Vous pensiez maîtriser le multi-cloud ? Préparez-vous à l'ère du calcul fluide.
Oubliez les débats stériles opposant le cloud public, le edge computing ou les serveurs on-premise. La véritable révolution ne réside plus dans le choix d'un emplacement, mais dans la capacité à ne plus avoir à choisir du tout. Nous entrons dans une ère où les applications ne sont plus des monolithes statiques déployés à un endroit, mais des flux de travail dynamiques qui se déplacent intelligemment là où elles sont le plus efficaces, un concept que l'industrie nomme désormais le Fluid Computing.
Cette approche change radicalement notre vision de l'infrastructure. Elle ne se conçoit plus comme une collection de silos (AWS, Azure, votre datacenter), mais comme un continuum unique et intelligent. Au cœur de ce système se trouve une IA qui agit comme un chef d'orchestre global, déplaçant les charges de travail en temps réel pour optimiser un savant mélange de coût, de latence, de performance et de souveraineté des données.
Pour vous, futurs architectes DevOps, comprendre ce paradigme n'est pas une option, c'est une nécessité. Il s'agit de passer d'une logique de configuration statique à une logique de définition d'objectifs métier, en laissant la machine gérer l'exécution de la manière la plus optimale possible.
Les piliers de l'architecture fluide : Orchestration, Continuum et Abstraction
Pour qu'une application puisse "flotter" librement d'un environnement à un autre, trois composantes fondamentales doivent fonctionner en parfaite harmonie. Il ne s'agit pas simplement d'une nouvelle version de Kubernetes, mais d'une refonte philosophique de la manière dont nous concevons, empaquetons et gérons le cycle de vie de nos services.
Le Continuum Cloud-Edge-OnPrem : Votre nouveau terrain de jeu
La première étape consiste à cesser de voir les différents environnements d'hébergement comme des entités séparées. Le continuum les fusionne en une seule et même ressource de calcul globale, où chaque zone possède des caractéristiques uniques que l'orchestrateur peut exploiter.
Concrètement, l'AI Orchestrator ne se demande plus "Dois-je déployer sur AWS ou sur notre rack local ?". Il analyse les besoins de la charge de travail et la cartographie des ressources disponibles pour prendre la meilleure décision à l'instant T. Un traitement de données massif et non sensible ? Il l'enverra sur une instance spot cloud au coût le plus bas. Une API nécessitant une latence ultra-faible pour les utilisateurs d'une usine connectée ? Il la migrera instantanément sur un serveur Edge situé à quelques mètres de là.
| Zone du Continuum | Avantage principal | Cas d'usage typique | Contrainte majeure |
|---|---|---|---|
| Cloud Public (Hyperscalers) | Élasticité et puissance de calcul quasi infinies | Entraînement de modèles IA, batch processing, stockage de masse | Coûts d'egress, latence variable |
| Edge Computing | Latence extrêmement faible, traitement local | IoT, applications temps réel, points de vente | Ressources limitées, gestion de flotte complexe |
| On-Premise (Datacenter privé) | Souveraineté des données, sécurité et performances prédictibles | Bases de données critiques, applications legacy, données sensibles | Coût d'investissement initial, manque de flexibilité |
Le Manifeste Fluide : Décrire l'intention, pas l'implémentation
Au cœur de cette magie se trouve un nouveau type d'artefact de déploiement : le manifeste fluide. Pensez-y comme un fichier docker-compose.yml ou un chart Helm sous stéroïdes, mais avec une différence fondamentale. Au lieu de décrire précisément *où* et *comment* déployer, vous décrivez les *objectifs* et les *contraintes* de votre application.
L'orchestrateur IA utilise ce manifeste comme son cahier des charges. Il interprète vos intentions et les traduit en décisions de placement concrètes. C'est un changement de paradigme : vous ne gérez plus l'infrastructure, vous gérez la politique de service de votre application.
apiVersion: fluid.io/v1alpha1
kind: AdaptiveWorkload
metadata:
name: real-time-analytics-api
spec:
# Définition des composants de l'application
components:
- name: data-ingestor
image: my-registry/ingestor:2.5.1
resources:
requests:
cpu: "500m"
memory: "1Gi"
- name: query-engine
image: my-registry/query-engine:1.9.0
resources:
requests:
cpu: "2000m"
memory: "8Gi"
# Définition des objectifs et contraintes (la magie est ici)
policy:
optimization_goal: latency # peut être 'cost', 'performance', 'carbon_footprint'
constraints:
- type: data_sovereignty
params:
region: "eu-central-1" # Les données ne doivent jamais quitter cette région
- type: max_latency
target: component(query-engine)
params:
percentile: 99
value_ms: 50
- type: max_cost
params:
per_hour_usd: 2.50Visualiser le flux : La migration d'un workload en temps réel
Pour bien saisir la puissance de ce modèle, rien de tel qu'un schéma. Imaginons un service de traitement vidéo. Initialement, le traitement lourd (transcoding-worker) tourne sur une instance GPU puissante mais coûteuse dans le cloud. Lorsqu'une requête arrive d'un appareil mobile connecté à un réseau 5G local, l'orchestrateur détecte une opportunité d'optimisation de la latence.
Le système décide alors de migrer dynamiquement un clone du worker sur un nœud Edge plus proche de l'utilisateur final pour traiter cette requête spécifique. Une fois le travail terminé, le worker Edge peut être détruit pour libérer les ressources. L'application s'est littéralement déplacée pour se rapprocher de l'utilisateur, de manière totalement transparente.
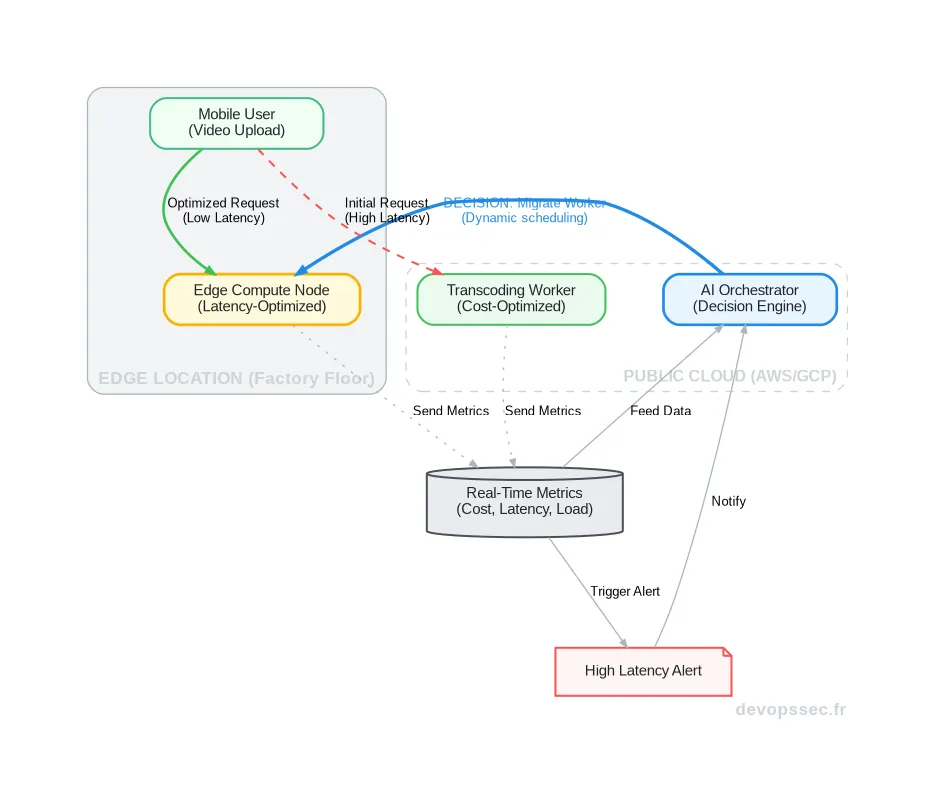
Ce schéma illustre parfaitement la boucle de rétroaction au cœur du Fluid Computing. Le système n'est pas statique il observe, analyse et agit en permanence. La surveillance des métriques n'est plus seulement destinée à l'alerte humaine, elle devient le principal carburant du moteur de décision de l'infrastructure elle-même.
Les défis cachés : Observabilité et Sécurité dans un monde en mouvement
Cette agilité a un coût, et il se paie principalement en complexité. Quand un microservice peut se trouver sur AWS à 10h du matin, sur un cluster on-premise à 10h05 et sur un nœud Edge à 10h06, comment le déboguer ? Comment sécuriser un périmètre qui n'existe plus ?
L'observabilité devient un enjeu capital. Vos outils de logging, de tracing et de monitoring doivent être enrichis d'une nouvelle dimension : la localité. Chaque log, chaque trace doit impérativement contenir des métadonnées indiquant non seulement le service émetteur, mais aussi le nœud physique et la zone géographique où il s'exécutait à la nanoseconde près. Sans cela, toute investigation d'incident devient un cauchemar insoluble.
Du côté de la sécurité, le paradigme du château fort avec un pare-feu en guise de pont-levis est totalement obsolète. Le modèle de confiance doit voyager avec la charge de travail. Cela implique l'adoption massive de principes Zero Trust, où l'identité du service, l'authentification mutuelle (mTLS) et des politiques de sécurité fines (policy-as-code) sont embarquées au sein même du workload, peu importe où il s'exécute.
Attention aux coûts d'egress !
La migration "magique" d'un workload entre différents fournisseurs de cloud public peut générer des factures de sortie de données (egress fees) astronomiques et imprévisibles. Une politique de coût dans le manifeste fluide est essentielle pour instruire l'orchestrateur de ne déplacer que les services stateless ou ceux dont la migration des données a un coût maîtrisé.
Conclusion : Devenir l'architecte des intentions, pas des serveurs
Le Fluid Computing n'est pas une simple évolution technologique, c'est une véritable mutation du métier de DevOps. Votre rôle s'éloigne de plus en plus de la gestion manuelle de l'infrastructure pour se rapprocher de celui d'un architecte de systèmes autonomes. Votre valeur ajoutée ne résidera plus dans votre capacité à configurer un VNet Azure ou un VPC AWS, mais dans votre habileté à rédiger des politiques de service intelligentes et efficaces.
Vous apprendrez à raisonner en termes d'objectifs métier : "Je veux que cette API réponde en moins de 30ms pour 99% de mes utilisateurs européens, tout en ne dépassant pas 5000€ de budget mensuel et en respectant le RGPD". C'est cette déclaration d'intention que la machine se chargera ensuite d'exécuter de la manière la plus optimale possible.
Ce futur est à la fois complexe et fascinant. Il exige une montée en compétence sur l'observabilité distribuée, la sécurité Zero Trust et l'automatisation basée sur l'IA. Mais il promet aussi une infrastructure enfin alignée, en temps réel, sur les objectifs réels de l'entreprise. Préparez-vous à surfer sur la vague.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
23 commentaires
Le garde-fou est au niveau du manifeste :
Si cette contrainte est définie, l'orchestrateur est hardcodé pour interdire tout déploiement hors de la zone spécifiée, peu importe le coût ou la latence.
C'est surtout une question de souveraineté. Si mon app peut migrer sur AWS alors qu'elle devrait rester on-premise pour respecter la RGPD, j'ai besoin d'un garde-fou très robuste.
Tout ça pour gagner 20ms de latence. Le retour sur investissement me semble bien faible par rapport au risque de tout casser.
On utilise un service mesh (type Istio ou Linkerd) avec une configuration multi-cluster activée par défaut.
Le service discovery est totalement abstrait pour l'application, qui pointe toujours vers le même service virtuel, peu importe où il est physiquement situé.
Le 11 a raison. Le DNS est le talon d'Achille de ce genre d'architecture.
Comment vous gérez le service discovery quand l'IP change à chaque déplacement ?
J'attends de voir la tête des logs quand un service passe d'un cluster on-premise à un cluster cloud.
Vous allez avoir un décalage temporel, des problèmes de résolution DNS et j'en passe. La théorie est séduisante mais la pratique sera un enfer.
La stack est basée sur des projets open source existants, couplés à un contrôleur custom qui gère la logique de placement.
L'idée est de standardiser cette API
AdaptiveWorkloadpour éviter le lock-in fournisseur.Quels sont les outils réels derrière ? C'est basé sur quoi ?
Si c'est du propriétaire, c'est mort pour l'adoption.
L'abstraction est nécessaire pour gérer la complexité grandissante du hybride-cloud.
On ne peut plus gérer manuellement 50 clusters avec des configs séparées. L'intention, c'est justement de déléguer la gestion technique pour se concentrer sur le besoin métier.
Je suis d'accord avec le 8. Le DevOps c'est avant tout de la simplicité. Plus on ajoute de couches d'abstraction, plus on crée de la dette technique.
Le "Fluid Computing" ça ressemble à une solution à la recherche d'un problème.
C'est trop complexe pour des équipes de taille moyenne. Qui va maintenir cette stack ?
Déjà qu'on galère avec
kubectl applysur un seul cluster, alors là, bonjour l'usine à gaz.En cas de perte de connectivité, le système passe en mode "fail-safe" : il verrouille le workload sur le dernier nœud stable connu.
La continuité de service prime sur la recherche d'optimisation.
J'ai bossé sur des systèmes distribués, le problème c'est pas l'orchestration, c'est le réseau.
Le "continuum" c'est bien joli sur le papier, mais quand t'as un split-brain sur ton réseau entre le edge et le cloud, ton IA elle fait quoi ? Elle coupe tout ?
Mouais. Ça ressemble à du Kubernetes avec une surcouche marketing. Pourquoi ne pas juste utiliser une bonne stratégie de déploiement multi-cluster ?
Tu as raison, c'est le point critique. Voici comment on limite les dégâts dans le manifeste :
Si le coût estimé dépasse le seuil, la migration est bloquée par l'orchestrateur.
Le coût d'egress, vous en parlez à peine. Si ton orchestrateur se trompe et fait transiter des To de données entre AWS et ton datacenter, ta facture explose à la fin du mois.
Comment on empêche ça concrètement dans le
yaml?L'IA ne décide pas en autonomie totale. Elle travaille sur la base de tes politiques.
Si tu définis dans ton manifeste que la
max_latencyest une contrainte absolue, l'IA ne peut pas outrepasser cette règle. Tu restes le maître du jeu, tu ne configures plus des serveurs, tu configures des intentions.Moi ce qui me fait peur, c'est l'IA qui décide. On a déjà assez de mal avec les autoscalers classiques qui font n'importe quoi en période de pic.
Laisser une IA décider de basculer une prod critique sur un nœud Edge potentiellement instable, c'est à ne jamais faire en prod sans une supervision humaine stricte.
Et la sécurité dans tout ça ? Vous parlez de Zero Trust, mais en vrai, gérer des certificats
mTLSqui doivent être valides sur des infrastructures aussi disparates, c'est un enfer à maintenir.C'est une excellente question. Le Fluid Computing ne déplace pas aveuglément tout et n'importe quoi.
Le manifeste permet de définir des contraintes de localité. Si la donnée est lourde, l'orchestrateur garde le service à proximité immédiate du stockage. On ne déplace que ce qui est stateless ou optimisé pour le transfert.
C'est bien beau de parler de migration dynamique, mais quid de la persistance des données ?
Tu déplaces ton conteneur, super. Et tes données ? Tu fais comment pour éviter la latence réseau quand ta DB est sur ton cluster on-prem et ton app sur le cloud ? C'est la porte ouverte aux problèmes de performance majeurs.
Je comprends le scepticisme, mais le debug n'est pas un angle mort. L'observabilité est intégrée au manifeste.
Si ton
AdaptiveWorkloaddéplace un service, il embarque ses métadonnées de localité. C'est justement ce qui évite de perdre le fil lors d'un incident.Encore un énième concept marketing pour vendre du rêve. Le "Fluid Computing" c'est juste une usine à gaz de plus qui va rendre le debug impossible.
Déjà qu'avec Kubernetes c'est parfois le bazar pour savoir pourquoi un pod crash, si en plus il change de zone géographique tout seul, je vous souhaite bien du courage pour lire vos logs.