Zero Trust DevOps : L'Ère de la Confiance Zéro en Cloud Natif
Vous avez déployé vos microservices sur Kubernetes, votre pipeline CI/CD tourne à plein régime, et pourtant, une question insidieuse demeure : votre forteresse applicative est-elle vraiment sécurisée ? Les approches traditionnelles, basées sur un périmètre réseau bien gardé, s'effondrent face à la nature distribuée et éphémère des infrastructures cloud natives. Il est temps de changer de paradigme.
L'idée n'est plus de construire des murs plus hauts, mais de considérer que l'ennemi est déjà à l'intérieur. C'est l'essence même de l'architecture Zero Trust, une philosophie qui part du principe qu'aucune requête, aucun utilisateur et aucun service n'est digne de confiance par défaut, qu'il soit à l'intérieur ou à l'extérieur du réseau.
Déconstruire le Mythe : Qu'est-ce que le Zero Trust Vraiment ?
Oubliez l'idée d'un produit miracle à acheter sur étagère. Le Zero Trust n'est pas un outil, mais un modèle stratégique de cybersécurité qui redéfinit la manière dont nous concevons l'accès et l'authentification. Le mantra est simple mais puissant : "Ne jamais faire confiance, toujours vérifier".
Concrètement, cela signifie que chaque demande d'accès à une ressource est traitée comme si elle provenait d'un réseau non contrôlé. Avant d'accorder l'accès, on vérifie systématiquement l'identité de l'utilisateur ou du service, l'état de santé de son appareil, et on s'assure qu'il ne demande que le minimum de privilèges nécessaires pour accomplir sa tâche.
Les Piliers Fondamentaux de la Confiance Zéro
Pour mettre en œuvre cette philosophie, nous nous appuyons sur des principes directeurs clairs qui guident nos choix d'architecture et d'outillage. Ils forment le socle sur lequel repose toute la stratégie de sécurité de nos systèmes distribués.
Ces piliers transforment une confiance implicite basée sur la localisation réseau en une confiance explicite et dynamique, continuellement réévaluée.
- Vérification Explicite : Authentifier et autoriser en permanence en se basant sur tous les points de données disponibles, y compris l'identité, la localisation, la santé de l'appareil, le service, la classification des données et les anomalies.
- Accès au Moindre Privilège (Least Privilege) : Limiter l'accès des utilisateurs et des services avec des politiques juste-à-temps et juste-assez (JIT/JEA), combinées à une protection adaptative des données pour sécuriser à la fois les données et la productivité.
- Présomption de Compromission (Assume Breach) : Minimiser le rayon d'action des attaquants en segmentant l'accès par réseau, utilisateur, appareil et application. Chiffrer toutes les sessions de bout en bout et utiliser l'analytique pour obtenir une visibilité et détecter les menaces.
Du Périmètre au Micro-Périmètre
Le changement le plus radical est l'abandon du modèle de la "forteresse". Autrefois, on sécurisait le périmètre externe, et tout ce qui était à l'intérieur était considéré comme sûr. Aujourd'hui, avec les microservices qui communiquent entre eux, le périmètre est partout et nulle part à la fois.
Le Zero Trust introduit le concept de micro-segmentation. Chaque service, voire chaque instance d'un service, devient son propre micro-périmètre sécurisé, avec des politiques d'accès strictes qui contrôlent précisément qui peut lui parler et comment.
| Approche Traditionnelle (Castle-and-Moat) | Approche Zero Trust |
|---|---|
| Confiance basée sur la localisation réseau (interne vs externe). | Confiance basée sur l'identité vérifiée de chaque requête. |
| Périmètre réseau large et statique. | Micro-périmètres dynamiques et granulaires autour des ressources. |
| Accès réseau large une fois à l'intérieur. | Accès au moindre privilège, spécifique à la ressource demandée. |
| Sécurité concentrée sur la prévention des intrusions. | Sécurité axée sur la détection rapide et la limitation de l'impact d'une brèche. |
Mise en Pratique : Le Zero Trust dans votre Pipeline CI/CD
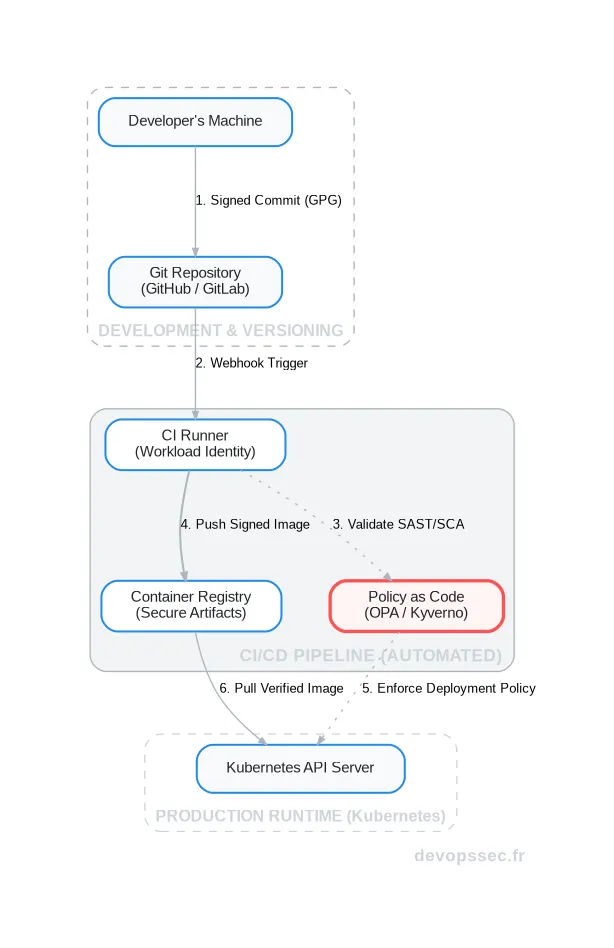
La théorie est une chose, mais comment intégrer concrètement ces principes dans nos pipelines d'intégration et de déploiement continus (CI/CD) ? C'est ici que le DevOps prend tout son sens, en automatisant la sécurité à chaque étape du cycle de vie de l'application.
Un pipeline CI/CD Zero Trust n'est plus une simple chaîne d'assemblage c'est une série de sas de sécurité où chaque étape doit prouver son identité et son intégrité avant de pouvoir passer à la suivante. La confiance n'est jamais héritée, elle est regagnée à chaque transition.
L'Identité comme Nouveau Périmètre : SPIFFE et SPIRE
Dans un environnement Kubernetes où les pods sont créés et détruits en quelques secondes, s'appuyer sur des adresses IP pour l'identification est une cause perdue. Le véritable périmètre de sécurité devient l'identité de la charge de travail (workload) elle-même.
C'est là qu'intervient le standard SPIFFE (Secure Production Identity Framework for Everyone). Il fournit une spécification pour un framework d'identité universel capable d'identifier de manière cryptographique et sécurisée chaque service applicatif. SPIRE est son implémentation de référence, un agent qui s'exécute sur chaque nœud et qui délivre automatiquement des documents d'identité (appelés SVIDs) aux workloads.
Grâce à SPIFFE, un service "paiement" peut prouver de manière irréfutable à un service "facturation" qu'il est bien qui il prétend être, sans se soucier de l'IP, du nœud ou du namespace sur lequel il s'exécute. Cette authentification forte est la base de la communication sécurisée inter-services (mTLS).
De l'IP à l'Identité
Passer d'un modèle de sécurité basé sur l'IP à un modèle basé sur l'identité cryptographique est le changement le plus fondamental et le plus puissant qu'apporte le Zero Trust dans un contexte Cloud Natif. C'est ce qui permet une sécurité dynamique et portable.
Politiques de Sécurité en tant que Code
La vérification continue ne peut pas être manuelle. Pour passer à l'échelle, les politiques de sécurité doivent être définies, versionnées et appliquées de manière automatisée, comme n'importe quel autre morceau de code. C'est le principe du Policy-as-Code.
Des outils comme Open Policy Agent (OPA) ou Kyverno s'intègrent directement à l'API Server de Kubernetes. Ils agissent comme des contrôleurs d'admission, interceptant chaque requête de déploiement pour la valider contre un ensemble de règles que vous avez définies.
Par exemple, vous pouvez écrire une politique qui refuse tout déploiement d'une image Docker qui ne provient pas de votre registre d'entreprise, qui n'est pas signée cryptographiquement ou qui contient des vulnérabilités critiques connues. C'est un point de contrôle essentiel dans un pipeline Zero Trust.
# Exemple de politique Kyverno simple
# Bloque les images qui n'utilisent pas le tag 'latest'
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-latest-tag
spec:
validationFailureAction: enforce
rules:
- name: validate-image-tags
match:
resources:
kinds:
- Pod
validate:
message: "L'utilisation du tag 'latest' est interdite."
pattern:
spec:
containers:
- image: "!*:latest"Au-delà du Pipeline : Observabilité et Réponse Continue
Mettre en place des barrières est une chose, mais la philosophie Zero Trust nous enseigne à "présumer de la compromission". Cela signifie que nous devons avoir la capacité de détecter, d'analyser et de répondre à une menace qui aurait réussi à franchir les premières lignes de défense.
C'est ici que l'Observabilité devient un pilier de sécurité. Il ne s'agit pas seulement de monitoring (surveiller des métriques connues), mais de pouvoir poser des questions complexes sur l'état de votre système pour comprendre des comportements inconnus et inattendus.
Les Limites et les Coûts Cachés de l'Approche
Adopter une architecture Zero Trust est un projet ambitieux qui comporte son lot de défis. Il est crucial de ne pas sous-estimer la complexité et les efforts requis pour une mise en œuvre réussie, qui va bien au-delà de la simple installation de quelques outils.
La transformation est autant culturelle que technique. Les équipes de développement, d'opérations et de sécurité doivent collaborer plus étroitement que jamais, en intégrant la sécurité dès la phase de conception (Shift Left Security).
- Complexité de Gestion : La gestion des identités, des politiques et des certificats pour des milliers de microservices peut rapidement devenir un casse-tête si elle n'est pas massivement automatisée.
- Surcharge de Performance : Le chiffrement systématique de tout le trafic Est-Ouest (entre services) avec mTLS peut introduire une latence, même si elle est souvent négligeable avec les solutions modernes.
- Débogage : Diagnostiquer un problème de communication entre deux services peut s'avérer plus complexe quand des politiques réseau et des certificats sont impliqués. Une bonne observabilité est non négociable.
- Coût des Outils : Bien que de nombreuses briques soient open-source (SPIFFE/SPIRE, OPA, Istio), les solutions d'entreprise qui simplifient leur gestion ont un coût non négligeable.
Zero Trust : Moins une Destination qu'un Voyage Continu
Vous l'aurez compris, le Zero Trust n'est pas un interrupteur que l'on bascule sur "ON". C'est un processus itératif, un engagement vers une amélioration continue de votre posture de sécurité. Chaque service que vous segmentez, chaque politique que vous automatisez, et chaque identité que vous renforcez est un pas dans la bonne direction.
En tant qu'ingénieur DevOps, votre rôle est central. Vous êtes les architectes et les gardiens des autoroutes de l'information que sont les pipelines CI/CD. En y intégrant les principes de la confiance zéro, vous ne construisez pas seulement des applications plus robustes, vous bâtissez les fondations d'une infrastructure résiliente, prête à affronter les menaces d'aujourd'hui et de demain.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
21 commentaires
Vouloir tout verrouiller d'un coup. Le Zero Trust, c'est un voyage, pas un interrupteur.
Commence par segmenter les namespaces les plus critiques avant de généraliser.
C'est quoi le pire piège quand on migre vers cette archi ?
Oui, c'est possible. Mais tu paies en ingénierie ce que tu économises en licences.
Gérer
SPIREetOPAà la main demande une équipe Ops dédiée.L'article mentionne le coût des outils. Est-ce qu'on peut faire du Zero Trust avec du pur open source sans finir sur la paille ?
C'est là qu'il faut coupler ça avec la signature d'images (Cosign). Le tag ne veut rien dire.
Il faut valider la signature cryptographique au moment de l'admission pour garantir l'intégrité.
J'ai testé
Kyvernopour interdire le taglatest, ça marche nickel. Mais quid des images qui sont poussées avec le même tag mais un contenu différent ?C'est le revers de la médaille. Il faut des outils de tracing comme
Jaegerpour voir où le paquet est bloqué.Sans visibilité sur le flux Est-Ouest, tu es aveugle.
Comment tu gères le debug des politiques réseau quand tout est cloisonné ? C'est le cauchemar des devs.
Totalement d'accord. Le Zero Trust impose d'utiliser un coffre-fort externe comme HashiCorp Vault injecté via des secrets CSI drivers.
Ne jamais mettre de données sensibles dans des objets Kubernetes standards.
Bonne question. C'est une hérésie de mettre des secrets en clair dans
etcd.Est-ce qu'on peut vraiment parler de Zero Trust si on utilise toujours des secrets stockés dans des
ConfigMapsnon chiffrés ?Il faut monitorer les métriques de l'agent
SPIRE. S'il n'arrive pas à contacter le serveur, tes workloads ne recevront plus de certificats valides.C'est là que l'observabilité devient critique, comme je l'ai précisé dans l'article.
Le passage sur
SPIFFEm'intéresse. Tu conseilles quoi pour monitorer la délivrance des SVIDs quand ça commence à ramer ?Tout dépend de ton besoin de conformité. Si tu dois prouver que rien ne tourne en root,
OPAest imbattable pour automatiser ça.Si tu as moins de 10 microservices, c'est probablement sortir l'artillerie lourde. Mais dès que tu montes en charge, tu ne peux plus gérer les RBAC à la main.
Est-ce que tu penses que
OPAest overkill pour des petits clusters ?Exactement. Il faut toujours utiliser le
validationFailureAction: auditau début pour voir l'impact avant de passer enenforce.On traite les policies comme du code applicatif : tests unitaires sur les règles et CI dédiée.
Clairement, un mauvais test et tu te retrouves avec un cluster qui refuse tout déploiement. À ne jamais faire en prod sans un mode audit préalable.
Le
Policy-as-Codec'est bien beau sur le papier, mais comment tu fais pour tester tes politiquesKyvernosans casser la prod ?C'est une crainte classique. Avec des sidecars comme ceux d'Istio ou Linkerd, la latence est très faible aujourd'hui.
Le vrai gain, c'est de sortir du modèle IP statique. Une fois que tu as implémenté
SPIRE, tu ne te soucies plus du réseau, tout est géré par l'identité cryptographique.Article intéressant, mais le Zero Trust à grande échelle, c'est l'enfer à gérer. Comment tu évites que le mTLS ne devienne un goulot d'étranglement sur le throughput ?