L'enjeu critique des coûts matériels

Faire tourner un modèle de langage coûte extrêmement cher en ressources. Vous payez chaque minute d'utilisation de votre matériel graphique sur le cloud. Par conséquent, maintenir un cluster statique allumé en permanence gaspille votre budget.
Pourtant, la demande de vos utilisateurs varie constamment au fil de la journée. Il est impossible de prévoir manuellement le nombre de serveurs nécessaires. L'objectif est donc d'adapter automatiquement l'infrastructure à la demande réelle.
C'est exactement ce que propose l'Auto-scaling dynamique. Cet outil analyse la charge et ajoute des machines uniquement quand c'est nécessaire. Vous optimisez ainsi vos factures sans sacrifier les performances de vos applications.
La mécanique derrière l'approvisionnement dynamique
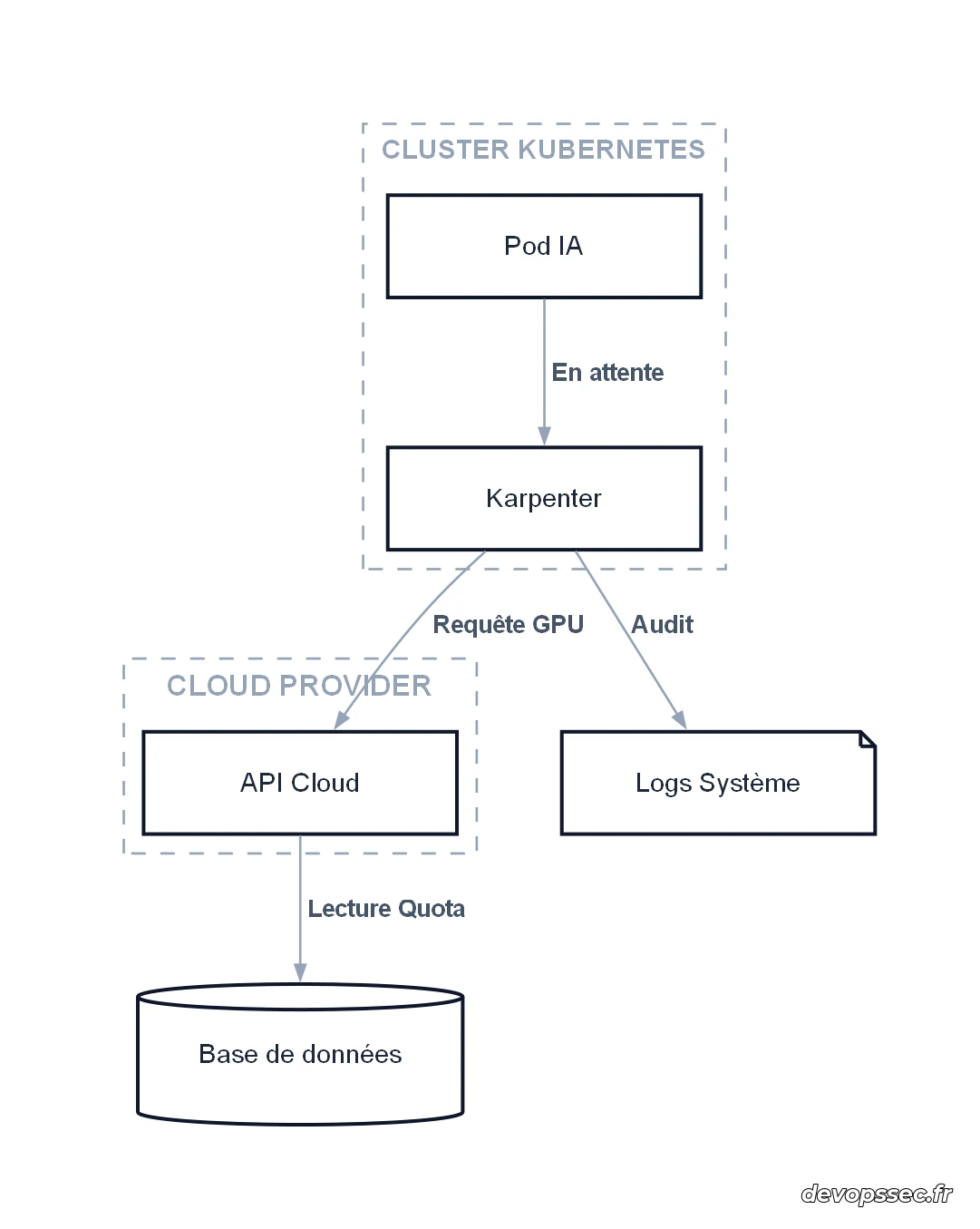
Pour comprendre cette magie, il faut analyser la communication entre vos composants. Le moteur de gestion observe en permanence les tâches en attente de traitement. Dès qu'une ressource manque, il discute directement avec votre fournisseur d'infrastructure.
Vitesse d'exécution optimale
Cet outil contourne les groupes d'auto-scaling classiques pour gagner de précieuses minutes lors du démarrage d'une machine.
L'analyse des ressources en attente
Concrètement, le système surveille les conteneurs qui ne trouvent pas de place. Ces tâches en attente déclenchent immédiatement une évaluation de vos besoins matériels. Le moteur calcule ensuite la combinaison optimale de machines pour répondre à la demande.
Non seulement il trouve la bonne taille de serveur, mais il optimise aussi les coûts. Il privilégie systématiquement les instances les moins chères disponibles sur le marché. Cette approche garantit une Inférence LLM fluide et particulièrement économique.
Comparons cette approche moderne avec une méthode d'évolution traditionnelle sur le cloud.
| Caractéristique | Autoscaler Classique | Outil Dynamique |
|---|---|---|
| Vitesse de démarrage | Lente (Groupes liés) | Très rapide (Appel direct) |
| Choix du matériel | Statique et restreint | Flexible et varié |
| Optimisation financière | Basique | Avancée (Spot instances) |
Cette flexibilité change radicalement la gestion quotidienne de vos environnements de production. Vous ne gérez plus des serveurs individuels, mais de simples règles de comportement. Le système prend les décisions d'infrastructure à votre place en temps réel.
Mise en pratique de l'automatisation

Passons maintenant à la configuration concrète de votre environnement de travail technique. L'élément central de cette architecture s'appelle le NodePool.
Configuration du comportement global
Le fichier de définition détermine les limites et les types de machines autorisés. Vous devez spécifier clairement que vous cherchez du matériel adapté à l'intelligence artificielle. Sans cela, le système risque d'allumer des serveurs classiques totalement inutiles.
Nous allons écrire un fichier descriptif simple, lisible et facile à maintenir. Utilisez la commande kubectl apply -f config.yaml pour l'envoyer à votre cluster. Le composant principal lira ce fichier pour configurer ses règles d'approvisionnement.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: gpu-pool
spec:
template:
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge"]
- key: karpenter.k8s.aws/instance-gpu-manufacturer
operator: In
values: ["nvidia"]Résultat:
[INFO] NodePool gpu-pool created successfully
[INFO] Waiting for pending pods...
[SUCCESS] Provisioned node ip-10-0-1-12.internal
[SUCCESS] NVIDIA GPU instance active and boundVotre configuration est maintenant active et surveille le réseau en silence. Allez vérifier l'état global du système dans le répertoire /var/log/pods si besoin. Le système est totalement prêt à réagir à la première surcharge.
Validation par la charge
Il est temps de tester notre déploiement en conditions réelles d'utilisation. Nous allons simuler l'arrivée soudaine de nombreuses requêtes sur notre application principale. Cette action va saturer les ressources actuelles et forcer la création de conteneurs supplémentaires.
En observant les événements, vous verrez Karpenter entrer immédiatement en action. Il va instantanément détecter le manque critique de puissance graphique. En quelques secondes, une nouvelle machine viendra rejoindre votre flotte opérationnelle.
Cette automatisation apporte plusieurs bénéfices immédiats et majeurs pour votre équipe technique.
- Réduction drastique des interventions humaines nocturnes ou lors d'urgences critiques.
- Baisse significative de votre facture d'hébergement cloud à la fin du mois.
- Maintien d'une expérience utilisateur fluide même lors des pics d'affluence soudains.
- Standardisation propre de vos configurations d'infrastructure guidée par le code.
Pour observer cette création en direct, utilisez une simple ligne de commande. Tapez kubectl get nodes -w directement dans votre console d'administration. Vous verrez le nouveau serveur apparaître sous vos yeux comme par magie.
Une infrastructure qui respire
Vous avez transformé un environnement rigide en un système organique extrêmement intelligent. Votre infrastructure réagit désormais précisément et automatiquement aux besoins de vos applications. Cette approche moderne est absolument vitale pour maîtriser vos investissements technologiques.
Continuez d'explorer les métriques de vos déploiements pour affiner vos réglages quotidiens. Ajustez les limites de vos ressources pour trouver l'équilibre parfait entre performance et économie. Votre maîtrise fine de ces outils fera de vous un ingénieur particulièrement précieux.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
D'ailleurs, si vous avez des pics de charge très brutaux, n'oubliez pas d'ajuster le
readinessProbede vos conteneurs GPU.Si l'inférence prend du temps à charger le modèle en VRAM, le node sera marqué Ready avant que le pod soit vraiment capable de répondre.
Oui, évite absolument de faire tourner le cluster autoscaler classique et Karpenter sur les mêmes labels de nœuds.
Laisse Karpenter gérer tout le cycle de vie des nodes GPU, c'est beaucoup plus propre.
La commande
kubectl apply -f config.yamlfonctionne, mais est-ce qu'il y a un risque de conflit avec un autre provisioner déjà actif sur le cluster ?Ça dépend de ton SLA. Si c'est du batch, on s'en fout. Si c'est du temps réel, tu dois avoir une stratégie de failover vers des instances On-Demand si tes Spot ne sont plus dispo.
Tu peux configurer le
NodePoolpour avoir un mélange des deux.Le choix des instances Spot, c'est bien beau, mais pour l'inférence LLM c'est pas risqué d'avoir des coupures en plein milieu d'une requête ?
Regarde plutôt les logs du pod Karpenter lui-même :
kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter.C'est là que tu verras pourquoi le provisionnement échoue (souvent un problème de quota vCPU sur le compte AWS).
J'ai essayé de configurer ça, mais mes pods restent en
Pending. J'ai checké/var/log/podset y'a rien de clair.Pour le long terme, tu dois tracker les métriques du controller Karpenter avec Prometheus.
Regarde surtout le
karpenter_nodes_termination_reasonspour voir si tu te fais trop éjecter tes instances Spot.Et niveau monitoring, tu regardes quoi en priorité ?
kubectl get nodes -wc'est sympa pour le debug mais pour le long terme ?Tu peux ajouter plusieurs types dans la liste
valuesou même définir des plages de CPU/RAM.J'ai un souci avec les
requirementsdans le yaml. Si je veux mixer des instances, je fais comment ?C'est le jour et la nuit. L'autoscaler classique attend que les nodes soient prêts via l'ASG, ce qui est très lent.
Karpenter bypasse cette couche et appelle directement l'API EC2. On passe de plusieurs minutes à quelques secondes pour qu'un node soit
Ready.C'est quoi la différence réelle au niveau du temps de provisionnement par rapport à un cluster Autoscaler classique ?
Bonne question. Il faut obligatoirement gérer le
termination handlerdans ton cluster.Karpenter le fait nativement en écoutant les signaux AWS. Dès qu'une interruption est annoncée, il déplace les pods vers des nodes sains avant le shutdown.
J'ai testé le
NodePoolavecg4dn.xlarge. Ça marche bien mais comment tu gères les interruptions sur les instances Spot ?Les cold starts sont inévitables avec des images CUDA lourdes, mais en utilisant des images optimisées et en pré-pullant les layers, on gagne un temps fou.
L'idée ici c'est surtout d'éviter le sur-provisionnement inutile. Le gain sur la facture est immédiat.
Enfin un tuto qui évite de passer par les ASG classiques qui mettent trois plombes à scale. Par contre, t'as pas peur des cold starts avec les instances GPU ?