Le Platform Engineering est-il en train de vivre sa dernière décennie ?
C'est une question qui agite les couloirs virtuels de nos discussions techniques. Hier encore, construire une Plateforme de Développement Interne (IDP) relevait de l'artisanat de haute volée, un assemblage méticuleux de scripts, de configurations YAML et d'outils open-source. Mais une nouvelle force est entrée en jeu, une intelligence capable non plus seulement d'exécuter, mais de raisonner, de générer et d'optimiser.
Cette force, c'est l'Intelligence Artificielle Générative, ou GenAI. Elle ne vient pas remplacer le Platform Engineer, mais plutôt augmenter ses capacités de manière exponentielle. Nous passons d'une ère où nous construisions des autoroutes à une ère où nous concevons des véhicules autonomes qui choisissent le meilleur itinéraire en temps réel.
L'objectif de cet article n'est pas de te vendre un futur hypothétique, mais de te montrer comment, aujourd'hui, ces technologies redéfinissent concrètement les piliers de notre métier, à commencer par le cœur du réacteur : nos pipelines CI/CD.
La GenAI au Cœur de la Plateforme Interne
Du Pipeline Statique au Flux de Travail Cognitif
Tu connais par cœur la musique des pipelines de CI/CD (Intégration Continue et Déploiement Continu). Il s'agit de cet enchaînement d'étapes, souvent décrites dans un fichier .gitlab-ci.yml ou un Jenkinsfile, qui prend le code d'un développeur pour le transformer en une application fonctionnelle en production. C'était, jusqu'à présent, une séquence largement déterministe.
Pourtant, la GenAI transforme ce script rigide en un processus dynamique et contextuel. Imagine un pipeline qui, au lieu de bêtement exécuter une suite de tests, analyse le code modifié et sélectionne intelligemment le sous-ensemble de tests le plus pertinent. Non seulement cela accélère la boucle de feedback pour les développeurs, mais cela optimise aussi drastiquement l'utilisation des ressources de calcul.
L'approche cognitive
L'idée n'est plus de dire "fais A, puis B, puis C", mais plutôt "voici un changement, analyse son impact et détermine la meilleure séquence d'actions pour le valider et le déployer en toute sécurité". L'IA devient le chef d'orchestre, pas seulement le musicien.
Concrètement, ton fichier de pipeline pourrait ressembler à une déclaration d'intention plutôt qu'à une liste de commandes impératives. L'IA interprète l'objectif et génère les étapes à la volée, en s'adaptant à la nature du code, à la charge actuelle sur l'infrastructure ou même aux résultats d'analyses de sécurité prédictives.
deploy-app:
stage: deploy
rules:
- if: '$CI_COMMIT_BRANCH == "main"'
intent: |
Déploie le service {{ service.name }} sur l'environnement de production.
Analyse la performance des 5 derniers déploiements.
Si un risque de régression de performance > 15% est détecté,
opte pour une stratégie de déploiement Canary sur 10% du trafic pendant 1 heure.
Sinon, procède à un déploiement Blue/Green standard.
Alerte l'équipe SRE sur Slack en cas d'anomalie.Scaffolding de Services à la Demande
Le Platform Engineering vise à réduire la charge cognitive des développeurs en leur fournissant des outils et des "golden paths" clairs. L'une des tâches les plus répétitives est la création d'un nouveau microservice : il faut initialiser le dépôt, créer la structure de base, ajouter le Dockerfile, le manifeste Kubernetes, le pipeline CI/CD initial, et la configuration pour l'observabilité.
Avec la GenAI, ce processus de "scaffolding" (ou échafaudage) devient conversationnel. Le développeur n'a plus besoin de cloner un template et de remplacer des valeurs. Il peut simplement exprimer son besoin via une interface en ligne de commande ou une UI.
L'IA dialogue avec lui pour affiner le besoin, puis génère l'ensemble des fichiers de configuration, déjà contextualisés et respectant les standards de l'entreprise. Cela garantit une homogénéité et une qualité incroyables à l'échelle, tout en offrant une expérience développeur d'une fluidité inédite.
Imagine une simple commande qui déclenche un processus de création complet et intelligent.
platform-cli gen service --name=user-profile-api --lang=go --db=postgres --observability=fullRésultat:
Service 'user-profile-api' généré avec succès.
Fichiers créés :
- /services/user-profile-api/go.mod
- /services/user-profile-api/main.go (avec boilerplate de connexion DB)
- /services/user-profile-api/Dockerfile (optimisé pour Go)
- /iac/terraform/modules/services/user-profile-api.tf (ressources cloud)
- /k8s/manifests/user-profile-api/deployment.yaml (avec probes et sidecar OpenTelemetry)
- /ci/pipelines/user-profile-api.yml (pipeline CI/CD initial)
Dépôt Git initialisé et premier commit effectué.L'Impact Pratique sur le Cycle de Vie Applicatif
Observabilité Augmentée et Prédiction d'Incidents
L'Observabilité, ce n'est pas seulement collecter des métriques, des logs et des traces. C'est la capacité de poser des questions sur l'état de ton système sans savoir à l'avance quelles seront ces questions. C'est le pilier qui nous permet de comprendre les comportements complexes et émergents de nos architectures distribuées.
Ici, la GenAI agit comme un détective surpuissant. Elle ingère ces téraoctets de données d'observabilité et ne se contente pas de chercher des erreurs connues. Elle apprend le "bruit de fond" normal de ton application et identifie des corrélations faibles, des signaux avant-coureurs d'un incident qui seraient invisibles à l'œil humain ou à des systèmes d'alerting basés sur des seuils statiques.
Par conséquent, au lieu de recevoir une alerte "CPU à 95%", tu reçois une notification proactive : "Nous observons une augmentation anormale de 10% de la latence sur les requêtes POST vers le service 'paiement', corrélée à une nouvelle 'query' SQL et à une légère hausse des 'GC pauses' de la JVM. Risque d'incident majeur dans les 30 prochaines minutes."
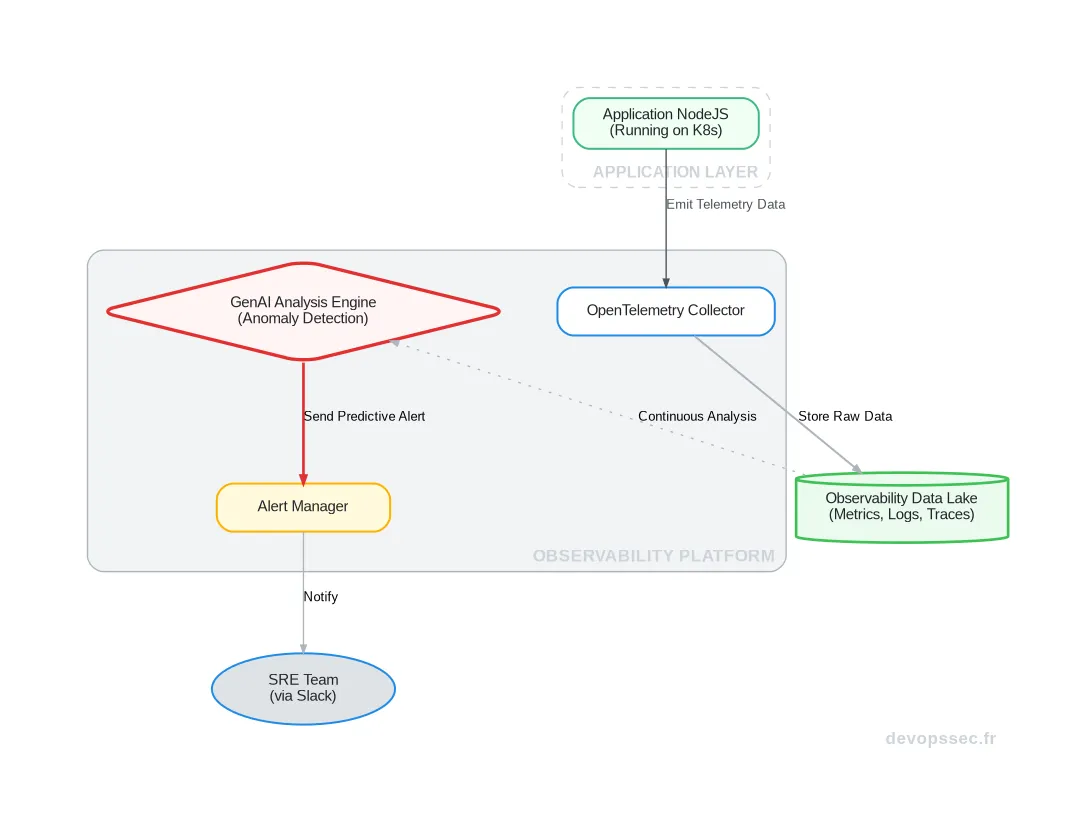
Déploiement Autonome et Self-Healing
Le Graal de tout DevOps est un système qui non seulement se déploie tout seul, mais se répare aussi tout seul. Avec les orchestrateurs comme Kubernetes, nous avons déjà fait un grand pas. Un pod qui tombe ? Kubernetes le redémarre. Mais que se passe-t-il si le problème est plus subtil, comme une nouvelle version qui dégrade les performances pour une catégorie d'utilisateurs ?
C'est là que le déploiement assisté par GenAI brille. Couplée au système d'observabilité augmentée, l'IA peut prendre des décisions de déploiement complexes en temps réel. Elle peut initier un rollback non pas parce qu'un seuil d'erreur est dépassé, mais parce qu'elle a détecté un changement de comportement utilisateur négatif (baisse du taux de conversion, augmentation du temps de validation du panier, etc.).
Cette approche change radicalement la gestion du risque. Le déploiement n'est plus un événement binaire "succès/échec", mais un processus continu d'adaptation et d'optimisation. Le système peut décider de lui-même d'allouer plus de ressources, de revenir à une version précédente pour une partie du trafic, ou même de désactiver une "feature flag" problématique, sans aucune intervention humaine.
| Caractéristique | Déploiement Traditionnel (Automatisé) | Déploiement Assisté par GenAI (Autonome) |
|---|---|---|
| Déclencheur de Rollback | Seuils d'erreurs techniques prédéfinis (ex: taux d'erreur 5xx > 2%). | Analyse multi-factorielle incluant des métriques business et comportementales. |
| Stratégie | Fixe et prédéfinie (ex: toujours Canary). | Adaptative en temps réel (Canary, Blue/Green, etc.) en fonction du risque évalué. |
| Action Corrective | Binaire : Rollback complet vers la version N-1. | Granulaire : Rollback partiel, désactivation de feature flag, ajustement de ressources. |
| Intervention Humaine | Requise pour analyser les causes profondes post-mortem. | Minimale. L'IA fournit une analyse de cause probable en même temps que l'action. |
Vers une Autonomie Assistée: Le Nouveau Rôle du DevOps
Alors, faut-il commencer à rédiger son CV pour une reconversion ? Bien au contraire. Le Platform Engineer ne disparaît pas, il s'élève. Son rôle évolue de celui de constructeur de machineries complexes à celui d'architecte et de superviseur de systèmes intelligents.
Notre quotidien sera moins consacré à écrire des centaines de lignes de YAML et plus à définir des objectifs de haut niveau, à entraîner les modèles d'IA sur le contexte spécifique de notre entreprise, et à valider leurs stratégies. Nous devenons les gardiens de la fiabilité, de la performance et de la sécurité, en enseignant à l'IA les règles du jeu.
Le futur du Platform Engineering est incroyablement excitant. Il demande une curiosité insatiable et la capacité à embrasser le changement. C'est le moment ou jamais de plonger dans ces technologies, non pas comme une menace, mais comme le plus puissant levier de productivité et d'innovation que notre discipline ait jamais connu.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
29 commentaires
Le but final est de ne plus gérer des scripts de déploiement, mais des intentions de déploiement. C'est là que se joue la productivité des prochaines années.
Tu configures des quotas sur ton runner CI. L'IA doit jouer dans les limites du budget infrastructure que tu lui définis, sinon elle est bridée.
Et si l'IA devient trop gourmande en ressources ? Genre elle lance 50 tests en parallèle parce qu'elle pense que c'est nécessaire ?
Il faut exiger une trace de décision. À chaque action, l'IA doit loguer le "pourquoi" : les métriques observées, les seuils dépassés et la logique appliquée.
Perso, le truc qui me fait peur c'est de perdre le contrôle sur ce qui tourne réellement en prod. Comment on débugge une décision prise par une IA ?
C'est la base, après tu rajoutes les couches d'injection de dépendances et de monitoring OpenTelemetry via le prompt initial.
C'est trop simple ça. En prod, il faut gérer les contextes, la config, les logs...
Bien sûr, voici une base générée automatiquement :
On peut voir un exemple de la structure de fichier que l'IA génère pour un service Go ?
Très bon point. La gestion des migrations de base de données doit être découplée du déploiement applicatif. C'est une règle d'or en DevOps, IA ou pas.
Sympa le tableau comparatif. Mais pour le rollback granulaire, tu gères comment avec les bases de données ? Si le code revient en arrière mais pas le schéma, t'es dans le mur.
C'est une surcouche cognitive. Le moteur reste le même, mais la façon dont tu décris le job change radicalement.
Est-ce que ça remplace vraiment les outils de CI actuels ou c'est juste une surcouche ?
Toujours valider avec un
kubectl apply --dry-run=clientavant de pousser. L'IA génère, le CI valide. Jamais confiance aveugle.Quels sont les risques de hallucination dans la génération de manifestes K8s ? Une erreur de syntaxe dans un
deployment.yamlet c'est le crash assuré.Si tu as 2 microservices, oui, c'est du sur-ingéniering. Si tu en as 200 et que ton équipe est sous l'eau, c'est la seule façon de passer à l'échelle sans recruter 10 personnes de plus.
Ça semble être un sacré investissement en temps pour configurer l'IA par rapport au gain immédiat. On ne risque pas de sur-ingénierer le truc ?
C'est le rôle du catalogue de services. L'IA interroge l'API de ta plateforme pour récupérer les dépendances existantes. Voici comment on structure souvent le template :
Le scaffolding c'est sympa, mais est-ce que ça gère les dépendances complexes entre services ? Genre si le service A a besoin d'une config spécifique dans le service B ?
C'est pour ça qu'on commence par du "human-in-the-loop". L'IA propose le rollback, tu valides en un clic. Une fois que t'as assez de confiance dans tes métriques, tu passes en mode full auto sur des services non critiques.
Le rollback autonome c'est le rêve, mais en vrai, qui va oser laisser une machine décider de couper le trafic en prod ? Les clients vont hurler si ça fait un faux positif.
Tu peux coupler Prometheus pour les métriques et une couche d'analyse LLM sur les logs structurés via un pipeline ELK ou Loki. L'idée est de nourrir le modèle avec tes données historiques :
Intéressant. Tu parles d'observabilité augmentée pour détecter des régressions business. T'as un exemple de stack concrète pour mettre ça en place sans réinventer la roue ?
L'IA doit être intégrée dans une chaîne de validation type
policy-as-code. Tu ne laisses pas l'IA déployer en aveugle. Le pipeline doit passer par des outils comme OPA ou Kyverno pour valider que ce que l'IA a pondu respecte tes standards de sécurité.Et côté sécu, on fait comment ? Si l'IA génère des configs, elle peut aussi introduire des failles à ne jamais laisser passer en prod. Qui audite le code généré ?