Naviguez dans la Complexité : Graphes de Connaissances pour une Observabilité DevOps Intelligente
Vous est-il déjà arrivé de fixer un dashboard Grafana surchargé, noyé sous une avalanche de métriques, sans pour autant comprendre l'origine réelle d'une latence insidieuse ? Cette surcharge informationnelle est le symptôme d'une complexité que nos outils traditionnels peinent à modéliser. Nos architectures microservices, si puissantes soient-elles, ont créé un réseau de dépendances si dense que la simple corrélation de logs et de traces ne suffit plus.
Pourtant, une approche émerge pour transformer ce chaos en clarté. Elle ne se contente pas de collecter des données, mais se concentre sur ce qui les relie : les relations. Il est temps de penser au-delà des listes et des chronologies pour embrasser une vision connectée de nos systèmes grâce aux graphes de connaissances.
Le Graphe de Connaissances : Quand les Données Racontent une Histoire
L'idée fondamentale derrière un graphe de connaissances est de cartographier non seulement les composants de votre infrastructure (services, bases de données, clusters Kubernetes), mais surtout les interactions dynamiques qui les unissent. On passe d'une collection de points de données isolés à une représentation vivante et contextuelle de l'ensemble de votre système.
Qu'est-ce qu'un Graphe, Concrètement ?
Imaginez une carte où chaque ville est un microservice, un pod ou une base de données. Les routes entre ces villes représentent les appels API, les dépendances réseau ou les flux de données. Un Graphe de Connaissances est cette carte, enrichie en temps réel avec des informations provenant de toutes vos sources de données. Il modélise votre écosystème comme un ensemble de nœuds (les entités) et d'arêtes (leurs relations).
Cette structure permet de poser des questions complexes qu'un système de métriques classique ne peut pas traiter. Par exemple : "Quels services clients seront impactés si la base de données pg-user-prod-01 subit une latence de 200ms ?" La réponse ne se trouve pas dans une métrique, mais dans la topologie des relations.
Comparaison avec l'Observabilité Traditionnelle
Pour bien saisir la rupture que cela représente, comparons les deux approches. La différence ne réside pas dans les données collectées, mais dans la manière de les structurer et de les interroger pour en extraire de la valeur.
| Critère | Approche Traditionnelle (Silos) | Approche par Graphe de Connaissances |
|---|---|---|
| Focalisation | Données isolées (logs, métriques, traces) | Relations et dépendances entre les données |
| Analyse | Corrélation manuelle ou basée sur le temps | Exploration de la topologie et des chemins de causalité |
| Type de Question | "Quel est l'état du service A ?" | "Comment un échec du service C impacte-t-il le service A ?" |
| Investigation | Réactive, navigation entre plusieurs outils | Proactive, vue unifiée et contextuelle des incidents |
Le Graphe en Action : De la Théorie à la Résolution d'Incidents
Le véritable pouvoir d'un graphe de connaissances se révèle lors des moments critiques : quand un service ralentit, qu'une fonctionnalité tombe en panne ou qu'il faut évaluer l'impact d'une nouvelle mise en production. Il transforme l'investigation en une exploration guidée par le contexte.
Accélérer l'Analyse de Cause Racine (RCA)
Imaginons un scénario classique : les utilisateurs se plaignent de lenteurs sur le panier d'achat d'un site e-commerce. Sans graphe, votre équipe commence une chasse au trésor stressante, sautant d'un dashboard à l'autre, épluchant des logs de multiples services. Le temps presse et la pression monte.
Avec un graphe, le point de départ est le service directement exposé à l'utilisateur, ici le front-end-checkout. En explorant ses dépendances, le graphe révèle immédiatement que ce service appelle une API Gateway, qui elle-même interroge deux microservices : le service de Paiement et le service d'Inventaire. Le graphe, enrichi des métriques de latence, met en évidence que le service d'Inventaire répond anormalement lentement.
En poursuivant l'exploration sur ce nœud, on découvre qu'il dépend d'une base de données MySQL dont l'utilisation CPU est anormalement élevée. En quelques clics, vous avez identifié un chemin de causalité clair, de la base de données jusqu'à l'impact client, réalisant ainsi une Analyse de Cause Racine en quelques minutes au lieu de plusieurs heures.
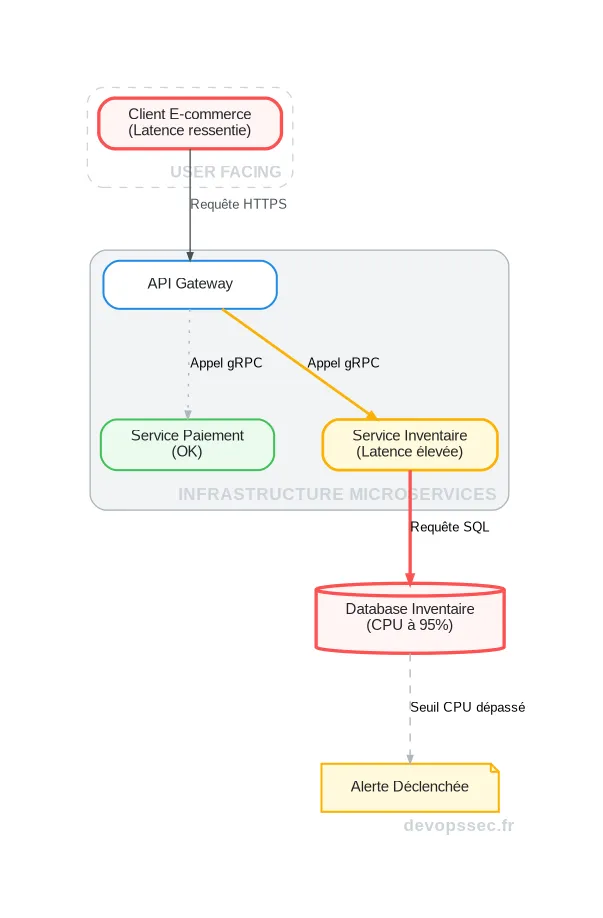
Ce schéma illustre parfaitement le chemin de l'incident. La latence, visible sur le client web, est directement tracée à travers les appels de service jusqu'à la source du problème : la base de données de l'inventaire. Le graphe ne montre pas seulement des métriques, il expose le "blast radius", c'est-à-dire la portée de l'impact de la défaillance.
Anticiper l'Impact des Changements
L'autre force des graphes est leur capacité à simuler des scénarios. Avant de déployer une nouvelle version du service d'authentification, vous pouvez interroger le graphe pour identifier l'ensemble des services qui en dépendent directement ou indirectement. Cela transforme la gestion du changement et la planification des déploiements.
CI/CD et Graphe de Connaissances
En intégrant les données de votre pipeline de CI/CD (commits, builds, versions de déploiement) dans le graphe, vous pouvez corréler un incident non seulement à une défaillance technique, mais aussi à un déploiement ou un changement de configuration spécifique. Cela boucle la chaîne de l'idée à la production.
Cette approche proactive permet de répondre à des questions cruciales avant même d'écrire une ligne de code pour le déploiement :
- Quelles équipes doivent être prévenues de la maintenance de ce service ?
- Quels tests de non-régression sont critiques pour valider ce changement ?
- Si ce déploiement échoue, quelle est la procédure de rollback la plus sûre et quels services seront affectés durant l'opération ?
Construire et Alimenter votre Graphe : Une Question de Stratégie
Mettre en place un graphe de connaissances n'est pas simplement une question d'outil, mais d'une refonte de la manière dont vous collectez et structurez vos données d'Observabilité. Il faut penser en termes d'entités et de relations dès la source.
La Collecte de Données Contextualisées
Le carburant de votre graphe, ce sont les données. Plus elles sont riches et variées, plus votre carte du système sera précise. Il ne s'agit pas seulement des trois piliers classiques (métriques, logs, traces), mais de tout ce qui peut ajouter du contexte.
Voici un exemple de données que l'on pourrait injecter pour décrire un seul pod Kubernetes dans le graphe. Notez comment chaque attribut peut devenir un point de connexion avec d'autres entités.
entity:
id: pod-checkout-7c6b4f7b5f-xyz12
type: Pod
properties:
name: pod-checkout-7c6b4f7b5f-xyz12
namespace: prod-ecommerce
status: Running
ip: 10.244.1.15
image: registry.example.com/checkout-service:v2.1.3
node: k8s-worker-node-03
relations:
- type: RUNS_ON
target: k8s-worker-node-03
- type: PART_OF
target: deployment-checkout-service
- type: PULLS_IMAGE_FROM
target: registry.example.com/checkout-service:v2.1.3
- type: ACCEPTS_TRAFFIC_FROM
target: service-checkout-loadbalancerCe simple bloc de données YAML montre comment un pod est lié à son nœud, à son déploiement, à son image Docker et au service qui lui envoie du trafic. Chaque relation est une arête potentielle dans votre graphe.
Les Risques et Coûts à ne pas sous-estimer
Adopter les graphes de connaissances n'est pas une solution magique. Cette approche introduit sa propre couche de complexité. La construction et la maintenance du modèle de données (le schéma du graphe) nécessitent une expertise spécifique. Un modèle mal conçu peut rapidement devenir un "plat de spaghettis" illisible et inexploitable.
De plus, le stockage et l'interrogation d'un graphe à grande échelle peuvent être coûteux en ressources de calcul. Les bases de données de graphes (comme Neo4j ou Amazon Neptune) sont optimisées pour ce type de charge, mais elles demandent une administration et un suivi attentifs. Enfin, la qualité du graphe dépend entièrement de la qualité des données en entrée : des données incorrectes ou incomplètes mèneront à des conclusions erronées, ce qui peut être pire que l'absence de données.
Conclusion : Vers une Résilience Opérationnelle Intelligente
Les graphes de connaissances ne remplacent pas les dashboards et les alertes traditionnels, ils les augmentent. Ils apportent la pièce manquante du puzzle de l'observabilité moderne : le contexte. En modélisant les relations complexes qui régissent nos systèmes distribués, ils nous permettent de passer d'une posture réactive, où l'on subit les incidents, à une posture proactive et prédictive.
Pour vous, ingénieur DevOps qui débutez, c'est un changement de paradigme. Ne vous contentez plus de regarder des métriques isolées. Commencez à penser en termes de flux, de dépendances et de chemins de causalité. C'est en comprenant ces connexions que vous transformerez des systèmes complexes en écosystèmes résilients et maîtrisés.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
21 commentaires
Prépare bien tes données en entrée. Le plus dur c'est pas le graphe, c'est la qualité de l'inventaire de tes ressources.
Je vais essayer de mapper mon infra avec ça, on verra si ça survit au premier incident.
La doc est super claire, merci. Ça change des articles vagues sur l'observabilité.
Tu ajoutes un TTL sur les arêtes. Si le job ne heartbeat pas, le contrôleur supprime la relation automatiquement.
Comment tu gères les relations temporaires, genre un job batch qui tourne 5 minutes ?
Si, clairement. Si t'as 3 microservices, tes dashboards Grafana suffisent largement.
Le graphe, c'est pour quand tu ne comprends plus ton propre système.
C'est pas un peu overkill pour des petites infra ?
Oui, un simple call API vers ta base graphe à la fin du déploiement.
Ça permet de lier le déploiement à l'entité service directement.
Et pour le CI/CD, tu injectes ça comment ? Une étape dans le pipeline ?
C'est la puissance des requêtes récursives. Tu pars du nœud en erreur et tu cherches tous les nœuds en amont via les relations
ACCEPTS_TRAFFIC_FROM.La partie sur le "blast radius" m'intéresse. Comment tu calcules ça automatiquement sans avoir à le définir à la main ?
Bien vu. L'indexation est obligatoire. Si tu ne définis pas d'index sur tes
idoutype, tes requêtes de parcours de graphe vont ramer dès que tu dépasses quelques milliers de nœuds.C'est normal, faut indexer tes propriétés sur les nœuds, sinon le moteur fait un full scan et c'est fini.
J'ai testé Neptune sur AWS, la latence sur des requêtes complexes est parfois violente.
Il faut un contrôleur qui écoute les événements de l'API Kubernetes.
C'est comme ça que tu maintiens ton graphe en temps réel sans te prendre la tête.
Le YAML que tu montres pour le pod est cool, mais tu fais comment pour maintenir ça à jour quand le cluster bouge toutes les minutes ?
Exactement. Ne mets pas tes logs bruts dans la base graphe.
Utilise un
sidecarpour extraire uniquement les métadonnées et les relations, puis envoie le reste dans ton stack ELK ou Loki habituel.Bonne question. Perso j'utilise juste les logs pour enrichir, pas pour stocker le brut dans le graphe.
Tu parles de stocker ça dans Neo4j. Ça consomme pas trop de ressources si tu fais du streaming de logs en temps réel ?
C'est le risque principal. La clé c'est de rester strict sur le schéma dès le départ.
Si tu laisses tout le monde injecter n'importe quelle relation, t'es mort. Il faut automatiser la découverte des relations via les tags Kubernetes.
Encore un énième buzzword. Concrètement comment tu évites que ton graphe devienne un plat de spaghettis illisible après 6 mois ?