Pourquoi le "Time-to-Market" ne suffit plus ?
Vous avez passé des mois à optimiser votre pipeline CI/CD, à réduire les temps de build de quelques minutes et à automatiser chaque déploiement. Pourtant, malgré ces prouesses techniques, le management vous demande encore pourquoi les fonctionnalités promises il y a six mois ne sont toujours pas entre les mains des utilisateurs. C'est le paradoxe de l'ingénierie moderne : nous sommes devenus experts pour livrer vite, mais nous avons parfois perdu de vue ce que nous livrons réellement.
C'est précisément ici qu'intervient le Value Stream Management (VSM). Oubliez un instant la vitesse d'exécution pure et concentrez-vous sur le flux de la valeur. Le VSM n'est pas un nouvel outil à la mode, mais une discipline qui consiste à cartographier, mesurer et optimiser l'intégralité du parcours d'une idée, depuis sa conception initiale jusqu'à sa livraison effective en production et l'impact qu'elle génère.
Il ne s'agit plus seulement de savoir *comment* on déploie, mais de comprendre *ce qui* ralentit la transformation d'un besoin métier en une solution concrète. Le VSM nous force à regarder au-delà de nos dashboards Jenkins ou GitLab pour embrasser une vue holistique du cycle de vie logiciel.
Décortiquer le Flux de Valeur : Des Concepts à la Réalité
Avant de pouvoir optimiser quoi que ce soit, il faut d'abord rendre le visible invisible. Un "flux de valeur" (ou Value Stream) représente l'ensemble des étapes, des actions et des personnes nécessaires pour amener une fonctionnalité du concept à la production. Cela inclut non seulement les étapes techniques, mais aussi les phases de décision, d'attente et de validation qui, bien souvent, constituent les véritables freins.
Identifier et cartographier votre flux
La première étape, et sans doute la plus révélatrice, est un exercice de cartographie. Il s'agit de réunir les différentes parties prenantes (produit, design, développement, QA, ops) et de dessiner ensemble le parcours réel d'une demande. Vous seriez surpris de découvrir les "zones grises" et les temps d'attente insoupçonnés qui existent entre chaque silo de votre organisation.
Concrètement, le processus de mapping consiste à lister chaque état par lequel passe une initiative. Cela pourrait ressembler à ceci :
- Idéation et priorisation dans le backlog produit.
- Spécification et design UX/UI.
- Développement de la fonctionnalité dans une branche dédiée.
- Revue de code (Pull Request / Merge Request).
- Exécution du pipeline de CI/CD (build, tests unitaires, tests d'intégration).
- Déploiement sur un environnement de staging pour validation.
- Validation par l'équipe Qualité (QA) et le Product Owner.
- Déploiement en production.
- Monitoring et collecte de feedback utilisateur.
Pour chaque étape, l'objectif est de mesurer quatre métriques fondamentales, souvent appelées les métriques DORA, qui sont au cœur de la performance DevOps et que le VSM permet d'analyser finement. Ces métriques fournissent une vision objective de la santé de votre flux de livraison.
Visualiser le cycle de vie complet
Une fois le flux cartographié, il devient possible de le visualiser et de le mesurer. C'est là que le VSM prend toute sa dimension en connectant des outils qui, jusqu'à présent, ne se parlaient pas. Imaginez un tableau de bord qui agrège les données de Jira, GitHub, CircleCI et Prometheus pour vous donner une vue unifiée de la performance, non pas technique, mais orientée valeur.
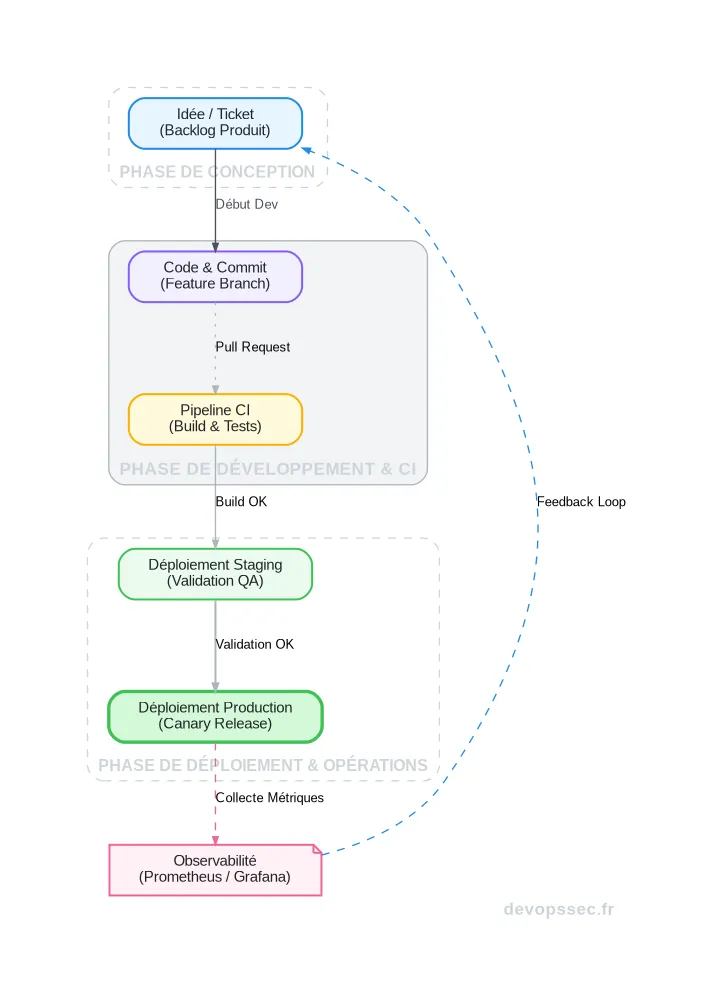
Ce schéma illustre parfaitement le parcours complet. Le VSM ne s'arrête pas à la porte de la production ("Prod Deploy") mais intègre la boucle de feedback ("Feedback Loop") issue de l'observabilité, car la vraie valeur n'est réalisée que lorsque la fonctionnalité est utilisée et qu'elle répond à un besoin.
Le VSM en Pratique : Transformer les Données en Actions
La cartographie et la mesure ne sont que les premières étapes. La véritable puissance du VSM réside dans sa capacité à transformer ces informations en améliorations concrètes et ciblées. Vous ne naviguez plus à vue, mais sur la base de données tangibles qui exposent les vrais problèmes.
Des métriques pour piloter le changement
En analysant votre flux, vous allez rapidement identifier des schémas récurrents. Peut-être que le Cycle Time (temps entre le premier commit et le déploiement) est court, mais que le Lead Time (temps entre la demande initiale et la livraison) est extrêmement long. Cela indique que le goulot d'étranglement n'est pas technique, mais se situe en amont, dans les phases de spécification ou de priorisation.
Le VSM vous aide à vous poser les bonnes questions en fournissant des données pour y répondre. C'est un changement fondamental par rapport à une approche basée sur l'intuition.
| Métrique Clé | Ce qu'elle mesure | Question à laquelle elle répond |
|---|---|---|
| Lead Time for Changes | Temps total écoulé entre la demande d'une fonctionnalité et sa livraison en production. | À quelle vitesse pouvons-nous répondre à un besoin métier ? |
| Deployment Frequency | La fréquence à laquelle vous déployez en production. | Sommes-nous capables de livrer de la valeur de manière continue et régulière ? |
| Cycle Time | Temps écoulé entre le premier commit de code et le déploiement effectif. | Quelle est l'efficacité de notre pipeline de développement et de livraison technique ? |
| Change Failure Rate | Le pourcentage de déploiements qui provoquent un incident en production. | La vitesse de nos livraisons se fait-elle au détriment de la stabilité ? |
Identifier les files d'attente, les vrais ennemis de la vélocité
Une des révélations majeures du VSM est que la majorité du temps n'est pas passée en travail actif (Process Time), mais en temps d'attente (Wait Time). Une Pull Request qui attend trois jours d'être relue, un build qui patiente des heures pour qu'un agent de CI soit disponible, ou une validation qui est bloquée en attente d'un environnement de test sont autant de sources de gaspillage qui paralysent votre flux.
Imaginons un fichier de configuration pour un outil de VSM qui définirait les étapes de votre pipeline. Il permettrait de tracker précisément le temps passé dans chaque état.
# Exemple de configuration d'un flux dans une plateforme VSM
valueStream:
name: "Feature Delivery Pipeline"
stages:
- id: ideation
name: "Phase d'Idéation"
type: event
source: jira
startEvent: "issue.created"
endEvent: "issue.status.in-progress"
- id: development
name: "Phase de Développement"
type: process
source: github
startEvent: "branch.created"
endEvent: "pullrequest.merged"
- id: ci-cd
name: "Intégration et Déploiement"
type: process
source: gitlab-ci
startEvent: "pipeline.started"
endEvent: "deployment.succeeded"
# On peut définir des seuils d'alerte
sla:
maxDuration: "45m"
- id: validation
name: "Phase de Validation"
type: wait
source: manual
startEvent: "deployment.succeeded"
endEvent: "release.approved"Avec une telle configuration, si le temps passé dans l'étape validation est systématiquement élevé, vous avez une preuve irréfutable qu'il faut investir dans l'automatisation des tests d'acceptation ou allouer plus de ressources à la QA.
Les Limites et Coûts Cachés du VSM
Adopter le Value Stream Management n'est cependant pas une solution miracle. C'est une démarche exigeante qui comporte son lot de défis. Le plus grand risque est de le considérer comme un simple projet d'outillage. Acheter une plateforme de VSM sans accompagner le changement culturel est la recette garantie pour un échec.
Le VSM demande une transparence radicale et une collaboration inter-équipes. Si votre organisation fonctionne en silos rigides où chaque département optimise son propre périmètre sans se soucier de l'impact global, la démarche se heurtera à un mur. La résistance au changement est un obstacle majeur, car mesurer le flux expose inévitablement les inefficacités et peut être perçu comme une forme de surveillance.
Le piège de la sur-optimisation
Attention à ne pas tomber dans la "paralyse par l'analyse". Collecter des données est utile, mais l'objectif est d'identifier les 2 ou 3 goulots d'étranglement majeurs et de se concentrer sur leur résolution. Tenter de tout optimiser en même temps dilue les efforts et ne produit aucun résultat significatif.
Enfin, l'intégration technique pour agréger les données de dizaines d'outils hétérogènes représente un coût non négligeable en termes d'ingénierie. Le retour sur investissement est immense, mais il faut être prêt à consacrer du temps et des ressources pour construire cette vue à 360 degrés.
Conclusion : Le VSM, un Changement de Paradigme pour le DevOps
En définitive, le Value Stream Management représente la maturation du mouvement DevOps. Il nous fait passer d'une obsession pour l'automatisation des tâches techniques à une concentration sur l'optimisation des flux de valeur pour l'entreprise. Il aligne enfin les objectifs de la tech avec ceux du business, en fournissant un langage et des métriques communs.
Pour toi, jeune ingénieur DevOps, comprendre et maîtriser les principes du VSM est une compétence qui te rendra incroyablement précieux. Tu ne seras plus seulement celui qui fait tourner les pipelines, mais celui qui aide l'organisation à livrer plus de valeur, plus rapidement et plus sereinement. C'est là que se trouve le véritable impact de notre métier.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
22 commentaires
Commencez petit. Mappez juste votre propre flux de livraison, même s'il est imparfait. L'important est de démarrer la mesure sur le
Cycle Timeréel.Ok, mais ça demande une architecture microservices parfaite. On vit dans le monde réel avec du monolithe et du spaghetti.
C'est le niveau expert. Il faut mapper les flux croisés en utilisant des IDs de corrélation dans vos headers de requêtes ou vos messages
Kafka.T'as une solution pour les dépendances entre équipes ? Mon
microservice-Adépend dumicroservice-Bgéré par une autre équipe. Le VSM gère ça comment ?C'est là que le changement culturel intervient. Il faut montrer que le VSM aide aussi la QA en éliminant les allers-retours inutiles sur des environnements instables.
Et si l'équipe QA refuse de changer ses habitudes ? Ton beau schéma reste un dessin sur un tableau blanc.
En intégrant la validation dans le flux. Par exemple, une validation via
Slackqui déclenche un webhook :Ton approche du
sladans le yaml est intéressante pour les tests d'acceptation. Mais en pratique, la QA c'est souvent humain. Tu fais comment pour automatiser le "release.approved" ?Si vous utilisez le VSM pour du flicage individuel, vous avez déjà perdu. C'est un outil pour optimiser le système, pas pour traquer les gens. Si le management ne comprend pas ça, n'implémentez rien.
Clair. La mesure tue la créativité. Le VSM c'est bien pour les flux industriels, pas pour de la R&D où tu dois parfois tâtonner.
Le vrai danger c'est que le management utilise ces métriques pour fliquer les devs. "Pourquoi tu as passé 4h sur cette PR ?". C'est à ne jamais faire en prod humainement parlant.
Ne faites pas vos propres outils de parsing. Utilisez des solutions basées sur des événements standardisés comme
CloudEvents. Sinon vous finirez par maintenir une usine à gaz insupportable.J'ai essayé d'implémenter ça avec des scripts
bashqui parsant les logs d'API. C'est un enfer. T'as un conseil pour éviter la dette technique sur les outils de monitoring eux-mêmes ?Je n'ai jamais dit que le VSM remplaçait la qualité. Il permet juste de prouver au PO que si la spec change 4 fois en une semaine, c'est ça qui flingue le
Lead Time, pas le pipeline lui-même.On est d'accord. Le VSM c'est souvent un cache-misère pour des processus métier moisis. Le meilleur pipeline du monde ne sauvera pas une spec écrite avec les pieds.
Et si mon
gitlab-ciplante au milieu ? Ton VSM va juste m'afficher "en cours" pendant 3 jours. C'est inutile sans un vrai travail sur la qualité du code en amont.Si vous devez "taguer" manuellement, c'est que l'implémentation est ratée. L'idée c'est de brancher les webhooks directement sur les événements
git. Regardez cette config pour automatiser le suivi :Exactement. On a déjà assez de boulot avec
kubectlpour gérer nos déploiements. Si on ajoute une surcouche de monitoring de flux, on finit par ne plus rien livrer. C'est le paradoxe du contrôle.Le problème c'est que les devs vont passer plus de temps à taguer leurs tickets
Jirapour alimenter vos dashboards qu'à coder. On devient des comptables du code.C'est précisément le point. Si ton outil legacy ne remonte rien, c'est ton premier goulot d'étranglement. Le VSM sert à rendre visible l'invisible, même si ça fait mal de voir que ton pipeline est une boîte noire.
C'est vrai que le VSM c'est joli sur le papier. Mais dès que t'as des outils legacy qui ne remontent rien proprement, ton
valueStreamdans le yaml devient une usine à gaz injouable. Qui va maintenir ces connecteurs ?Encore une énième couche de management sur le pipeline. Vous avez déjà essayé de gérer les conflits de merge dans une équipe de 50 personnes avec vos dashboards
Jira? C'est de la théorie pour consultants ça.