Le Noyau Linux Ouvre ses Portes
Pendant des décennies, toucher à l'ordonnanceur du noyau Linux s'apparentait à de la neurochirurgie à l'aveugle. Les ingénieurs devaient recompiler des noyaux entiers, prier pour ne pas déclencher de "Kernel Panic", et accepter des compromis de performance. Aujourd'hui, cette époque est révolue. L'introduction de sched_ext transforme le cœur monolithique de Linux en un terrain de jeu programmable, sécurisé et dynamique. Nous avons désormais le pouvoir de dicter comment chaque cycle CPU est distribué, sans jamais redémarrer la machine.
Cette flexibilité inouïe redéfinit les architectures à très faible latence. Que vous gériez un cluster de microservices ultra-nerveux, une base de données massivement parallèle ou une plateforme de trading haute fréquence, l'ordonnancement par défaut n'est plus une fatalité. Plongeons sous le capot pour comprendre comment remplacer le chef d'orchestre du système d'exploitation par nos propres règles algorithmiques, compilées à la volée.
Anatomie d'une Révolution : Pourquoi sched_ext ?

L'ordonnanceur par défaut historique, le Completely Fair Scheduler (récemment supplanté par l'EEVDF), excelle dans un domaine précis : le compromis universel. Il doit garantir qu'un serveur web, un jeu vidéo et une tâche d'encodage vidéo puissent cohabiter sur la même machine avec une fluidité acceptable. Cependant, en production critique, le "compromis" est l'ennemi de la performance absolue. Si votre application nécessite qu'un processus accède au cache L3 d'un processeur spécifique en moins de dix microsecondes, la politique d'équité du noyau par défaut devient un goulot d'étranglement majeur.
Le changement de paradigme vers l'espace utilisateur
C'est ici qu'intervient sched_ext. Conçu comme une nouvelle classe d'ordonnancement (baptisée SCHED_EXT), ce framework permet de déléguer la logique de sélection des tâches à des programmes eBPF (Extended Berkeley Packet Filter). Pour vulgariser ce concept, imaginez un restaurant très prisé. Jusqu'à présent, le maître d'hôtel (le noyau) plaçait les clients selon une règle stricte d'ordre d'arrivée. Avec eBPF, vous confiez à ce maître d'hôtel un casque audio sécurisé par lequel vous lui chuchotez vos propres règles de placement VIP en temps réel, sans qu'il ait besoin d'arrêter son service.
Isolation et Sécurité
Le vérificateur eBPF garantit que votre code d'ordonnancement ne peut pas faire crasher le noyau ni créer de boucles infinies. Si votre programme BPF échoue ou dépasse un temps d'exécution critique, sched_ext déclenche un mécanisme de repli de sécurité (fallback) automatique vers l'ordonnanceur par défaut pour éviter de figer le système.
Pour exploiter cette technologie, votre socle technique doit répondre à des critères précis. Il est impératif de disposer d'un noyau récent (généralement supérieur à la branche 6.11) compilé avec l'option CONFIG_SCHED_CLASS_EXT=y. Côté espace utilisateur, vous aurez besoin de la chaîne de compilation LLVM/Clang pour transformer votre code C en bytecode BPF, ainsi que des en-têtes du noyau générés via bpftool vmlinux.
Architecture Sous le Capot : Les Dispatch Queues
La mécanique implacable de cet ordonnanceur BPF repose sur un concept central : les dispatch queues (DSQ). Lorsqu'un processus est réveillé et prêt à être exécuté, il ne va plus directement se battre pour obtenir un CPU. Il traverse un pipeline d'interceptions (hooks) où votre code BPF décide de son sort. La flexibilité est totale : vous pouvez créer des files d'attente globales, des files spécifiques par cœur (per-CPU), ou même des files liées à la topologie NUMA de votre matériel pour maximiser le taux de succès (hit rate) de vos caches processeurs.
Le cycle de vie d'une tâche interceptée
Le workflow s'articule autour de deux fonctions fondamentales que votre programme doit implémenter : ops.enqueue et ops.dispatch. La première est appelée par le noyau lorsqu'une tâche devient exécutable. C'est votre point de tri. La seconde est sollicitée par un cœur CPU lorsqu'il devient inactif et cherche du travail. Vous agissez donc à la fois comme un centre de tri postal et comme un dispatcher de flotte de taxis, assurant une symbiose parfaite entre le besoin logiciel et la disponibilité matérielle.
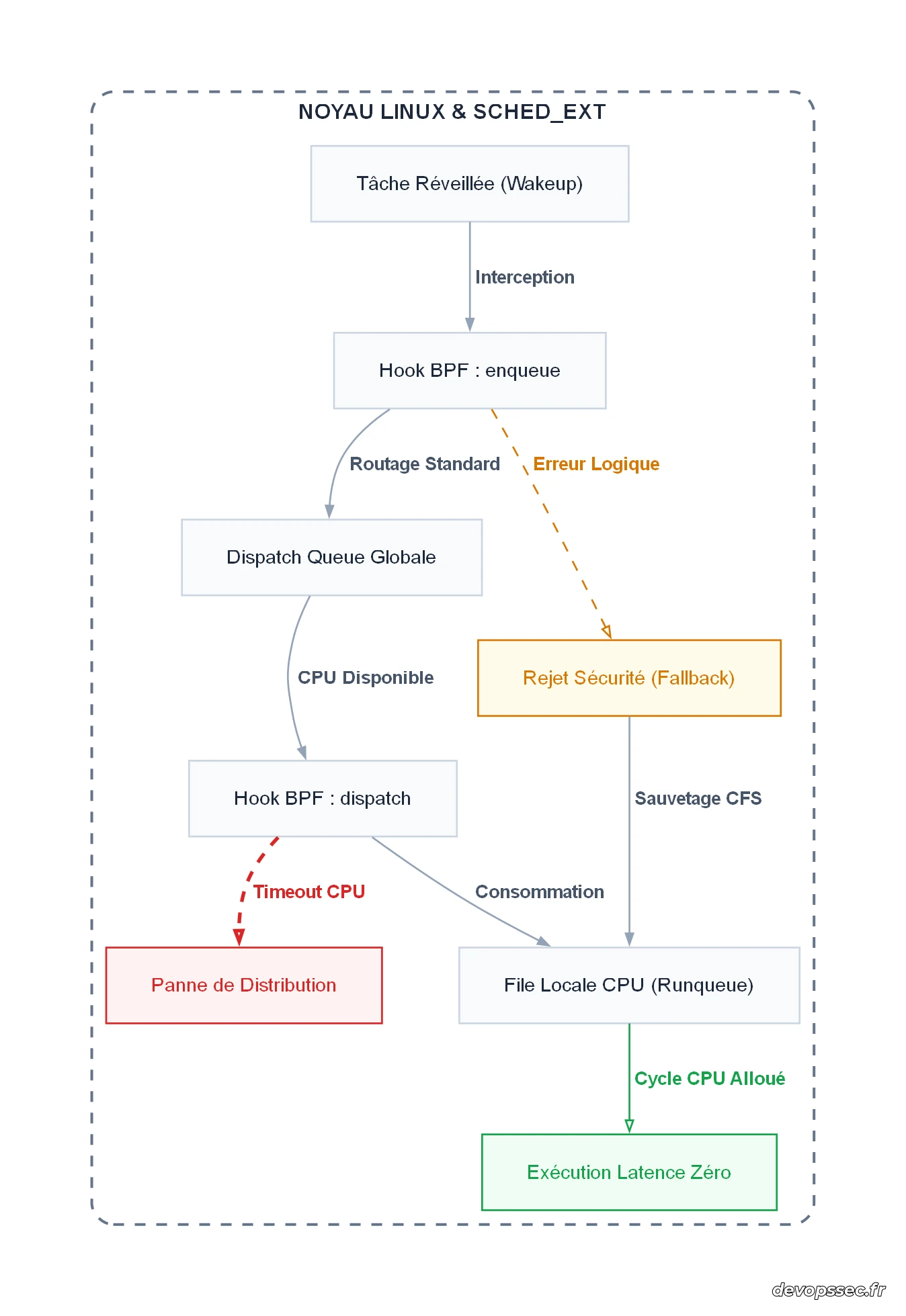
Ce schéma détaille le cheminement critique d'un processus. Le flux nominal transite par les hooks enqueue et dispatch, stockant temporairement les tâches dans une Dispatch Queue Globale. Si votre code eBPF prend une mauvaise décision ou qu'une anomalie est détectée, le mécanisme de sauvegarde redirige la tâche vers le CFS (flèche d'avertissement). Une fois routée correctement vers la file locale du CPU, la tâche accède au processeur de manière optimale, garantissant une exécution à très faible latence (flèche de succès).
Cas Pratique : Un Ordonnanceur Orienté Latence en Production

Passons de la théorie à l'implémentation. Nous allons concevoir le noyau d'un ordonnanceur ciblant spécifiquement la réduction du délai de réveil (wakeup latency). L'objectif est d'identifier les processus critiques par leur priorité, et de contourner la file d'attente globale pour les injecter directement dans la file d'attente locale (L1/L2 cache-hot) du processeur actuel. C'est une stratégie redoutable pour les microservices synchrones.
Le code BPF : Filtrage chirurgical et priorisation
Le code source suivant est écrit en C contraint. Il utilise la macro SEC pour indiquer au chargeur dans quelle section ELF placer les fonctions. Notez l'utilisation de la fonction interne scx_bpf_dispatch, qui est l'outil principal pour router une structure de processus (task_struct) vers une destination spécifique de l'architecture physique.
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
/* Définition du hook d'insertion des tâches */
SEC("struct_ops/my_latency_enqueue")
void BPF_PROG(my_latency_enqueue, struct task_struct *p, u64 enq_flags) {
/* Vérification de la priorité : p->prio < 100 identifie généralement
les tâches temps-réel ou critiques selon la configuration locale. */
if (p->prio < 100) {
/* Contournement total : Injection directe dans la queue locale du CPU
courant pour forcer une exécution immédiate (cache chaud). */
scx_bpf_dispatch(p, SCX_DSQ_LOCAL, SCX_ENQ_WAKEUP);
} else {
/* Tâches standards : Routage vers la file globale partagée (ID 0 par défaut).
Elles seront récupérées plus tard par un CPU inactif. */
scx_bpf_dispatch(p, SCX_DSQ_GLOBAL, enq_flags);
}
}
/* Initialisation et signature de l'ordonnanceur BPF */
SEC(".struct_ops.link")
struct sched_ext_ops my_latency_ops = {
.enqueue = (void *)my_latency_enqueue,
.name = "latency_ninja",
};Cette implémentation illustre la puissance du "Direct Dispatch". En sautant l'étape de la file d'attente partagée pour les processus prioritaires, nous éliminons les verrous de contention (lock contention) globaux. Les processus standards, en revanche, subissent un traitement classique via SCX_DSQ_GLOBAL, évitant ainsi d'affamer complètement le reste du système (starvation). Le paramètre SCX_ENQ_WAKEUP indique au processeur qu'une préemption immédiate de sa tâche actuelle est recommandée.
Déploiement et analyse de l'intégration noyau
Le déploiement d'un tel programme requiert un binaire espace-utilisateur, souvent écrit en Rust ou en C avec libbpf, appelé "loader". Ce loader va compiler le code objet, le soumettre au vérificateur du noyau, et attacher dynamiquement la structure sched_ext_ops. Voici un aperçu de la séquence de chargement dans un terminal d'administration système.
# Chargement de l'ordonnanceur BPF personnalisé en production
sudo ./latency_ninja_loader --attachRésultat:
[INFO] Loading BPF object latency_ninja.bpf.o
[INFO] BPF verifier passed in 12ms
[SUCCESS] Scheduler 'latency_ninja' successfully attached.
[METRICS] Active DSQs: 1 Global, 32 Local (Per-CPU)
[SYSTEM] SCHED_EXT is now managing 142 active threads.À l'instant où la balise "[SUCCESS]" s'affiche, le comportement fondamental du système est altéré. Vous n'avez pas redémarré de services, ni interrompu de trafic réseau, mais la politique d'accès au CPU de votre serveur a été atomiquement remplacée. En cas d'erreur de segmentation dans votre loader ou si vous tuez le processus via SIGTERM, le noyau désinscrit instantanément latency_ninja.bpf.o et relance le comportement standard de manière transparente.
Attention à la Famine de Tâches
Soyez extrêmement méticuleux avec le "Direct Dispatch" (SCX_DSQ_LOCAL). Si vos tâches prioritaires sont liées au CPU (CPU-bound) et ne rendent jamais la main, les tâches reléguées dans la file globale ne s'exécuteront plus. Implémentez toujours un mécanisme de "yield" volontaire ou surveillez les compteurs de famine eBPF natifs.
Une Nouvelle Ère pour l'Ingénierie Système
Maîtriser sched_ext revient à débloquer le dernier niveau d'optimisation d'infrastructure. Là où l'on devait auparavant se contenter de modifier des paramètres systctl abstraits ou de jongler avec l'isolation de cœurs physiques (CPU pinning/isolcpus), nous pouvons aujourd'hui coder une logique métier directement dans l'algorithme d'ordonnancement. C'est l'évolution logique et inéluctable de l'observabilité eBPF transformée en actionnabilité eBPF.
Cependant, avec ce contrôle absolu vient une responsabilité architecturale majeure. Un ordonnanceur mal pensé peut détruire les performances d'une flotte entière de serveurs. La clé du succès réside dans l'itération : commencez par des politiques simples, analysez les métriques de latence grâce aux histogrammes de tracepoints, puis affinez vos dispatch queues. Le noyau Linux vous offre ses clés, à vous d'en faire bon usage.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
25 commentaires
Pour ceux qui veulent tester, commencez par cloner le repo
sched_ext/scxsur GitHub.Il y a des exemples déjà tout faits dans le répertoire
scheds/qui sont parfaits pour décortiquer la logique de dispatch.Tu as une limite de mémoire BPF, mais tu peux en créer des centaines. Par contre, attention à la gestion de la mémoire du kernel.
Une
DSQpar container, c'est ambitieux. Teste bien la montée en charge avant de déployer ça sur 1000 containers.C'est quoi la limite de nombre de
DSQqu'on peut créer ?Je voudrais en faire une par container pour isoler les latences.
Les
tracepointsnatifs desched_extsont tes meilleurs amis.Active-les, envoie ça dans une map, et fais un petit dashboard. C'est mieux que de deviner avec des outils externes.
Vous utilisez quel outil pour profiler les temps d'exécution de vos fonctions BPF ?
J'utilise
bpftracemais c'est pas toujours très lisible pour dustruct_ops.C'est un compromis constant. Plus ta logique est complexe, plus ton
enqueueest lourd.La règle d'or : garde le code BPF le plus court possible. Si tu dois faire des calculs complexes, déporte-les dans un thread user-space et envoie juste des ordres au BPF.
Sympa l'exemple de code. Par contre, c'est quoi l'impact sur le
context switch?Parce que si on rajoute trop de logique dans
enqueue, on risque de ralentir le réveil du processus lui-même.L'API BPF est stable, mais les structures internes du noyau (comme
task_struct) changent. C'est pour ça qu'on utiliseCO-RE(Compile Once - Run Everywhere).Tant que tu utilises
vmlinux.hgénéré à la volée, tu es tranquille.Est-ce que le code
SEC("struct_ops/my_latency_enqueue")est portable entre différentes versions du kernel ?J'ai peur que le format change tous les 6 mois.
Pas encore en standard, mais les devs bossent dessus. Pour le desktop, l'intérêt est limité par rapport à un CFS bien tuné, sauf si tu fais du montage vidéo hardcore.
Le vrai terrain de jeu, c'est le cloud haute densité.
J'ai hâte de voir ça débarquer sur les distros grand public. Pour l'instant, c'est très orienté serveur spécialisé.
Vous avez des retours sur l'utilisation pour le gaming ou le desktop ?
Oui, c'est atomique. Le noyau bascule les pointeurs de fonction vers ton code BPF instantanément.
Par contre, fais gaffe à ne pas introduire de régression sur le premier paquet de scheduling, sinon tu auras un pic de latence au moment du switch.
On peut remplacer l'ordonnanceur à chaud sans downtime ?
Genre
./latency_ninja_loader --attachça switch instantanément sur un serveur en prod qui tourne à 80% de load ?Oui, carrément. Tu peux inspecter la topologie via les structures du noyau accessibles dans BPF.
Tu peux mapper tes
DSQpar nœud NUMA et forcer le dispatch là où se trouvent les données chaudes. C'est là que tu gagnes les microsecondes critiques.C'est possible de faire du
NUMA-awarescheduling avec ça ?Si j'ai des threads qui partagent les mêmes données, je veux qu'ils restent sur le même socket.
C'est tout le danger. C'est pour ça que j'ai précisé de garder une file
SCX_DSQ_GLOBALpour les tâches standards.Si tu privilégies tout, tu ne privilégies rien. Il faut savoir sacrifier les jobs batch.
Le
latency_ninja, c'est bien pour le micro-burst, mais pour du calcul lourd, ça ne risque pas de créer de la famine sur les processus background ?Il faut que ta version de
bpftoolcorresponde à celle de ton noyau cible. Si tu es sur un 6.11+, assure-toi d'avoir les derniers outils de la branchebpf-next.Vérifie aussi ton
PATH, c'est souvent là que ça merde avec les anciennes versions installées par le système.J'ai essayé de compiler le loader avec
clang, mais j'ai des erreurs de headers avecvmlinux.h.Vous utilisez quelle version de
bpftoolpour générer les en-têtes ?Excellente question. Tu dois gérer toi-même l'intégration
cgroupsdans ton code BPF si tu veux respecter les limites de quota.Par défaut,
sched_extte donne les clés du camion, donc si tu ne codes pas la logique de limite, c'est open bar sur les ressources.Article solide. Par contre, quid de la compatibilité avec
cgroups v2?Est-ce que l'ordonnanceur BPF respecte les limites de ressources définies dans les slices ou il fait sa propre tambouille au-dessus ?
Utilise les
bpf_mapspour exporter tes stats de remplissage des files. Tu peux lire ces maps depuis l'espace utilisateur sans surcoût majeur.Évite juste de faire du logging verbeux dans
ops.enqueue, sinon tu vas tuer ton cache L1 pour rien.J'ai testé en lab sur un noyau 6.12. C'est impressionnant pour le
direct dispatch.Mais comment on fait pour monitorer la charge des
DSQen temps réel sans impacter les perfs ?Le fallback est géré par le noyau directement. Si ton programme BPF plante ou dépasse le temps imparti,
sched_extle dégage et repasse sur CFS sans que tu perdes la main sur la machine.C'est du C contraint, le vérificateur ne laisse rien passer. Si ça compile, c'est que ça ne va pas bloquer le CPU indéfiniment.
Putain enfin. J'en avais marre de me battre avec
isolcpuset les interruptions qui foutent le bordel sur mes threads de trading.Par contre, c'est quoi le risque réel si le
schedulerboucle sur un cas limite ? Le fallback vers CFS est vraiment instantané ou on sent une latence ?