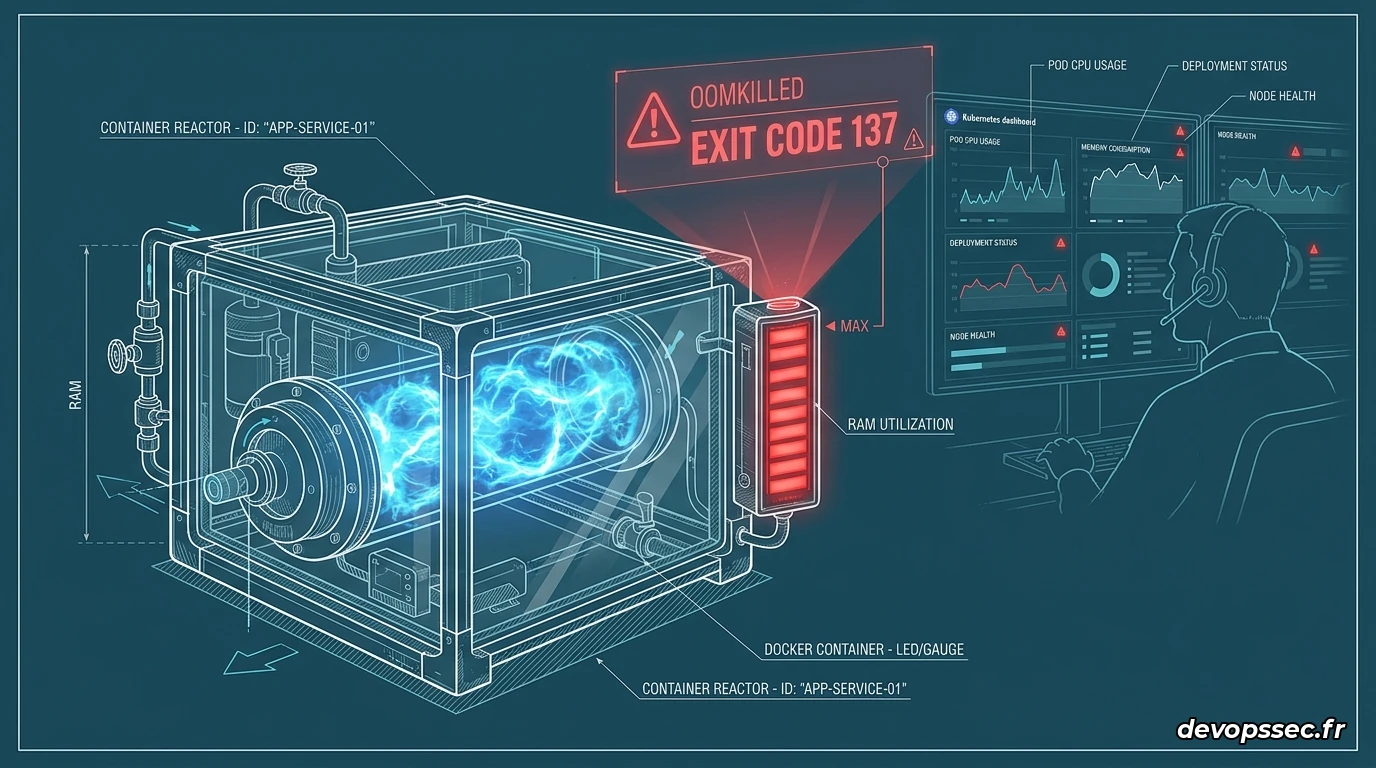
Rien n'est plus frustrant que de voir un conteneur s'arrêter brutalement en pleine production sans laisser de traces évidentes dans ses fichiers de logs applicatifs. Ce phénomène s'appelle l'OOMKilled, une sentence irrévocable prononcée par le système d'exploitation lorsque votre application consomme plus de mémoire vive que la limite autorisée. Pour comprendre ce mécanisme, imaginez un videur de boîte de nuit (le noyau Linux) chargé de maintenir l'ordre : si la piste de danse (la mémoire vive du serveur) est saturée, il va tout simplement expulser le fêtard le plus turbulent (votre conteneur) pour éviter que toute la boîte ne s'effondre.
Pour diagnostiquer et résoudre ce problème récurrent, vous devez disposer des bons outils d'observation directement connectés à votre cluster. Nous allons préparer notre boîte à outils en installant le composant officiel de collecte de métriques et en nous assurant que nous pouvons interroger l'état de nos ressources en temps réel. Ces outils vous permettront de voir la consommation exacte de vos pods avant qu'ils ne franchissent la ligne rouge.
Vérifier et installer les outils de diagnostic requis
Avant d'ajuster vos fichiers de configuration, vous devez vous assurer que votre cluster Kubernetes est capable de mesurer la mémoire consommée. Nous allons déployer le composant standard de collecte de métriques système si celui-ci n'est pas encore actif sur votre infrastructure.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlCette commande déploie le composant metrics-server dans votre cluster, qui agit comme un thermomètre permanent pour mesurer l'utilisation du processeur et de la mémoire vive. Une fois installé, vous pouvez interroger l'état de consommation de vos nœuds et de vos pods individuels avec l'outil en ligne de commande.
kubectl top pods -n defaultRésultat:
NAME CPU(cores) MEMORY(bytes)
api-gateway-7f55b-8p2xl 15m 184Mi
worker-queue-5d99c-z4r8k 120m 1024MiLe retour de cette commande vous indique l'utilisation instantanée de la mémoire vive en mébiboctets (indiqué par Mi). Si un pod approche dangereusement de la limite physique qui lui a été attribuée, le système s'apprête à l'arrêter brutalement.
Détecter le signal de détresse et appliquer une configuration initiale
Le cycle de vie d'une agonie : analyser le crash

Lorsqu'un conteneur dépasse la mémoire allouée, Kubernetes ne prévient pas : il envoie un signal d'arrêt immédiat et sans appel. C'est le fameux code de retour système qui vous indiquera avec certitude que votre application a été coupée pour cause de surconsommation de mémoire.
kubectl describe pod api-gateway-7f55b-8p2xlRésultat:
Containers:
api-gateway:
Container ID: containerd://417a80b...
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Mon, 25 May 2026 08:00:00 +0200
Finished: Mon, 25 May 2026 10:15:30 +0200Le paramètre Reason: OOMKilled associé à l'indicateur Exit Code: 137 confirme de manière absolue que le noyau Linux a détruit le processus. Le code 137 signifie que le processus a reçu le signal de terminaison forcée numéro 9 (SIGKILL) parce qu'il a tenté de s'approprier des ressources physiques qui ne lui appartenaient pas.
Le premier rempart : un manifeste Kubernetes simple
Pour éviter que votre application ne consomme la totalité de la mémoire du serveur physique et ne mette en péril les autres applications, nous devons lui imposer un cadre strict. Nous allons créer un fichier de configuration de base pour définir des frontières claires.
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-gateway
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: api-gateway
template:
metadata:
labels:
app: api-gateway
spec:
containers:
- name: api-gateway
image: nginx:alpine
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "500m"Dans ce manifeste, la section requests détermine la quantité de mémoire garantie pour le conteneur lors de son démarrage sur un serveur physique. Le paramètre limits quant à lui, représente le plafond absolu : si le conteneur tente de dépasser les 256 mébiboctets de mémoire vive, le mécanisme de protection s'active instantanément pour l'arrêter.
La distinction fondamentale entre CPU et RAM
Contrairement au processeur (CPU) qui peut être bridé et ralenti lorsque la limite est atteinte, la mémoire vive (RAM) ne peut pas être compressée. Si votre application manque de mémoire, elle ne peut pas simplement ralentir : elle s'arrête immédiatement.
Bâtir une configuration résiliente face aux fuites de mémoire
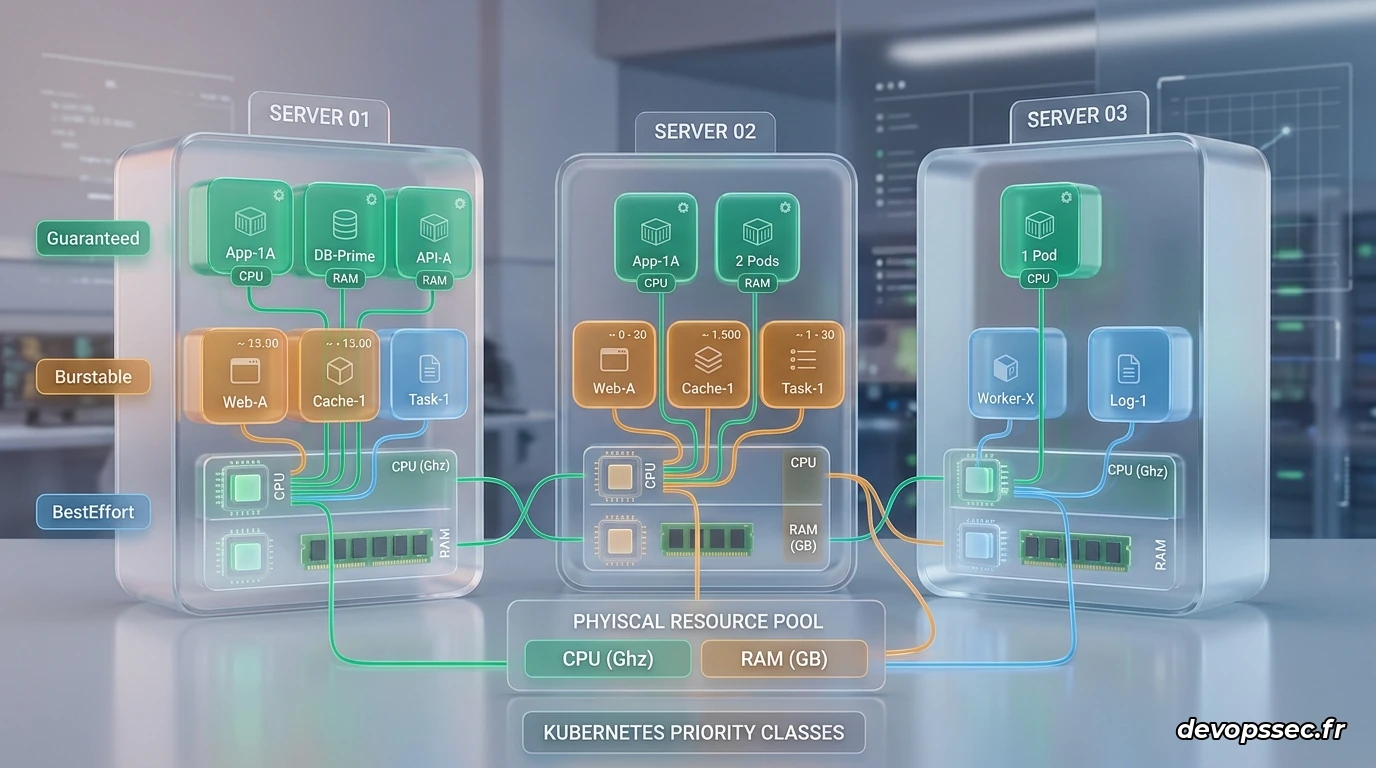
Pour la production, utiliser des valeurs de limites arbitraires est une pratique dangereuse qui mène inévitablement à des pannes en cascade. Nous devons concevoir une architecture où les conteneurs disposent de ressources garanties tout en liant intelligemment les limites de notre application aux limites du système d'exploitation sous-jacent.
Calculer scientifiquement les ratios et comprendre les classes de service
La gestion de la mémoire sous Kubernetes s'appuie sur trois niveaux de priorité appelés Quality of Service (QoS). Lorsque vous définissez des valeurs strictement identiques pour vos demandes et vos limites de ressources, Kubernetes attribue à votre pod la classe de priorité maximale appelée Guaranteed.
Cette classification garantit que votre pod ne sera jamais expulsé du serveur physique pour faire de la place à un autre conteneur, sauf en cas de saturation absolue de la machine hôte. À l'inverse, si vous définissez des limites supérieures aux demandes, votre pod est classé comme Burstable, ce qui le rend vulnérable à une expulsion si le serveur physique commence à manquer d'air.
Le manifeste de production pour un microservice Java/Node.js
Les technologies comme Java ou Node.js possèdent leur propre gestionnaire de mémoire (le Garbage Collector) qui doit être configuré en harmonie avec les limites définies dans votre fichier Kubernetes. Si votre application ignore qu'elle s'exécute dans un conteneur limité, elle tentera de consommer la mémoire globale du serveur physique et subira un arrêt brutal.
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment-processor
namespace: production
labels:
app: payment-processor
tier: backend
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: payment-processor
template:
metadata:
labels:
app: payment-processor
spec:
terminationGracePeriodSeconds: 60
containers:
- name: processor
image: node:20-alpine
command: ["node", "--max-old-space-size=180", "server.js"]
env:
- name: NODE_ENV
value: "production"
resources:
requests:
memory: "256Mi"
cpu: "200m"
limits:
memory: "256Mi"
cpu: "500m"
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 10001
livenessProbe:
httpGet:
path: /healthz
port: 3000
initialDelaySeconds: 15
periodSeconds: 10
timeoutSeconds: 2
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 3000
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
failureThreshold: 2Dans cette configuration de production hautement sécurisée, nous utilisons le drapeau --max-old-space-size=180 pour indiquer à l'environnement d'exécution Node.js qu'il doit déclencher son nettoyage de mémoire interne dès qu'il atteint 180 mébiboctets. Comme notre limite Kubernetes est fixée à 256 mébiboctets, nous conservons une marge de sécurité de 76 mébiboctets pour les besoins internes du système d'exploitation et des processus secondaires du conteneur, évitant ainsi tout risque de dépassement involontaire.
Le paramètre terminationGracePeriodSeconds: 60 laisse le temps nécessaire à notre application de terminer ses transactions en cours avant d'être arrêtée lors d'une mise à jour logicielle ou d'une opération de maintenance sur le cluster.
La règle d'or de la mémoire sous Kubernetes
Ne configurez jamais une limite de mémoire sans configurer de demande équivalente si vous souhaitez garantir la stabilité de vos microservices. Les pods sans demandes précises sont placés dans la catégorie de priorité la plus basse et seront les premiers sacrifiés par le système d'exploitation.

Ce schéma d'architecture détaille le cycle de vie de la gestion de la mémoire depuis la définition initiale de votre fichier de configuration jusqu'aux couches les plus basses du système d'exploitation. Le module de contrôle de Kubernetes traduit vos limites déclaratives en instructions physiques gérées par les cgroups (groupes de contrôle) du noyau Linux. Si la consommation de mémoire réelle franchit la ligne rouge définie par ces cgroups, le système d'exploitation n'a d'autre choix que d'envoyer immédiatement le signal système destructeur pour protéger l'intégrité globale du serveur.
Dompter l'OOMKilled pour un cluster serein
La résolution définitive des pannes de mémoire vive dans vos infrastructures Kubernetes repose sur une discipline de fer et des configurations rigoureuses de vos manifestes de déploiement. En appliquant systématiquement la correspondance exacte entre vos demandes et vos limites de ressources, vous élevez la priorité de vos applications au plus haut niveau de fiabilité offert par la plateforme.
Ne laissez plus jamais vos technologies de conteneurs naviguer à l'aveugle sans connaître l'espace physique qui leur est alloué. Configurez vos moteurs applicatifs pour qu'ils s'adaptent aux barrières physiques de votre infrastructure, mettez en place une surveillance continue avec des alertes ciblées sur l'état de santé de vos applications, et vous transformerez vos environnements de production fragiles en forteresses numériques hautement disponibles.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Avec plaisir. Toujours laisser un peu de marge entre la limite du runtime et la limite du container.
Merci pour le flag
--max-old-space-size=180, c'est exactement le genre de détail qui sauve une prod.C'est systématiquement un
SIGKILL. Dans 99% des cas sur Kubernetes, c'est l'OOMKiller du kernel qui s'en occupe.Le
Exit Code 137c'est toujours la RAM ? Ou ça peut être autre chose ?Si ton app freeze sans mourir, Kubernetes pensera qu'elle est en bonne santé. Elle ne sera jamais redémarrée par le cluster.
C'est quoi le risque réel si je ne mets pas de
livenessProbe?Oui, Go gère mieux la RAM que Node mais il faut quand même définir des
resourcessinon il peut bouffer toute la RAM du host.J'ai testé votre config Node.js, c'est propre. Quelqu'un a essayé avec du Go ?
Content que ça serve. Une fois que t'as aligné
requestsetlimits, tu dors beaucoup mieux la nuit.Merci pour le tuto, le passage sur le
GuaranteedQoS m'a sauvé la mise sur nos workers critiques.Normal. Monte un
emptyDirsur ce chemin pour que ton app puisse écrire ses logs sans toucher au système de fichiers racine.J'ai mis
readOnlyRootFilesystem: trueet maintenant mon app ne démarre plus, elle veut écrire des logs dans/var/log.Utilise Prometheus avec une alerte sur la métrique
kube_pod_container_status_terminated_reasonfiltrée surOOMKilled.Comment je peux monitorer ça proprement sans passer mon temps sur le terminal ?
kubectl topest une moyenne. Le pic de mémoire qui déclenche l'OOM est souvent trop rapide pour être capturé par le polling dumetrics-server.Mon pod passe en OOMKilled alors que
kubectl topaffiche une consommation bien inférieure à la limite. C'est normal ?Ça évite de couper brutalement les requêtes en cours pendant un redéploiement. C'est crucial pour pas corrompre tes données en base.
C'est quoi l'intérêt de la
terminationGracePeriodSecondsdans votre exemple ?Oui, tu dois jouer sur les flags
-XX:MaxRAMPercentagepour que la JVM comprenne les cgroups du conteneur.J'ai une app Java qui crash tout le temps. Vous avez un équivalent au
--max-old-space-sizepour la JVM ?À ne jamais faire en prod. Si tu mets des limites supérieures, tu passes en classe
Burstable. En cas de pression, ton pod sera le premier à dégager.Pourquoi vous dites que
limitsetrequestsdoivent être identiques ? C'est pas plus souple de laisser le pod monter si besoin ?T'as bien déployé le
metrics-server? Sans lui, l'API ne peut pas te renvoyer les stats. Lance le manifest du repo officiel d'abord.J'ai testé
kubectl top podsmais ça me retourne une erreur de connexion. Une idée ?C'est exactement ça. Le 137 confirme que le noyau a killé ton process. Check le
kubectl describe podpour confirmer la raison.