Cyber-Immunity Autonome : Quand l'Infra DevOps s'Auto-Défend
As-tu déjà imaginé une infrastructure qui ne se contente pas de subir une attaque en attendant qu'un humain intervienne, mais qui la détecte, l'analyse et s'en guérit elle-même en quelques millisecondes ? Ce n'est plus de la science-fiction. Nous entrons dans l'ère de la cyber-immunité, où nos systèmes, conçus selon les principes DevOps, développent leur propre système de défense autonome.
Oublie l'image du gardien de sécurité qui fait des rondes. Pense plutôt à un système immunitaire biologique : une armée de cellules intelligentes qui identifient, neutralisent et mémorisent les menaces sans intervention consciente. C'est précisément ce paradigme que nous transposons aujourd'hui à nos architectures Cloud Native.
L'idée fondamentale est de passer d'une sécurité périmétrique statique, qui s'effrite à la moindre brèche, à une sécurité intrinsèque, distribuée et adaptative. Chaque composant de l'application, du pod Kubernetes à la fonction serverless, devient un acteur de sa propre protection.
Les Fondations de l'Immunité : Au-delà de la Sécurité Traditionnelle
Pour construire un système capable de s'auto-défendre, il faut d'abord lui donner des sens. Un système aveugle et sourd ne pourra jamais réagir intelligemment. C'est ici que l'observabilité cesse d'être un simple outil de débogage pour devenir le système nerveux central de notre infrastructure.
L'Observabilité comme Système Nerveux Central
L'Observabilité va bien au-delà du simple monitoring. Le monitoring te dit QUAND quelque chose ne va pas, alors que l'observabilité te donne les clés pour comprendre POURQUOI. Elle s'appuie sur la corrélation de trois types de signaux fondamentaux qui, ensemble, dressent un portrait haute-fidélité de la santé et du comportement de ton système.
Concrètement, sans cette capacité à poser des questions complexes à ton système en temps réel, toute tentative d'automatisation de la défense serait vouée à l'échec. C'est la qualité des données collectées qui déterminera la pertinence des réponses automatisées.
- Logs (Journaux) : Ils fournissent un enregistrement granulaire et horodaté de chaque événement discret. Une tentative de connexion échouée, une erreur applicative, une requête API... C'est la mémoire brute du système.
- Metrics (Métriques) : Ce sont des mesures numériques agrégées dans le temps. L'utilisation du CPU, la latence réseau, le nombre de requêtes par seconde... Elles donnent le pouls, la tendance générale de la performance.
- Traces (Distribuées) : Elles cartographient le parcours complet d'une requête à travers les multiples microservices de ton application. Elles sont cruciales pour identifier les goulots d'étranglement ou un comportement malveillant qui se propage.
Le "Pattern Matching" Comportemental grâce à l'IA
Une fois que nous collectons ce volume colossal de données, un humain ne peut plus les analyser efficacement. C'est là que l'intelligence artificielle entre en jeu, non pas comme un gadget, mais comme le cerveau analytique de notre système immunitaire. Des modèles de Machine Learning sont entraînés en continu sur le flux de données d'observabilité.
Leur mission n'est pas de chercher des signatures d'attaques connues, une approche dépassée face aux menaces "zero-day". Leur but est d'apprendre ce qu'est le comportement normal de l'application dans ses moindres détails. Toute déviation significative par rapport à cette ligne de base est alors considérée comme une anomalie suspecte, digne d'une investigation immédiate et automatisée.
Voici un exemple conceptuel de ce à quoi pourrait ressembler une règle de détection comportementale pour un moteur d'analyse, définie en YAML. Elle ne se base pas sur une IP malveillante, mais sur une séquence d'actions atypiques.
apiVersion: security.mycorp.io/v1alpha1
kind: AnomalyDetectionPolicy
metadata:
name: unusual-db-export-behavior
spec:
target:
kind: Pod
labels:
app: backend-api
behavior:
description: "Détecte un pod qui accède à plus de 1000 profils utilisateurs puis initie une connexion sortante vers une IP inconnue."
trigger:
- sequence:
- event:
type: "DatabaseQuery"
filter: "query.table == 'users' && query.rows_returned > 1000"
count: 1
within: "5m"
- event:
type: "NetworkFlow"
filter: "net.direction == 'egress' && !net.destination.is_known_provider"
count: 1
within: "1m"
action:
type: IsolatePod
params:
networkPolicy: "deny-all-egress"
logLevel: "CRITICAL"L'Architecture d'un Système d'Auto-Défense DevOps
Pour orchestrer cette immunité, il nous faut une architecture en boucle fermée, souvent inspirée de la boucle OODA (Observer, Orienter, Décider, Agir) militaire. Chaque étape est automatisée pour garantir une vitesse de réaction que nul humain ne pourrait égaler, transformant le pipeline CI/CD en un véritable système de résilience continue.
Le schéma ci-dessous illustre ce flux constant d'informations et de décisions, où le système apprend et s'adapte en permanence face aux menaces émergentes sans aucune interruption de service.
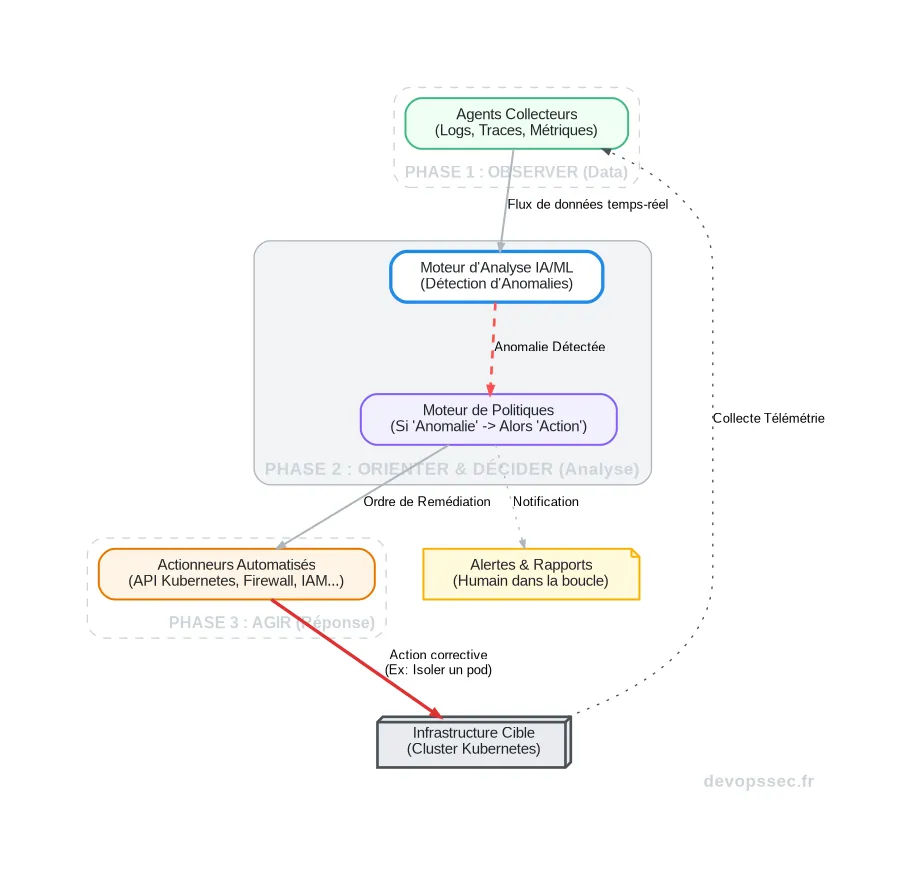
Ce diagramme illustre la boucle de rétroaction au cœur de la Cyber-Immunité. Les agents collectent la télémétrie depuis l'infrastructure (par exemple, un cluster Kubernetes), le moteur d'IA analyse ce flux pour détecter des déviations, le moteur de politiques décide de l'action à prendre selon des règles prédéfinies, et enfin les actionneurs appliquent la correction directement sur l'infrastructure. La boucle est bouclée.
Exemples d'Actions Correctives Automatisées
L'efficacité de ce système réside dans la pertinence et la rapidité de ses actions. Il ne s'agit pas seulement de bloquer une adresse IP. Les réponses sont contextuelles, chirurgicales et visent à préserver la continuité de service tout en neutralisant la menace. Loin d'être de simples scripts, ce sont des opérations orchestrées via les APIs des plateformes Cloud ou de Kubernetes.
| Type de Menace Détectée | Action Automatisée | Objectif de Résilience |
|---|---|---|
| Exfiltration de données depuis un pod | Application instantanée d'une NetworkPolicy sur le pod pour bloquer tout le trafic sortant. | Contenir la brèche immédiatement sans impacter les autres services. |
| Pic de trafic anormal (DDoS L7) | Mise à l'échelle horizontale automatique du service ciblé et ajustement des règles du WAF. | Maintenir la disponibilité du service en absorbant l'attaque. |
| Clé d'API compromise détectée dans un log | Révocation de la clé via l'API IAM, rotation automatique du secret dans le vault et redéploiement des pods concernés. | Éliminer le vecteur d'attaque avant qu'il ne puisse être exploité. |
| Comportement suspect d'un processus dans un conteneur | Mise en quarantaine du pod, dump de sa mémoire pour analyse forensique, puis destruction et remplacement par une instance saine. | Neutraliser la menace et collecter des preuves pour une analyse post-mortem. |
Les Limites et les Garde-fous Indispensables
Conférer une telle autonomie à nos systèmes est extrêmement puissant, mais cela comporte aussi des risques non négligeables. Une confiance aveugle dans l'automatisation sans des mécanismes de contrôle stricts peut conduire à des catastrophes opérationnelles bien plus rapides et dévastatrices qu'une attaque manuelle.
Le Risque des Faux-Positifs et des Réactions en Cascade
Que se passe-t-il si le modèle d'IA se trompe ? Un faux-positif, c'est-à-dire une anomalie détectée qui est en réalité un comportement légitime mais rare (comme un batch de fin de mois), pourrait déclencher une réponse de sécurité disproportionnée. Isoler un pod de paiement en plein pic d'activité parce que son comportement a été jugé "anormal" peut coûter des millions.
Pire encore, une mauvaise décision automatisée peut entraîner une réaction en cascade. Un service isolé à tort peut rendre d'autres services indisponibles, qui seront à leur tour jugés anormaux, menant à un effondrement partiel ou total du système. La vitesse de l'automatisation devient alors un ennemi.
Le principe du "Human-in-the-Loop"
Pour démarrer, il est crucial d'implémenter ces systèmes en mode "dry-run" (ou audit). Le système détecte et recommande une action, mais c'est un opérateur humain qui valide son exécution. Progressivement, à mesure que la confiance dans le modèle augmente, on peut automatiser les actions les moins risquées, en gardant une supervision humaine pour les décisions critiques.
Coûts Cachés et Complexité de la Mise en Œuvre
Mettre en place une véritable cyber-immunité n'est pas aussi simple que d'installer un logiciel. Cela demande des investissements significatifs et des compétences pointues. L'entraînement et l'inférence des modèles de Machine Learning en temps réel consomment des ressources de calcul importantes, ce qui a un impact direct sur la facture cloud.
De plus, l'expertise nécessaire pour construire, maintenir et surtout affiner ces systèmes est rare. Il faut des ingénieurs qui maîtrisent à la fois l'infrastructure, la sécurité et la science des données. C'est un changement culturel profond qui impacte toute l'organisation DevOps, bien au-delà d'un simple projet technique.
Enfin, l'intégration de ces outils dans les chaînes CI/CD existantes demande un travail d'ingénierie considérable pour que la sécurité soit testée et validée au même titre que les fonctionnalités applicatives, sans pour autant ralentir les cycles de livraison.
# Exemple de log d'un faux-positif potentiel
# Le système pourrait interpréter le scan de vulnérabilités légitime comme une attaqueRésultat:
time="2026-03-15T10:30:05Z" level=warning msg="Anomaly Detected: High port scanning activity" source.pod="trivy-scanner-job-h7s2" destination.namespace="prod-backend" confidence=0.85 recommended_action="ISOLATE_POD" action_status="PENDING_APPROVAL"Dans ce cas, le système a sagement attendu une validation humaine car le pod source est un scanner de sécurité connu, ce qui rend l'intention ambiguë pour la machine.
Conclusion : Vers une Résilience Opérationnelle Proactive
La cyber-immunité autonome n'est pas une solution magique, mais une évolution naturelle et nécessaire de la philosophie DevOps face à un paysage de menaces qui évolue à une vitesse fulgurante. Elle représente le passage d'une posture réactive, où nous courons pour éteindre des incendies, à une posture proactive où le système lui-même est conçu pour être intrinsèquement résilient.
Pour toi, jeune ingénieur DevOps, cela signifie que la sécurité ne peut plus être une réflexion après coup ou la responsabilité d'une autre équipe. Elle doit faire partie de l'ADN de chaque ligne de code, de chaque fichier de configuration d'infrastructure que tu écris. Commence par maîtriser l'observabilité, intéresse-toi aux bases de l'IA appliquée à l'analyse de données, et surtout, pense toujours en termes de systèmes dynamiques et adaptatifs.
Le but ultime n'est pas de construire une forteresse imprenable, car de telles forteresses n'existent pas. Le but est de construire un organisme vivant, capable d'encaisser les coups, d'apprendre de chaque attaque et de guérir plus vite que l'adversaire ne peut frapper. C'est ça, la véritable résilience opérationnelle de demain.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
On utilise des contextes de déploiement. Si le pod vient d'un namespace
security-tools, le score de confiance est pondéré différemment.C'est pas binaire, c'est du scoring probabiliste. L'ambiguïté est gérée par le contexte.
La question du faux-positif n'est toujours pas résolue. Comment tu différencie un scan de vulnérabilité légitime d'un vrai scan malveillant ?
Ton exemple de log montre bien que même avec 0.85 de confiance, ça reste ambigu.
Je ne dis pas que c'est pour demain pour tout le monde. C'est une vision vers laquelle il faut tendre.
Si on ne commence pas à automatiser la réponse, on ne pourra jamais suivre le rythme des menaces actuelles.
C'est trop théorique. En entreprise, on a déjà du mal à déployer des
NetworkPolicybasiques parce que les dev ne savent pas quels ports leurs applis utilisent.Alors leur demander de gérer une cyber-immunité autonome, c'est de la science-fiction.
Et si l'attaquant compromet le moteur d'IA lui-même ? Tu donnes les clés de la ville au système qui est censé nous protéger.
C'est une cible prioritaire pour n'importe quel hacker.
On passe par un bus d'événements type
NATSouKafkapour traiter les flux en quasi temps réel.C'est pas de la magie, c'est de l'ingénierie système classique pour minimiser la latence de traitement.
Je rejoins le 7. Les attaquants modernes sont très rapides. Une réponse basée sur des logs qui sont parfois bufferisés pendant 30s, c'est inutile.
Tu as quoi comme pipeline pour garantir que tes logs arrivent assez vite pour être utiles ?
C'est bien mignon ton YAML, mais en cas d'attaque réelle, l'attaquant aura déjà exfiltré ses données avant que ton modèle ait fini d'analyser les traces.
La latence de détection est le vrai problème ici.
C'est un risque. Pour éviter l'auto-DDoS, il faut des garde-fous comme ici :
C'est le principe du rate limiting appliqué aux décisions de sécurité.
Le problème de fond c'est la confiance. Automatisé ne veut pas dire fiable.
Si ton système décide de tuer des pods alors qu'il n'y a pas d'attaque, tu viens de créer toi-même ton propre DDoS.
J'ai implémenté un truc similaire avec des scripts basés sur
kubectlpour isoler des pods suspects. C'est déjà bien assez complexe.Vouloir tout abstraire dans une
CRDcustom, c'est juste ajouter une couche de complexité que personne ne saura maintenir dans 6 mois.Le coût du calcul est réel, c'est vrai. Mais compare-le au coût d'un ransomware qui bloque ton infra pendant 48h.
On ne parle pas de faire tourner des LLM lourds, mais des modèles légers entraînés sur des séquences d'événements.
Exactement. Et le coût en CPU pour faire tourner des modèles d'inférence sur chaque noeud, vous avez calculé ?
C'est une usine à gaz qui va plomber la facture AWS pour un gain de sécurité très théorique.
Ton approche demande une télémétrie parfaite. Dans la réalité, nos logs sont souvent incomplets ou mal formatés.
Si la donnée d'entrée est pourrie, ton IA va juste générer des alertes aléatoires. C'est garbage in, garbage out.
C'est pour ça que je parle de Human-in-the-Loop. Personne ne dit de mettre ça en mode automatique total dès le premier jour.
Le but est de réduire le bruit pour les Ops, pas de les remplacer par une boîte noire. Si tu as peur des faux-positifs, tu commences en mode
audituniquement.C'est clair. On a déjà assez de mal à gérer le
livenessProbesans qu'un agent externe vienne jouer aux apprentis sorciers avec nosNetworkPolicy.Qui va débuguer la boucle infinie quand le système décide d'isoler ses propres outils d'observabilité ?
Encore une abstraction de plus pour masquer la misère. Ton
AnomalyDetectionPolicyest jolie sur le papier, mais en prod, c'est juste un cauchemar à maintenir.Tu fais comment quand ton IA se trompe sur un pic de charge légitime ? Tu finis par isoler tes services critiques en plein Black Friday.