Data Mesh : Plongée au cœur de la révolution des données distribuées
Tu as sans doute remarqué que les architectures de données traditionnelles, comme les Data Lakes centralisés, commencent sérieusement à montrer leurs limites. Les goulots d'étranglement s'accumulent, les équipes métier attendent des semaines pour une nouvelle source de données, et l'agilité promise par le cloud semble s'évaporer dès qu'on touche à la data. Ce n'est pas une fatalité, mais le symptôme d'un paradigme à bout de souffle.
Imagine un instant que chaque équipe de ton entreprise, qu'elle soit au marketing, à la logistique ou à la finance, ne soit plus une simple consommatrice de données, mais devienne la productrice et la propriétaire de ses propres produits de données. C'est précisément la révolution conceptuelle que propose le Data Mesh, une approche socio-technique qui redéfinit radicalement notre rapport à l'information.
Ce n'est pas juste une autre architecture à la mode. C'est une transformation profonde qui place l'autonomie et la responsabilité au cœur des équipes, transformant le rôle du DevOps et du Platform Engineer en facilitateurs d'un écosystème de données distribuées, résilientes et orientées métier.
Déconstruire le monolithe : les fondations du Data Mesh
Pour bien saisir la rupture qu'incarne le Data Mesh, il faut d'abord comprendre les frustrations nées du modèle précédent. Pendant des années, nous avons cherché à tout centraliser dans un unique "lac de données" (Data Lake) ou "entrepôt de données" (Data Warehouse), géré par une seule équipe d'experts. L'idée était séduisante, mais la réalité s'est avérée bien plus complexe.
Cette centralisation a créé une dépendance énorme envers une équipe surchargée, incapable de comprendre intimement les besoins spécifiques de chaque domaine métier. Le résultat ? Des pipelines de données fragiles, des délais interminables et une innovation ralentie. Le Data Mesh prend le contre-pied total de cette approche.
Du goulot d'étranglement à l'écosystème distribué
Le changement de paradigme est radical. Plutôt que de forcer toutes les données à converger vers un point unique, le Data Mesh les traite là où elles naissent et où elles ont le plus de sens : au sein des domaines métier. Chaque domaine (par exemple, "Gestion des stocks", "Profils clients", "Transactions de paiement") devient responsable de ses données de bout en bout.
| Critère | Approche Monolithique (Data Lake) | Approche Distribuée (Data Mesh) |
|---|---|---|
| Propriété des données | Centralisée par une équipe Data dédiée | Décentralisée et détenue par les domaines métier |
| Architecture | Monolithique, pipelines complexes (ETL/ELT) | Distribuée, orientée services et API |
| Goulot d'étranglement | L'équipe centrale Data | La capacité de la plateforme self-service |
| Agilité | Faible, les changements impactent tout le système | Élevée, les domaines évoluent de manière autonome |
Les quatre piliers qui changent la donne
Le Data Mesh ne se résume pas à décentraliser. Il repose sur quatre principes fondamentaux qui, ensemble, créent un système cohérent et scalable. Les ignorer, c'est risquer de créer une anarchie de silos de données.
- Propriété des données par domaine : Les équipes qui connaissent le mieux les données (le métier) en sont responsables. Elles gèrent leur cycle de vie, leur qualité et leur exposition. Finie la perte de contexte lors du transfert à une équipe centrale.
- Data as a Product : Chaque domaine ne se contente pas de "stocker" des données, il les traite comme un produit. Cela implique de penser à ses consommateurs, de fournir une documentation claire, de garantir une qualité de service (SLA) et de proposer des points d'accès faciles (API, streams, etc.).
- Plateforme de données en self-service : Pour que les domaines soient autonomes, ils ont besoin d'outils. Le rôle des équipes techniques centrales (les Platform Engineers) est de fournir une plateforme qui abstrait la complexité de l'infrastructure (stockage, calcul, monitoring, sécurité) pour que les équipes métier puissent créer et gérer leurs produits de données facilement.
- Federated Computational Governance : L'autonomie ne signifie pas le chaos. Un ensemble de règles globales et automatisées, gérées de manière fédérée, assure l'interopérabilité, la sécurité et la conformité de l'ensemble du maillage. On ne centralise plus les données, mais on standardise les règles du jeu.
Le nouveau rôle du DevOps : Bâtisseur de plateformes
Face à cette décentralisation, on pourrait croire que le rôle des équipes techniques diminue. C'est tout le contraire : il devient plus stratégique. Ton quotidien ne consiste plus à exécuter des requêtes pour d'autres équipes, mais à construire l'autoroute sur laquelle leurs produits de données vont circuler en toute sécurité.
C'est ici qu'émerge avec force la discipline du Platform Engineering. L'objectif est de réduire la charge cognitive des équipes de domaine en leur fournissant une "expérience développeur" (DevEx) exceptionnelle pour la data. Tu ne construis plus le produit final, mais la "golden path", le chemin pavé d'or qui guide les équipes vers les bonnes pratiques sans les contraindre de manière rigide.
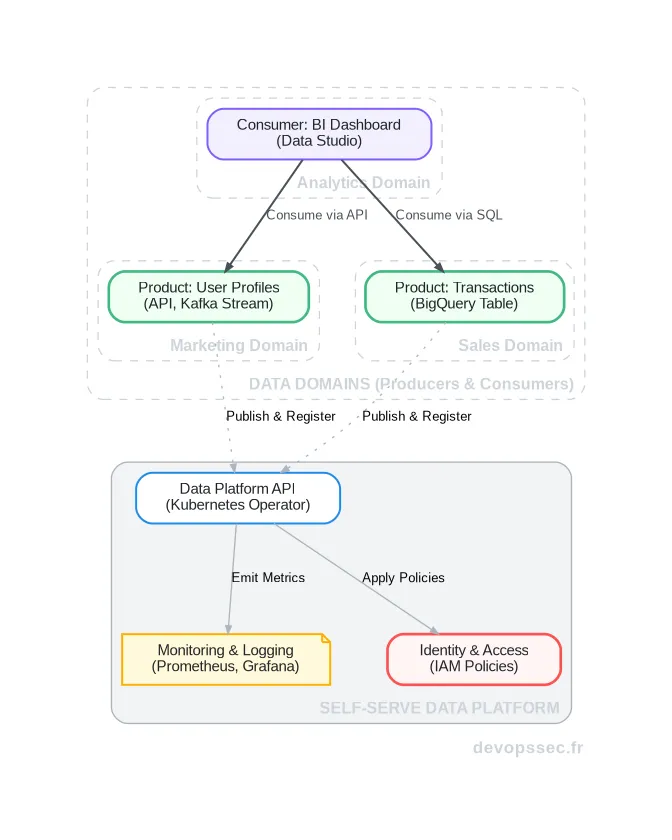
Ce schéma illustre parfaitement le concept. Les domaines "Marketing" et "Ventes" ne se contentent pas de stocker des données. Ils les publient en tant que produits bien définis (une API, un flux Kafka, une table BigQuery). Ils utilisent pour cela les outils fournis par la plateforme centrale, qui gère de manière transversale la sécurité, l'observabilité et le catalogue de données. L'équipe "Analytics" peut alors découvrir et consommer ces produits en self-service, en toute confiance.
Concrétiser le "Data as a Product" avec l'IaC
Parler de "produit" peut sembler abstrait. Concrètement, comment cela se matérialise-t-il ? C'est là que nos compétences en Infrastructure as Code (IaC) entrent en jeu. Un produit de données peut être défini de manière déclarative, par exemple via un Custom Resource Definition (CRD) dans Kubernetes.
Imagine un fichier YAML qui décrit un produit de données. Ce fichier devient le contrat entre le producteur et le consommateur. Il spécifie les points d'accès (les "ports"), le schéma des données, les propriétaires, et les garanties de qualité. L'équipe de la plateforme n'a plus qu'à construire l'opérateur Kubernetes qui interprète ce fichier et provisionne toute l'infrastructure sous-jacente.
Le contrat déclaratif
Ce fichier YAML n'est pas juste de la configuration. C'est un véritable "contrat de données". En le versionnant dans Git et en le déployant via un pipeline de CI/CD, on apporte toute la rigueur du développement logiciel à la gestion des données.
apiVersion: dataproduct.mesh.io/v1alpha1
kind: DataProduct
metadata:
name: user-profiles
namespace: domain-marketing
labels:
owner: "Team Marketing"
spec:
# Description métier du produit
description: "Profils utilisateurs unifiés avec informations de contact et segments."
# Qui est le propriétaire technique et métier
owner:
team: marketing-dev
contact: "marketing-lead@example.com"
# Points d'accès au produit (les "ports")
ports:
- name: kafka-stream-v1
type: stream
format: avro
schema: "gs://schemas/user-profiles/v1.avsc"
endpoint: "kafka-cluster.internal:9092/topics/user-profiles"
- name: bigquery-snapshot-v1
type: table
format: sql
endpoint: "gcp-project.bq_dataset.user_profiles_daily"
# Contrat de qualité de service
sla:
freshness: "24h"
availability: "99.9%"Les limites à ne pas ignorer
Le Data Mesh n'est pas une solution miracle. Mettre en œuvre une telle architecture représente un investissement technique et organisationnel colossal. L'autonomie accordée aux domaines peut rapidement se transformer en chaos si la gouvernance fédérée n'est pas suffisamment robuste et automatisée dès le départ.
De plus, la charge cognitive sur les équipes de domaine augmente. Elles doivent non seulement être expertes de leur métier, mais aussi acquérir des compétences en ingénierie des données et en gestion de produit. La plateforme doit donc être exceptionnellement simple et intuitive pour éviter de les submerger. La complexité ne disparaît pas, elle est déplacée et doit être gérée intelligemment.
Le Data Mesh, bien plus qu'une architecture
En définitive, il est crucial de comprendre que le Data Mesh est avant tout un changement de paradigme socio-technique. Adopter cette approche, ce n'est pas seulement déployer de nouveaux outils, c'est réorganiser l'entreprise autour de la valeur des données, en donnant aux équipes métier les moyens de leur autonomie.
Pour nous, professionnels du DevOps et du Platform Engineering, c'est une opportunité unique de passer d'un rôle de support à celui de partenaire stratégique. Notre mission devient de concevoir et de maintenir des plateformes de données qui accélèrent l'innovation à grande échelle. Le défi est immense, mais la récompense, une organisation véritablement "data-driven", l'est tout autant.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
19 commentaires
C'est pour ça que la plateforme doit être self-service. Si tu ne fournis pas les abstractions, les équipes vont échouer. Le succès dépend de la qualité de tes outils internes.
Je reste sceptique. La plupart des entreprises ne sont même pas capables de gérer un
docker-compose.ymlpropre, alors leur demander de maintenir une mesh distribuée...C'est surtout une responsabilisation. Le développeur qui crée la donnée est celui qui sait le mieux ce qu'elle contient. Lui donner les moyens de la publier proprement, c'est ça le progrès.
Le Data Mesh, c'est juste une excuse pour ne pas embaucher de Data Engineers compétents et forcer les développeurs à faire leur boulot de nettoyage de données. C'est du transfert de dette technique.
Versioning strict des API et des schémas. Si tu casses un contrat, ton pipeline de build doit échouer. C'est la base du développement logiciel appliqué à la donnée.
L'idée du
DataProductcomme contrat est séduisante, mais dans la vraie vie, les schémas changent tout le temps. Comment tu gères les ruptures de compatibilité sans tout casser en aval ?La complexité existe, elle est juste déplacée. Mieux vaut qu'elle soit dans un pipeline CI/CD automatisé que dans les tickets Jira d'une équipe data centrale saturée.
J'ai bossé dans une boîte qui a tenté ça. On a passé 6 mois à débugger des pipelines CI/CD parce que le YAML était mal versionné. Ne jamais sous-estimer la complexité du déploiement.
Ça demande une équipe plateforme énorme pour maintenir tous ces opérateurs. Au final, tu crées un nouveau goulot d'étranglement : l'équipe qui maintient la plateforme.
La sécurité doit être by design dans l'opérateur. Quand tu définis ton
DataProduct, l'opérateur crée automatiquement les politiques d'accès. C'est ça, la puissance du Platform Engineering.Exactement. La sécurité est toujours le parent pauvre de ces architectures "décentralisées". À la fin, t'as des données sensibles qui traînent dans des buckets S3 sans protection parce que "c'est au domaine de gérer".
Ton exemple de CRD est mignon, mais en prod, gérer la rétention des données et les accès IAM sur 50 domaines différents, c'est un enfer. T'as prévu quoi pour le
RoleBindingdynamique ?La gouvernance fédérée est là pour éviter ça. Si tu laisses les équipes choisir leur stack, t'as pas fait du Data Mesh, t'as fait de l'anarchie. Il faut imposer des standards de sortie via la plateforme.
On a testé ce genre de structure. Le résultat ? Chaque équipe a fini par réinventer sa propre stack de monitoring parce que la plateforme centrale ne couvrait pas leurs besoins spécifiques. Résultat : 10 outils de logs différents.
C'est là que le Platform Engineering intervient. On ne leur demande pas de configurer Kafka, on leur donne une interface qui génère le YAML. Le
DataProductest le contrat, pas l'implémentation.Le problème c'est pas l'outil, c'est l'humain. Tu demandes à des équipes marketing de gérer des streams Kafka ? Ils savent à peine faire un
git commitsans conflit. C'est une utopie managériale.L'opérateur ne fait que valider le contrat. Si le schéma ne passe pas le CI, le déploiement est bloqué. C'est justement le but d'utiliser
kubectl applyavec une validation poussée en amont.Le coup du
DataProductdans un CRD Kubernetes, c'est joli sur le papier, mais t'as géré comment la montée en charge sur le catalogue central ? Quand les domaines commencent à pousser des schémas qui cassent tout, ton opérateur il implose.Encore une énième couche d'abstraction pour masquer le fait que personne ne veut vraiment gérer la qualité des données. Déjà vu avec les microservices, ça finit toujours en spaghetti distribué.