Et si nos infrastructures pouvaient enfin penser par elles-mêmes ?
Nous avons passé des années à perfectionner l'automatisation, à scripter chaque action possible et à construire des pipelines CI/CD robustes pour éliminer l'erreur humaine. Pourtant, nous restons fondamentalement dans une posture réactive. Une alerte se déclenche, un script s'exécute. Et si la prochaine évolution consistait à créer des systèmes qui non seulement réagissent, mais anticipent, raisonnent et s'adaptent de manière autonome ?
Bienvenue dans l'ère des Architectures Cognitives, une fusion fascinante entre l'intelligence artificielle et l'ingénierie des systèmes distribués. Il ne s'agit plus de simples "if/then/else" dans un script de déploiement, mais de doter nos applications et nos plateformes d'une capacité de jugement, leur permettant de s'auto-optimiser en temps réel face à des conditions imprévues.
Cette approche change radicalement notre rôle. Nous ne sommes plus seulement des opérateurs ou des développeurs, mais des mentors pour des systèmes intelligents, leur apprenant les règles du jeu pour qu'ils puissent ensuite jouer la partie de manière autonome et bien plus efficacement que nous ne pourrions jamais le faire manuellement.
Dépasser la simple automatisation : la naissance du système qui apprend
Pendant longtemps, le DevOps a été synonyme d'automatisation. On automatise les tests, les builds, les déploiements, et même la création d'infrastructure avec des outils comme Terraform. C'est une base essentielle, mais elle atteint ses limites. L'automatisation classique suit des règles prédéfinies, elle ne peut pas gérer l'inconnu ou prendre une décision stratégique face à une nouvelle menace de sécurité ou un pic de trafic atypique.
L'architecture cognitive, elle, intègre une couche de raisonnement. Elle observe l'état du système dans sa globalité, le compare aux objectifs métiers (performance, coût, sécurité) et décide de l'action la plus pertinente sans suivre un chemin prédéfini. C'est la différence entre un régulateur de vitesse et une voiture entièrement autonome.
| Aspect | Approche DevOps Traditionnelle | Approche Cognitive |
|---|---|---|
| Détection d'Anomalies | Seuils statiques (CPU > 90%) | Analyse prédictive des tendances et comportements |
| Scalabilité | Réactive (scaling basé sur la charge actuelle) | Proactive (scaling anticipé basé sur des modèles prédictifs) |
| Gestion d'Incidents | Runbooks et intervention humaine | Auto-réparation (self-healing) et réorganisation autonome |
| Optimisation des Coûts | Manuelle, basée sur des rapports mensuels | Ajustement dynamique des ressources en temps réel |
Les Piliers Techniques de l'Infrastructure Intelligente
Construire une architecture cognitive ne se fait pas par magie. Cela repose sur la combinaison de plusieurs concepts avancés qui, ensemble, créent une boucle de rétroaction intelligente. C'est un peu comme assembler le système nerveux, le cerveau et les muscles d'un organisme vivant.
L'Observabilité Prédictive : Voir l'avenir dans les métriques
Nous connaissons tous l'observabilité, cette capacité à comprendre l'état interne d'un système à partir de ses signaux externes comme les logs, les métriques et les traces. C'est le système nerveux de notre infrastructure. Il collecte des informations brutes sur ce qui se passe à un instant T.
L'Observabilité Prédictive va beaucoup plus loin. Au lieu de simplement afficher des dashboards, elle utilise des modèles de machine learning pour analyser les flux de données en temps réel et prédire les états futurs. Elle ne se contente pas de dire "le CPU est à 80%", mais plutôt "au vu des tendances des dernières heures et du comportement des microservices dépendants, il y a 95% de chances que ce service sature dans les 15 prochaines minutes".
Cette vision prédictive est la clé. Elle transforme notre posture de réactive à proactive, nous donnant le temps d'agir avant même que l'utilisateur final ne soit impacté. C'est le fondement sur lequel repose toute décision cognitive.
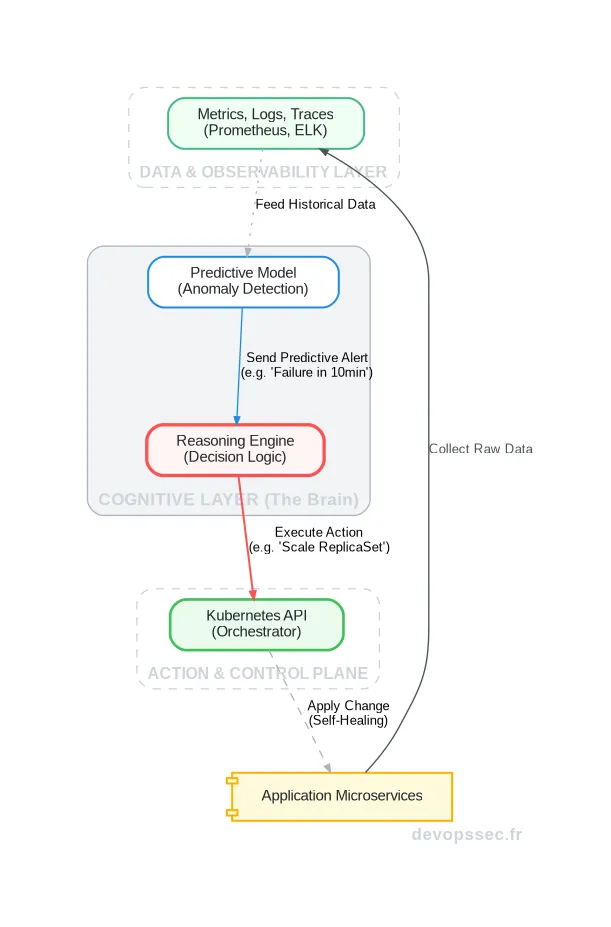
Ce schéma illustre parfaitement la boucle de décision. Les microservices applicatifs génèrent des données brutes, qui sont analysées par un modèle prédictif. Lorsqu'une future anomalie est détectée, une alerte est envoyée au "Reasoning Engine", le cerveau du système, qui décide alors d'une action corrective (comme redimensionner un service) et l'exécute via l'orchestrateur comme Kubernetes.
Le Moteur de Raisonnement (Reasoning Engine)
Si l'observabilité prédictive est le système nerveux, le moteur de raisonnement est le cortex préfrontal. C'est le composant central qui reçoit les prédictions et décide quoi faire. Il ne se contente pas d'appliquer des règles simples, il évalue plusieurs options en fonction d'un contexte plus large.
Par exemple, face à une prédiction de surcharge, il pourrait :
- Augmenter le nombre de réplicas si le budget cloud le permet.
- Activer un "circuit breaker" ou du "load shedding" pour dégrader gracieusement le service si le coût est une contrainte majeure.
- Déclencher une migration de la charge de travail vers une région cloud moins chère ou moins sollicitée.
Ce moteur est souvent configuré via des fichiers de politique, qui décrivent les objectifs et les contraintes plutôt que les actions impératives. On ne lui dit pas "si le CPU > 90%, ajoute 2 pods", mais plutôt "maintiens le temps de réponse en dessous de 200ms tout en ne dépassant pas le budget de 500€/jour".
# Exemple de CognitivePolicy pour un service de paiement
apiVersion: cognitive.io/v1alpha1
kind: CognitivePolicy
metadata:
name: payment-service-resilience
spec:
target:
kind: Deployment
name: payment-svc
goals:
- metric: latency_p99
target: < 250ms
- metric: error_rate
target: < 0.1%
constraints:
- type: budget
limit: 500
currency: EUR
period: daily
actions:
- name: scale_up
priority: 1
cooldown: 5m
- name: enable_graceful_degradation
priority: 2
params:
feature_flag: lightweight-checkout
- name: notify_oncall
priority: 3
channel: PagerDutyLes défis de l'adoption : tout n'est pas si simple
L'idée d'une infrastructure qui se gère toute seule est séduisante, mais le chemin pour y parvenir est complexe et semé d'embûches. L'adoption d'une architecture cognitive n'est pas une simple mise à jour technologique, c'est un changement de paradigme qui comporte des risques.
Premièrement, la complexité est un facteur majeur. Mettre en place et entraîner des modèles de machine learning fiables pour l'Auto-Adaptation demande des compétences très pointues et une quantité massive de données d'observation propres et bien étiquetées. Un modèle mal entraîné pourrait prendre des décisions catastrophiques, comme réduire les ressources en plein pic de trafic.
Commencez petit et de manière isolée
N'essayez pas de rendre toute votre plateforme cognitive d'un seul coup. Choisissez un microservice non critique mais bien instrumenté. Mettez en place une boucle cognitive en "shadow mode" : laissez-la prendre des décisions virtuelles et comparez-les aux actions que vos équipes auraient prises. C'est le meilleur moyen d'entraîner et de valider votre modèle sans risquer la production.
Ensuite, il y a la question de la confiance et du contrôle. Laisser une machine prendre des décisions qui impactent la production peut être angoissant. Que se passe-t-il si le système entre dans une boucle de rétroaction positive et scale à l'infini, faisant exploser la facture cloud ? Il est crucial de mettre en place des garde-fous, des limites strictes et des mécanismes d'arrêt d'urgence pour reprendre la main à tout moment.
Conclusion : Notre rôle évolue de bâtisseur à éducateur
Les architectures cognitives ne sont pas là pour remplacer les ingénieurs DevOps. Au contraire, elles élèvent notre rôle. Nous passons moins de temps à éteindre des incendies et plus de temps à concevoir des systèmes résilients et à enseigner à nos plateformes comment réagir intelligemment face aux imprévus.
Notre expertise se déplace de la configuration impérative (kubectl scale deployment --replicas=5) à la définition de politiques et d'objectifs stratégiques. Nous devenons les architectes de systèmes d'apprentissage autonomes, des mentors qui guident l'IA pour qu'elle assure la stabilité et la performance de manière bien plus fine et rapide que n'importe quel humain.
Le voyage vers des systèmes entièrement cognitifs ne fait que commencer, mais une chose est sûre : l'avenir de l'infrastructure n'est pas seulement automatisé, il est intelligent.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
21 commentaires
C'est un point très juste. L'IA doit aussi remonter le contexte de l'erreur.
Le but est l'auto-réparation, mais le post-mortem doit rester humain pour analyser pourquoi le problème est survenu.
J'ai testé des outils de self-healing. La plupart du temps, ils redémarrent des pods en boucle au lieu de chercher la cause racine.
Ça masque les vrais bugs au lieu de les résoudre. C'est dangereux.
Si ton bash est suffisant, garde-le. L'article s'adresse à ceux qui ont atteint les limites du scriptable.
On ne change pas d'archi pour le plaisir, mais par nécessité quand la taille du cluster explose.
L'article oublie le coût humain de la maintenance de ces modèles. Une fois que le gars qui a écrit l'IA se barre, qui débugue les décisions absurdes du moteur ?
Je préfère mon bon vieux bash.
C'est pour ça que les limites strictes sont obligatoires dans la spec.
Si le système dépasse la limite, il s'arrête. C'est une règle de sécurité de base, pas une option.
Le risque financier est trop grand. Une mauvaise config dans le
CognitivePolicyet tu te retrouves avec une facture cloud à 5 chiffres en une nuit.Je ne laisserai jamais une machine gérer mon budget tout seul.
C'est vrai que la base est mathématique. Mais c'est l'agrégation de ces signaux qui permet une décision autonome.
Ce n'est pas parce que c'est simple mathématiquement que l'impact opérationnel n'est pas majeur.
Trop de buzzwords. Observabilité prédictive c'est juste de la régression linéaire ou des moyennes mobiles sur des métriques PromQL.
Arrêtez de vouloir vendre ça comme du raisonnement.
Le concept de shadow mode est le seul truc qui sauve cet article. Sans ça, c'est la recette pour un crash en prod.
Mais franchement, qui a le temps de maintenir une infra en mode shadow ?
C'est pour ça qu'il faut toujours un mode manuel ou une override prioritaire.
L'IA propose, l'humain dispose si besoin.
Et si le modèle se trompe ? Comment tu fais un
kubectl rollout undosur une décision d'IA ?Ça devient une boîte noire impossible à débugger à 3h du matin.
Je comprends le scepticisme. Mais regardez les logs de vos incidents : 80% sont des trucs répétitifs que l'IA pourrait gérer.
On ne demande pas de remplacer l'ingénieur, mais de lui libérer du temps pour les vrais problèmes d'architecture.
L'idée de mentors pour systèmes intelligents me fait doucement rire. On a déjà du mal à avoir des doc à jour, alors entraîner un modèle...
C'est le syndrome de l'ingénieur qui veut trop automatiser.
J'ai bossé sur des systèmes de monitoring prédictif. Le problème c'est la qualité des données. Si tes logs sont pourris, ton IA va prendre des décisions basées sur des corrélations fausses.
Tu passes plus de temps à nettoyer tes données qu'à gérer ton infra.
Parce que le déterministe atteint ses limites quand les variables sont trop nombreuses.
Un script ne peut pas prédire une saturation avant qu'elle n'arrive, il réagit à la métrique déjà présente. Le modèle prédictif change la donne.
Le Reasoning Engine, c'est juste un nom pour un contrôleur custom. On fait déjà ça avec des opérateurs Kubernetes.
Pourquoi vouloir complexifier avec de l'IA quand un script Go bien écrit fait le job de manière déterministe ?
La gestion des dépendances est le vrai défi, je ne dis pas le contraire. C'est pour ça que la politique doit être holistique.
C'est un garde-fou simple, mais efficace contre le scaling infini.
D'accord avec le 2. L'article parle de
CognitivePolicy, mais comment tu gères les dépendances entre services ?Si ton moteur de raisonnement décide de dégrader un service, il risque d'impacter toute la chaîne. C'est le meilleur moyen de créer une panne en cascade.
J'ai vu des boîtes essayer de mettre du ML pour le scaling. Ça finit toujours avec un
kubectl get podsqui montre un cluster qui scale en boucle parce que le modèle est mal entraîné.C'est une usine à gaz monumentale pour un problème qu'un simple HPA bien configuré règle dans 99% des cas.
C'est justement pour éviter ces effets de bord que je propose le shadow mode. Tu testes tes politiques sans impacter le trafic réel.
Le but n'est pas de remplacer l'humain, mais de lui donner des outils pour gérer la complexité qu'on ne peut plus traiter à la main.
Encore un article qui vend du rêve avec des mots à la mode. L'Auto-Adaptation c'est juste un nom marketing pour du scaling basé sur des triggers complexes qui vont finir par créer des effets de bord ingérables.
Qui va maintenir le modèle si le système commence à faire n'importe quoi en prod ?