Introduction
C'est quoi le DevFest ?
Les DevFests ou "Developer Festival" sont des événements communautaires majeurs à travers le monde à but non lucratif suivant la tradition des Google Developer Days et sont organisés par des groupes d'utilisateurs locaux. Ils constituent une opportunité unique de partager et de réseauter autour du monde du web et des technologies cloud.
Ce sont donc plusieurs conférences réparties sur deux jours visant à réunir sous un même toit des étudiants, des professionnels, des curieux technophiles, des entreprises dans le secteur technologique ainsi que des conférenciers. Ils peuvent ainsi se renseigner sur les technologies émergentes Cloud, Machine Learning, intelligence artificielle, et plus encore.
Me concernant, j'ai participé au DevFests de Nantes organisé par le GDG (Google Developers Group) Nantes et qui a eu lieu le 21 et 22 octobre 2021 à la cité des congrès de Nantes (je n'ai participé qu'à la journée du 21). À ma grande surprise, l’organisation était très bien structurée, et ce malgré la pandémie actuelle et le nombre de participants (2000), cela est resté d’une grande fluidité.
Organisation du DevFest
Concernant l'organisation de cet événement durant ces 2 jours, il comprend trois types de sessions:
- Conférences (50 minutes) et Quickies (20 minutes): ce sont des présentations d'intervenants évoquant leurs technologies incluant les questions et réponses.
- Codelabs (2 heures): plus informels et sont l'occasion de mettre les mains (et les pieds) à travailler sur du code en compagnie d'un expert sur la technologie dans le domaine.
De plus, les sujets sont éparpillés sur 6 sessions parallèles (4 conférences et 2 codelab) et tournent autour du: Web (Frameworks, librairies, HTML, CSS...), outils et solutions Cloud et DevOps, Mobile && IoT, Backend, Big Data, Machine Learning, DevOps, Discovery (sujet pas forcément lié à la technique) etc ... La liste des sessions 2021 est disponible sur la page d'événements.
Ma participation aux différentes sessions
Conférence: Simuler 160K joueurs avec Cloud Run
Présentation du sujet
Première conférence de la journée que j'ai choisie pour son titre qui m'a beaucoup intrigué, de plus c'était le seul sujet Cloud et DevOps de cette matinée. Elle est présentée par Valentin Deleplace qui est Developer Advocates et ingénieur backend cloud senior chez Google.
Valentin Deleplace a co-animé donc cette conférence en nous expliquant comment le jeu Google I/O Adventure (mai 2021) a été conçu pour tenir la charge de 160 000 connexions simultanées sans s’effondrer. Et comment ils ont provisionné correctement les serveurs de jeu pour favoriser l'interaction avec les participants I/O lors de la conférence virtuelle qui s'est tenue cette année.
Il explique que le développement du jeu nécessitait une évolutivité pour gérer un nombre variable de participants. Son équipe a donc tiré parti de nombreux produits GCP, notamment de Google Compute Engine et Cloud Run. Lors de ce talk, il annonce pourquoi lui et l'équipe ont choisi Cloud Run et comment ils l'ont utilisé pour tester le jeu sous contrainte. Il parle des défis auxquels l'équipe a été confrontée et comment ils les ont surmontés pour produire une expérience fluide et agréable pour les participants du jeu.
Afin de répondre à tous ces défis, ils ont effectué des tests de charge et ont utilisé Cloud Run pour simuler des clients pour injecter des joueurs, détecter des bugs et des faiblesses architecturales. Par la suite, ils ont ajusté les composants Google Cloud côté serveur. Voici ci-dessous un schéma d'architecture de leur infrastructure présenté lors de la conférence:
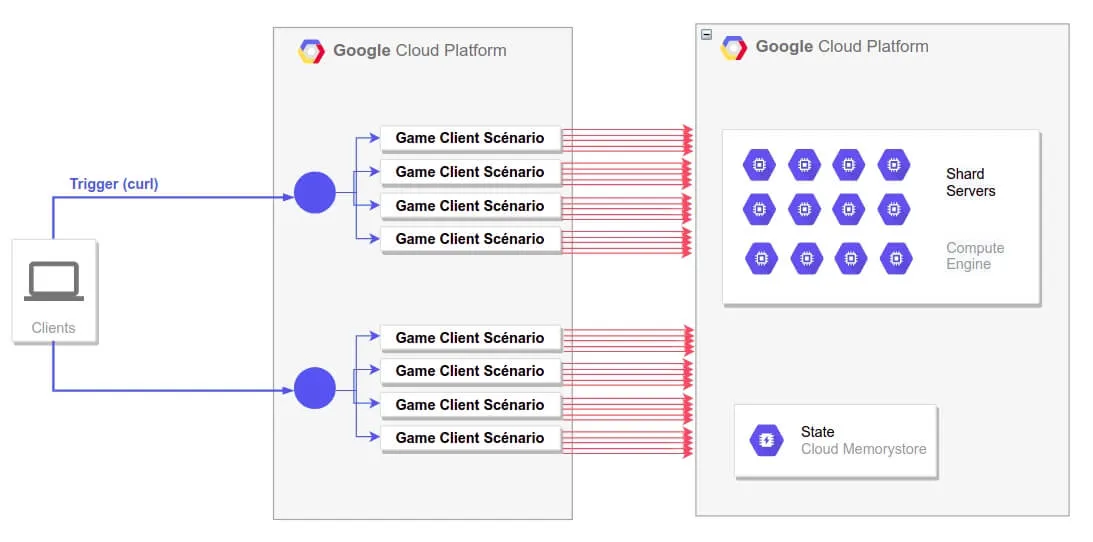
Comme évoquait plus haut, ils ont simulé plusieurs centaines de milliers de joueurs pour effectuer différents tests de charges à travers le service Cloud Run, qui est une plate-forme de calcul managée qui permet d'exécuter des conteneurs invocables via des requêtes ou des événements avec une approche serverless. Ce service permet donc de faire abstraction sur toute la gestion de l'infrastructure, afin que leur équipe puisse se concentrer sur ce qui compte le plus: créer des scénarios de test de qualité.
Avec ce type d'architecture serverless, les scénarios de tests ne sont lancés qu'en cas de besoin. Lorsqu'un événement déclenche l'exécution du code de l'application, le fournisseur de cloud public alloue dynamiquement des ressources pour ce code. L'utilisateur arrête donc de payer lorsque l'exécution du code est terminée, ce qui arrange leur équipe de développement qui effectue des tests sur une période bien définie.
Valentin explique alors qu'adopter ce type d'architecture implique de coder de façon à ce que l'application soit stateless. c'est-à-dire qu'elle ne doit pas stocker de données et ne fait référence à aucune transaction passée afin de traiter ces requêtes à court terme. Chaque transaction est effectuée à partir de rien, comme si c'était la première fois qu'elle s'exécutait.
Fonctionnement de l'architecture
Maintenant que vous avez compris l'intérêt du serverless et du service Cloud Run, regardons de plus près leur schéma d'infrastructure.
Dans un premier temps, un événement est déclenché depuis un poste de travail pour communiquer avec Cloud Run qui joue le rôle d’injecteurs dans la campagne de test c'est-à-dire que pour chaque trafic entrant dans Cloud Run cela crée une simulation de plusieurs joueurs en Socket qui vont interroger et stresser leurs différents serveurs NodeJS hébergés avec le service Compute Engine.
Pendant cette compagne de stress test, ils analysent les métriques sur les différents serveurs depuis Prometheus et Grafana (CPU, Mem, etc …) et ils estiment que si les indicateurs affichent une utilisation des ressources inférieures à 80% alors cela signifie que leurs serveurs sont capables de supporter la charge. Ils dirigeaient également leurs logs des jeux vers BigQuery pour les analyser ultérieurement.
Grâce à cette stratégie de test, ils avaient pour objectif de tester 80 000 joueurs connectés en simultanés mais ils ont au final réussi (comme le titre de la conférence) à supporter jusqu'à 160 000 joueurs. En réalité, il explique qu'ils ont eu 43 000 joueurs avec un pic de trafic situé à 10 000 joueurs. Il conclut cette conférence en disant "mieux vaut être trop prudent que pas assez".
Conférence: GitOps to the Edge and Infrastructure Provisioning
Présentation du sujet
Pour cette tranche d'horaire j'avais le choix entre 2 sujets DevOps, celui-ci et le second "Github Actions : enfin des pipelines accessibles aux développeurs". Je ne travaille pas forcément avec Github lors de mes missions chez des clients, et il faut le dire aussi le terme "GitOps" combiné avec "Infrastructure Provisioning" m'avait vraiment beaucoup intrigué. Cette conférence est présentée par Katie Gamanji qui est Ecosystem Advocate chez la CNCF (Cloud Native Computing Foundation).
Information
La CNCF est un projet de la Linux Foundation qui a été fondé en 2015 pour aider à faire progresser la technologie des conteneurs et à aligner l'industrie technologique sur son évolution. Actuellement ce sont eux qui gère le projet Kubernetes.
Elle commence par expliquer qu'au cours de ces 7 années d'existence, Kubernetes a été la pièce maîtresse du paysage Cloud. Ce qui a conduit à la diversification de solutions sur cet écosystème technologique qui se concentrent la pluspart du temps sur la normalisation, les directives et l'interopérabilité des outils. Et donc, pour innover dans l'expérience des développeurs et la livraison de l'application, la communauté s'est concentrée sur la restructuration et la modernisation des opérations CI/CD.
L'objectif de cette conférence est donc de nous décrire comment les outils GitOps tels que ArgoCD et Flux, débloquent le déploiement sans intervention des ops et des devs. Le but étant que nous les participants acquerront une compréhension basique de l'utilisation de GitOps en association avec ClusterAPI pour le provisionnement de l'infrastructure et KubeEdge pour la propagation du service à la périphérie.
C'est quoi GitOps ?
Peut-être que c'est la première fois que vous entendez parler du mot "GitOps" ? C'était le cas pour moi aussi, c'est pour cela qu'une petite explication de ce terme est nécessaire avant de passer à la suite.
GitOps est un ensemble de pratiques pour gérer les configurations d'infrastructure et d'applications à l'aide de Git, un système de contrôle de versions open source. Il fonctionne donc en utilisant Git comme source de configuration unique pour l'infrastructure et les applications déclaratives. Le but étant de gérer automatiquement le provisionnement et le déploiement de l'infrastructure à chaque modification d'état du référentiel Git qui contient l'état du système complet afin que la trace des modifications apportées à l'état du système soit visible et auditable.
Katie nous avait décrit l'intérêt du GitOps afin de permettre aux ingénieurs de spécifier l'état souhaité d'un cluster k8s, généralement via une configuration YAML déclarative, et d'utiliser des outils tels que Fluxcd ou ArgoCD (deux projets d'incubation du CNCF) pour s'assurer que l'état du cluster correspond à la spécification stockée dans Git, qui facilitent ainsi le déploiement, la restauration et l'audit.
Cluster API
En ce qui concerne la création de clusters, elle explique que de nombreuses solutions et distributions ont été mises en place pour simplifier le processus d'amorçage Kubernetes entre les fournisseurs de cloud. L'un des outils incubé par la CNCF dans le paysage open source est nommé Cluster API, qui est un sous-projet Kubernetes axé sur la fourniture d'API déclaratives et d'outils pour simplifier le provisionnement, la mise à niveau et l'exploitation de plusieurs clusters Kubernetes facilitant une interface commune pour la création de plateformes entre les fournisseurs existants (par exemple: GCP, AWS, Azure, Alibaba Cloud, Packet).
Au cours de son discours, elle évoqua également que la prochaine étape dans la génération de plate-forme est la création de modèles et l'automatisation. Par défaut, un ensemble de manifestes peuvent être paramétrés et empaquetés avec Helm et Kustomize. Cela permet la personnalisation de clusters avec des exigences techniques prédéfinies dans différentes régions et fournisseurs de cloud. De plus, il convient de mentionner qu'elle a recommandé de stocker les manifestes, graphiques et modèles existant dans un référentiel git. Cela débloque l'intégration des outils GitOps, qui solutionne la partie automatisation de la génération de clusters. Les implémentations populaires de GitOps sont présentées par Flux et ArgoCD.

KubeEdge
Elle a fini par nous parler d'un autre projet dont la CNCF a validé l'entrée comme un projet à incuber nommé KubeEdge. C'est un système open source étendant l'orchestration d'applications conteneurisées natives et la gestion des appareils aux hôtes à la périphérie. Il est basé sur Kubernetes et fournit un support d'infrastructure de base pour la mise en réseau, le déploiement d'applications et la synchronisation des métadonnées entre le cloud et la périphérie (Edge Computing).
qu'est ce que l'edge computing ?
Avant de découvrir l'outil, prenant un peu de temps pour comprendre l'intérêt de l'Edge Computing. Voici la définition simple proposée par Wikipédia:
Définition de l'Edge Computing
L'edge computing ("informatique en périphérie" ou "informatique en périphérie de réseau") est une méthode d'optimisation employée dans le cloud computing qui consiste à traiter les données à la périphérie du réseau, près de la source des données.
On peut se demander, pourquoi avons-nous besoin de traiter les données près de la source des données ? Prenons un scénario d'urgence simple de voitures autonomes:
Supposons qu'une voiture autonome doit ouvrir la voie à une ambulance venant sur la même voie. Pour ce faire, la voiture doit envoyer ses informations de trafic actuels au cloud et certaines analyses doivent être effectuées en comparant les autres véhicules sur la même piste et la plus proche. Ensuite, l'instruction doit être donnée à la voiture pour qu'elle quitte les voies. Tout doit être exécuté en une fraction de seconde. Mais c'est assez difficile avec une infrastructure cloud située à des kilomètres des appareils d'où proviennent les données. Cela nous amène au concept d'Edge Computing.
Alors, qu'est-ce que l'Edge Computing ? Il s'agit de pousser l'intelligence à la périphérie du réseau. Cela signifie qu'il faut rapprocher les capacités de calcul, de stockage, d'analyse (+ mise en cache) des appareils eux-mêmes. Comment pourrions-nous réaliser cet exploit ? En introduisant des couches réseau (systèmes de périphérie) entre les appareils et les centres de données cloud. Par conséquent, les données n'ont pas besoin de voyager jusqu'au cloud pour être traitées, mais les systèmes de périphérie feraient le nécessaire.
Ce que nous gagnons de cette approche, c'est d'abord une latence ultra-faible car les systèmes de périphérie seront situés au plus près des appareils. Deuxièmement, le filtrage et la réduction des données: cela signifie que toutes les données ne sont pas envoyées vers le cloud, réduisant ainsi le stress sur les besoins en bande passante. Troisièmement, les conformités de sécurité et de confidentialité des données peuvent être satisfaites car elles ne sont pas envoyées entièrement vers le cloud.
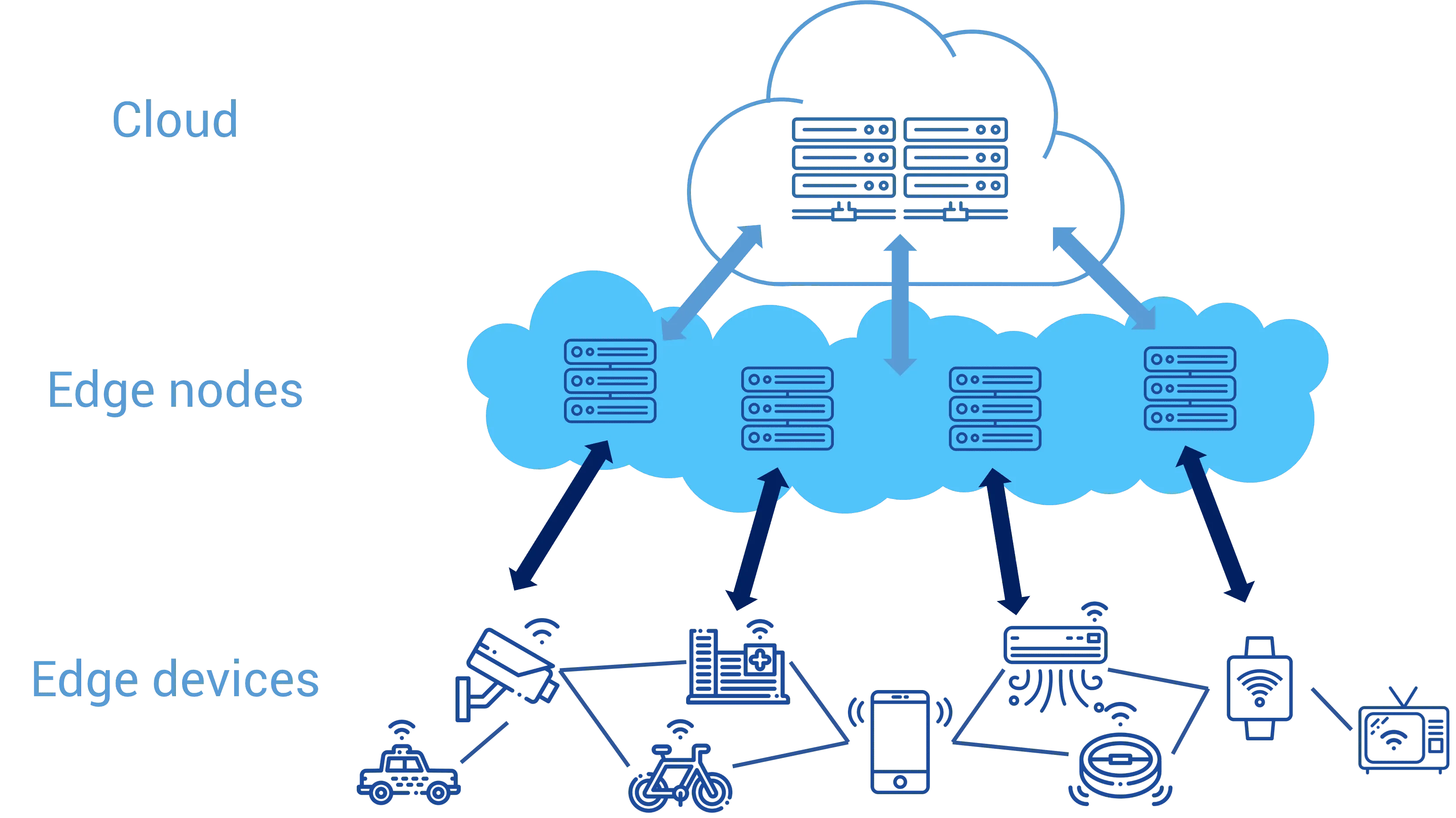
Fonctionnement de KubeEdge
Cependant, il n'est pas si simple d'exécuter Kubernetes directement sur les serveurs Edge en raison de la nature de ses ressources de calcul limitées. Même si ces serveurs nous permettent d'installer tous les composants Kubernetes, les clients peuvent ne pas vouloir dépenser les précieuses ressources de calcul pour gérer le plan de contrôle Kubernetes.
Il apparaît donc le besoin d'une version compacte/optimisée de Kubernetes, qui est KubeEdge. KubeEdge est un système open source permettant d'étendre les capacités d'orchestration d'applications conteneurisées natives aux hôtes d'Edge et il est de nature légère en supprimant un tas de fonctionnalités des binaires Kubernetes.
Après la présentation de tous ces outils, Katie nous a fait une démonstration de l'outil GitOps ArgoCD et Fluxcd qui se sont basés sur Git comme source de configuration en déployant une image nginx sur un serveur Edge à l'aide KubeEdge.
Conclusion
Personnellement, l'idée globale de présenter ces outils de la CNCF façon commerciale est très noble et cela m'a permis de découvrir des nouveaux termes et de nouvelles technologies, mais je ne vois pas réellement le gain que peuvent m'apporter ces outils dans le cadre de mon activité professionnelle. Par exemple, pour créer nos clusters Kubernetes nous utilisons déjà Terraform qui fonctionne parfaitement sur les différents cloud providers connus.
Concernant la partie GitOps, nous avons déjà mis en place plusieurs pipelines Gitlab qui automatisent les différentes phases de build, tests, déploiement et configuration dans k8s pour nos différents environnements. Il faut cependant garder à l'esprit qu'au moment où je rédige cet article, j'ai eu très peu l'occasion de manipuler ces outils, je n'ai donc pas assez de maturité technique pour voir réellement leur intérêt dans mes taches professionnelles.
Conférence: Cloud Cost, Separating Myth From Reality
Le prochain sujet cloud concerne les coûts dans le cloud présenté par Chabane Refes. L'objectif de cette conférence est de nous faire découvrir comment gérer et optimiser ces coûts grâce à différentes stratégies d’optimisation et comment adopter les bons comportements lors des développements.
Il explique qu'AWS a lui-même admis dès 2017 qu'environ 35% des dépenses dans le cloud étaient du gaspillage. Les fournisseurs de cloud public ne s'en plaignent probablement pas, mais les budgets d'ingénierie et d'entreprise le sont certainement.
Il rajoute que la réalité est que les factures du cloud explosent et tout le monde veut les faire baisser. Il y a des histoires d'horreur de startups qui se sont retrouvées à court d'argent parce qu'elles ont commis une petite erreur qui s'est soldée par un énorme dépassement de coûts. Obtenir de la visibilité sur les dépenses liées au cloud et savoir comment les gérer et les optimiser devient un problème de plus en plus important. Voici donc ci-dessous quelques best practices évoquées par le présentateur
Redimensionner selon vos besoins
L'un des principaux avantages du cloud computing est sa capacité à scale vers le haut ou vers le bas selon les besoins de l'entreprise. Achetez simplement ce dont vous avez besoin, puis approvisionnez-en davantage lorsque les choses changent. Cela vous évite de dépenser des capitaux à l'avance pour acheter la capacité dont vous n'aurez peut-être pas besoin à l'avenir.
Planifier votre travail et vos charges de travail
Vous pouvez configurer des planifications pour démarrer et s'arrêter en fonction des charges de travail et des heures de travail. Si personne n'utilise les ressources, il n'y a aucune raison de les garder actives et de les payer.
Examiner votre utilisation et utilisation d'analyses
Le tableau de bord et les analyses de votre fournisseur de cloud computing peuvent fournir un point de départ pour optimiser vos coûts. Recherchez des signes évidents de sous-utilisation. Vous pouvez également utiliser une plate-forme de gestion cloud (Cloud Management Platform "CMP") pour examiner une modélisation détaillée des coûts afin d'obtenir des rapports plus granulaires.
Il explique également que réduire vos coûts prend néanmoins du temps à faire soi-même, et vous pouvez toujours vous faciliter la tâche avec les bons outils comme EMBOTICS, MORPHEUS, FLEXERA et SCALR.
Suppression des éléments obsolètes et inutilisés
Le centre de données cloud de votre entreprise contient probablement aussi beaucoup de données et services inutiles. Étant donné que vous payez pour la capacité, vous devez en faire un processus régulier pour réduire ou déprécier vos données/services lorsqu'elles deviennent obsolètes. Cependant, soyez prudent si vous supprimez des éléments car ils pourraient ne pas être récupérables à une date ultérieure.
Conclusion
Personnellement, je m'étais déjà beaucoup intéressé auparavant à l'optimisation des coûts dans cloud, je n'ai pas donc pas appris grand-chose sur ce sujet qui était plutôt destiné aux débutants. Cependant rien n'est à jeter, je ne savais pas forcément qu'il existait des outils CMP pour optimiser nos coûts dans cloud car des outils d'analyses sont déjàs fournis par les cloud providers, à voir donc s'ils offrent un réel intérêt.
Conférence: From billions to hundreds - How machine learning helps experts detect sensible data leaks
Premier sujet non DevOps ou Cloud que j'ai choisi par simple curiosité. Il est présenté par Giulia Bianchi senior data scientist chez CybelAngel. CybelAngel analyse internet à la recherche de fuites de données parmi les milliers de milliards de documents disponibles sur le web. et comme le titre de la conférence l'indique, ils ont utilisé le Machine Learning pour deux objectifs principaux:
- Le premier objectif est de détecter automatiquement la gravité potentielle d'une fuite de documents sur un serveur ouvert, en fonction de métadonnées telles que les chemins de fichiers. Leurs algorithmes d'apprentissage automatique, entraînés sur des ensembles de données massives et réelles, déterminent la probabilité que le serveur soit critique. Si cette probabilité est supérieure à un certain seuil, le serveur est transmis à des experts en cybersécurité pour analyse.
- Le deuxième objectif du Machine Learning est de détecter le contenu pertinent à l'intérieur des documents. Il analyse le contexte sémantique autour des mots-clés correspondants pour s'assurer que les informations concernent véritablement leurs clients.
Elle explique que tout l'intérêt du Machine Learning est de transformer des milliers de correspondances en des dizaines d'alertes avant qu'elles ne puissent être transmises aux cyber-analystes pour une enquête plus approfondie. Pour ce faire, ils utilisent des modèles de Machine Learning tels que Content Scoring qui consiste à examiner le contenu des documents détectés sur des serveurs de fichiers ouverts pour décider s'ils constituent une menace réelle. Si tel est le cas, il attribue un score à l'alerte. Par ailleurs ce système se compose de :
- Un classificateur: vise à lire le contenu de l'alerte comme le ferait un humain. Il prédit la criticité d'une détection en fonction de ce qu'il trouve dans les fichiers. Le classificateur note la détection de 1 à 100.
- Un seuil: utilisé pour prendre des décisions en fonction du score généré par le classificateur.
Le sujet était super intéressant, malheureusement je manquais de base technique sur le Machine Learning pour réussir à comprendre toute la technicité qui entoure cette technologie, mais cela m'a vraiment donné envie d'approfondir ce sujet d'actualité.
Codelab: GitOps , une mise en situation un peu réaliste sur Kubernetes avec FluxCD
Premier atelier pratique de cette journée, il est supervisé par Laurent Grangeau qui est Cloud Solution Architect chez Sogeti et Ludovic Piot qui est DevOps et Cloud architect indépendant.
Dans ce codelab, ils nous présentent un TP à réaliser où il faut imaginer deux équipes qui collaborent entre elles au quotidien dans un workflow GitOps qui s’appuie sur du Kubernetes et FluxCD. Avec une première team de dev, qui déploie/update/rollback des WebApps Pokémon dans un cluster Kubernetes via des charts Helm et une seconde dev team utilisera Kustomize, pour le même usage.
Et nous en tant qu'Ops, on s'est préoccupé des enjeux de sécurité de la plateforme, soit de la ségrégation des droits des équipes, des flux réseau des applications et des patchs management sur la stack technique.
Vous pouvez retrouver l'intégralité du TP sur le lien suivant: https://github.com/one-kubernetes/workshop. Pour ma part, j'ai trouvé le workshop très instructif et j'ai pour la première fois manipulé un outil GitOps (FluxCD) mais par manque de temps nous n'avons pas pu voir tout ce qu'ils prévoyaient de nous montrer tel que la partie découverte d'Azure DevOps.
Conclusion
Est ce que cela en valait-il la peine ? La réponse est oui ! Et cela pour plusieurs raisons :
Premièrement, les conférences nous offrent une façon différente de découvrir et explorer de nouvelles technologies, pour ma part j'ai découvert et manipulé pour la première fois des outils GitOps.
Ensuite, vous avez la chance de rencontrer de nouveaux technophiles travaillant sur différentes technologies ainsi que les personnes que vous suivez peut-être sur les réseaux sociaux. C'est toujours amusant de rencontrer et de parler avec des personnes ayant le même intérêt ou la même profession que la vôtre. Cela vous inspire non seulement ou augmente votre réseau, mais vous donne également la chance de connaître leur parcours, leur travail et leurs expériences d'apprentissage.
Pour ceux qui recherchent un emploi, des représentants d'assistent à cette conférence. Vous pouvez avoir la possibilité de vous connecter directement avec eux, de discuter de projets, de culture de travail, d'opportunités dans leur entreprise et si cela vous intéresse, vous pouvez poser directement votre CV.
Enfin et surtout, la nourriture est délicieuse et gratuite ! Par ailleurs, je vous partage ci-dessous quelques photos de l'événement :





Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
15 commentaires
Le focus sur l'architecture de la simulation 160K joueurs est super instructif.
Ça donne envie d'aller au prochain DevFest merci pour le partage d'expérience.
La suppression des éléments obsolètes et inutilisés est un classique pourtant on oublie toujours.
Cool de voir un retour sur Cluster API c'est un outil qu'on explore.
La partie sur KubeEdge c'est la première fois que j'en entends parler bien joué.
L'approche Planifier votre travail pour les coûts cloud est quelque chose qu'on doit implémenter plus sérieusement.
Ça valide nos intuitions sur les gains potentiels.
From billions to hundreds - How machine learning helps experts detect sensible data leaks intéressant comme sujet.
Super résumé sur C'est quoi GitOps clair et concis.
Merci pour le débrief ça aide à voir ce qu'on a raté et ce qu'il faut suivre.
Le speaker sur Redimensionner selon vos besoins a visé juste c'est un point clé.
Votre avis sur l'Organisation du DevFest est top ça donne une idée de l'ambiance.
Le Codelab GitOps avec FluxCD j'ai dû le louper sur place votre résumé me donne envie de tester.
Cloud Cost Separating Myth From Reality ça c'est le genre de talk qui nous parle.
On est constamment en train de monitorer nos dépenses c'est utile.
GitOps to the Edge et Infrastructure Provisioning c'est le futur content de voir ça couvert.
Le compte rendu sur Simuler 160K joueurs avec Cloud Run est passionnant.