Votre pipeline CI/CD est-il vraiment aussi rapide qu'il pourrait l'être ?
Vous avez passé des mois, voire des années, à affiner vos scripts, à paralléliser vos tests et à optimiser chaque couche de vos conteneurs. Pourtant, face à la complexité croissante des architectures microservices, une question demeure : et si l'ordre même dans lequel vos tâches s'exécutent était le véritable goulot d'étranglement ?
Nous touchons ici aux limites de l'optimisation humaine et des planificateurs traditionnels. Pour franchir ce cap, une nouvelle approche émerge, non pas de la science-fiction, mais de la physique fondamentale. Il s'agit du DevOps Quantum-Inspiré, une méthode qui promet de repenser radicalement l'efficacité de nos systèmes.
Oubliez les ordinateurs quantiques hors de prix. Nous parlons ici d'algorithmes classiques, exécutables sur votre infrastructure actuelle, mais qui s'inspirent des principes déroutants de la mécanique quantique pour résoudre des problèmes d'optimisation jusqu'alors insolubles.
Démystifier l'Optimisation d'Inspiration Quantique
Avant d'aller plus loin, clarifions un point essentiel. Utiliser une approche "Quantum-Inspired" ne signifie pas que vous allez installer un ordinateur quantique dans votre datacenter. Il s'agit d'une pure abstraction logicielle, une nouvelle famille d'algorithmes d'optimisation qui tournent sur des processeurs classiques.
Ces algorithmes imitent les concepts de superposition et d'intrication pour explorer un nombre astronomique de solutions possibles simultanément, là où un algorithme classique les évaluerait une par une. C'est un changement de paradigme pour l'orchestration des workflows complexes.
Le pipeline, ce casse-tête combinatoire
Imaginez un pipeline de déploiement pour une application composée de 50 microservices. Certains tests doivent s'exécuter avant d'autres, certaines tâches de build dépendent de plusieurs artefacts, et vous disposez d'un parc limité de runners avec des capacités hétérogènes (CPU, GPU, RAM).
Déterminer la séquence parfaite qui minimise le temps total d'exécution tout en respectant les contraintes de ressources est un problème d'optimisation combinatoire. C'est précisément le type de défi où les approches traditionnelles, basées sur des files d'attente ou des règles statiques, montrent leurs limites.
Le schéma ci-dessous illustre un flux de CI/CD modérément complexe. Chaque nœud représente une tâche, et chaque flèche une dépendance. L'enjeu est de trouver le chemin critique le plus court en allouant intelligemment les ressources disponibles.
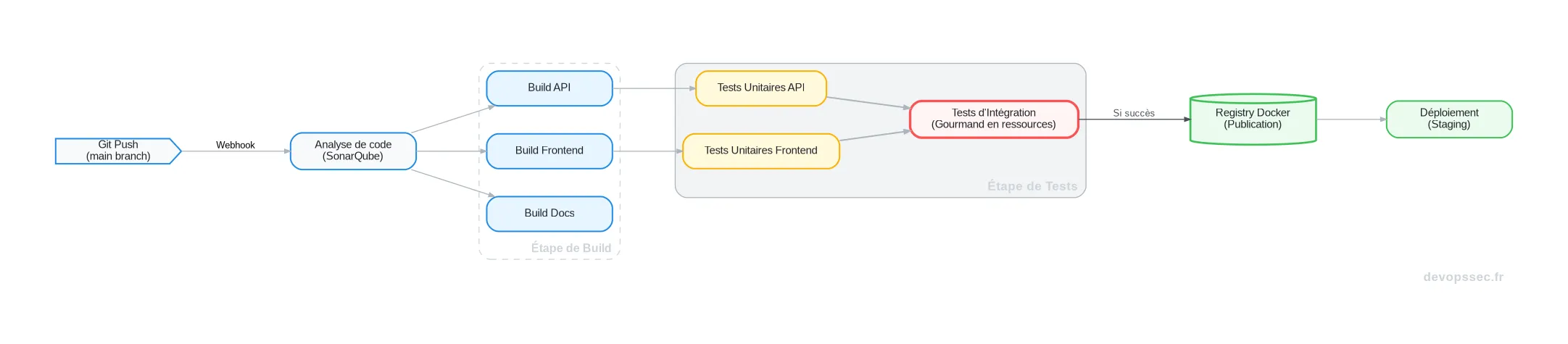
Ce graphe montre bien que certaines tâches peuvent être parallélisées, mais des points de synchronisation, comme les tests d'intégration, créent des goulets d'étranglement. Un optimiseur quantique-inspiré explore toutes les permutations possibles pour allouer les runners de la manière la plus efficace à chaque étape.
Orchestrer concrètement avec un solveur "QI"
Passons de la théorie à la pratique. Pour utiliser un tel système, il ne s'agit pas de réécrire vos pipelines CI/CD. L'idée est d'insérer une nouvelle étape de "planification" en amont, orchestrée par un service dédié que nous appellerons le "solveur".
Définir le problème d'optimisation
La première étape consiste à décrire votre workflow sous une forme que le solveur peut comprendre. Cela se fait généralement via un fichier de configuration, souvent en YAML, qui définit les tâches, leurs dépendances et leurs exigences en ressources. Ce fichier devient la "source de vérité" de votre problème.
# Fichier: pipeline-optimization-problem.yml
# Description du workflow pour le solveur QI
tasks:
- id: build-service-A
duration_estimate: 300 # en secondes
resources: { cpu: 2, memory: 4Gi }
- id: build-service-B
duration_estimate: 450
resources: { cpu: 4, memory: 8Gi }
- id: integration-tests
duration_estimate: 1200
resources: { cpu: 8, memory: 16Gi }
depends_on: [build-service-A, build-service-B]
# Définition du parc de machines disponibles (runners)
resource_pool:
- id: runner-small
count: 10
spec: { cpu: 2, memory: 4Gi }
- id: runner-large
count: 2
spec: { cpu: 8, memory: 16Gi }Ce fichier modélise un problème simple : deux tâches de build peuvent s'exécuter en parallèle, mais les tests d'intégration, très gourmands, ne peuvent démarrer qu'une fois les deux builds terminés. Le tout doit s'exécuter sur un parc de runners hétérogène et limité.
Comparaison des approches de planification
Une fois le problème défini, le solveur explore l'espace des solutions. Il ne se contente pas de prendre la première tâche disponible dans une file d'attente il élabore une stratégie globale. Le résultat est souvent contre-intuitif mais radicalement plus efficace.
| Critère | Planificateur Classique (FIFO) | Planificateur d'Inspiration Quantique |
|---|---|---|
| Logique de décision | Séquentielle, basée sur des règles (premier arrivé, premier servi) | Holistique, recherche de l'optimum global pour l'ensemble du workflow |
| Gestion des ressources | Réactive (alloue si disponible, sinon attend) | Proactive (peut retarder une tâche pour libérer une ressource clé pour une autre) |
| Temps d'exécution total (scénario ci-dessus) | ~1950 secondes | ~1650 secondes (en parallélisant sur les runners small et réservant le large) |
| Complexité de mise en place | Faible | Élevée (nécessite une modélisation précise du problème) |
Attention à la modélisation
Le principal défi de cette approche n'est pas l'algorithme lui-même, mais la qualité des données que vous lui fournissez. Des estimations de durée ou de consommation de ressources erronées peuvent conduire à une planification "optimale" sur le papier, mais totalement inefficace en pratique.
Les angles morts de cette révolution
Cependant, cette technologie n'est pas une solution miracle et comporte son lot de contraintes. Elle est conçue pour l'optimisation de systèmes distribués à très grande échelle. L'appliquer à un pipeline simple avec quelques tâches séquentielles serait comme utiliser un marteau-pilon pour écraser une noix.
Le coût de calcul de la phase de planification elle-même n'est pas négligeable. Pour des workflows très complexes, le solveur peut prendre plusieurs dizaines de secondes, voire quelques minutes, pour trouver la solution optimale. Ce délai initial doit être inférieur au gain de temps obtenu sur l'exécution totale pour que l'approche soit rentable.
Enfin, la sécurité de ces solveurs, souvent proposés en mode SaaS, est une préoccupation majeure. Vous leur confiez la description détaillée de votre infrastructure et de vos processus de build, des données potentiellement très sensibles. Une analyse de risque approfondie est donc indispensable avant toute adoption.
Conclusion : L'aube de l'orchestration auto-optimisée
L'approche DevOps d'inspiration quantique nous ouvre les portes d'une nouvelle ère. Nous passons d'une automatisation qui exécute des ordres à une automatisation qui prend des décisions stratégiques pour atteindre un objectif global, comme la réduction du "cycle time".
Ce n'est plus à l'ingénieur de deviner la meilleure façon de paralléliser ses tâches c'est à la machine de la découvrir en explorant un champ de possibilités bien au-delà de l'intuition humaine. Le rôle du DevOps évolue donc vers celui d'un architecte qui modélise les problèmes, et non plus seulement celui qui écrit les scripts.
Bien que encore émergente, cette technologie trace une voie claire pour l'avenir de l'ingénierie logicielle. Elle est la promesse de systèmes capables de s'adapter et de s'optimiser en permanence face à une complexité qui, elle, ne cessera jamais de croître.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
24 commentaires
Quand ton pipeline tourne 24/7 et que tu payes des instances GPU à la seconde, 10% de gain c'est des milliers d'euros par mois.
Tout dépend de l'échelle de ton infra, ce n'est pas fait pour tout le monde.
Faut quand même avouer que c'est une sacrée usine à gaz pour gagner 10% de temps sur un pipeline.
C'est là que l'inspiration quantique aide.
Au lieu de chercher l'optimum absolu, on cherche une "solution suffisamment bonne" en un temps limité. On coupe la recherche dès qu'on atteint un plateau.
J'ai des doutes sur la scalabilité du solveur quand on dépasse 500 microservices.
Le temps de calcul risque d'exploser non ?
C'est le Saint Graal.
Si ton solveur connaît le temps de boot d'un pod sur ton infra, il peut demander le scaling 30 secondes avant de lancer la tâche lourde. Ça supprimerait le délai de démarrage.
On utilise du Kubernetes Event-driven Autoscaling (KEDA) pour scaler nos runners.
Est-ce que ton solveur pourrait parler à KEDA pour anticiper le scaling ?
C'est l'enfer à intégrer dans des outils legacy.
Le mieux, c'est de sortir la logique de planification du pipeline lui-même. Tu configures ton CI pour qu'il demande au solveur "quel est le prochain job à lancer ?" via une API au lieu d'avoir un fichier
.gitlab-ci.ymlstatique.Tu penses quoi du support de ça dans les outils comme Jenkins ou GitLab CI ?
Ça me semble ultra complexe à intégrer proprement.
Bien vu. Il faut ajouter une pénalité de "coût de cache" dans la fonction objectif de ton solveur.
Si le coût de reconstruction est trop élevé, le solveur préférera attendre qu'un runner avec le cache chaud se libère plutôt que de paralléliser sur un runner froid.
J'ai testé un POC similaire avec des tâches
docker build.Le problème c'est le cache. Si tu changes l'ordre d'exécution, tu perds le bénéfice du layer caching.
Exactement. Le solveur doit être déclenché par un événement.
Si une tâche échoue, tu envoies un signal au solveur qui marque le nœud comme "failed" et il relance une optimisation sur les branches restantes.
Est-ce que ça peut gérer des tâches qui échouent ?
Si
build-service-Aplante, le solveur doit recalculer tout le graphe en live ?Je comprends, c'est une limite majeure.
Il existe des bibliothèques open source pour faire tourner ça en local, mais tu perds l'avantage de la puissance de calcul du SaaS. C'est un arbitrage entre sécu et perf.
Tu mentionnes des solveurs en SaaS.
C'est mort pour moi, mon boss refusera jamais d'envoyer la topologie de notre infra sur un cloud externe.
C'est le gros défaut de l'approche holistique : l'opacité.
Pour contrer ça, on génère un log de décision (généralement en
json) qui liste les contraintes satisfaites. C'est pas lisible par un humain en temps réel, mais c'est auditables après coup.L'idée de déléguer la planification me fait un peu peur pour le debug.
Si le pipeline prend une décision bizarre, comment tu expliques pourquoi il a choisi cet ordre plutôt qu'un autre ?
T'as mis le doigt dessus. C'est effectivement basé sur de l'optimisation combinatoire.
Le côté "quantique-inspiré" c'est l'utilisation d'heuristiques qui imitent le recuit simulé ou l'effet tunnel pour éviter de rester bloqué dans des minima locaux, là où un algorithme glouton classique se ferait piéger.
Ça ressemble à du Linear Programming classique avec un nom marketing par-dessus.
C'est quoi la différence réelle avec un simple solveur type OR-Tools de Google ?
Le solveur ne gère pas le cluster lui-même, il planifie juste la séquence.
Pour la sécurité, tu dois définir des quotas dans ton namespace. Le solveur travaille sur une vue statique, c'est à l'orchestrateur (K8s) d'appliquer les limites via des
ResourceQuota.Tu parles d'un
resource_poolhétérogène dans ton YAML.Comment tu empêches le solveur de sur-allouer des ressources si tu as des pics de charge externes sur ton cluster Kubernetes ?
C'est le point critique. Si tes mesures sont nazes, le résultat sera forcément faux.
La solution c'est d'utiliser une boucle de feedback. Tu injectes les durées réelles dans le solveur à chaque itération pour qu'il affine ses prédictions pour le prochain run. C'est de l'apprentissage statistique de base.
J'aime bien l'idée de modéliser via
pipeline-optimization-problem.yml.Mais concrètement, comment tu gères les dérives sur les
duration_estimate? Si une tâche prend 2x plus de temps que prévu, ton plan optimal tombe à l'eau.C'est exactement ce que je dis dans la partie sur les angles morts.
Si ton workflow est linéaire, tu ne verras jamais de gain. C'est pertinent seulement quand tu as des dépendances croisées complexes et un parc de
resource_poollimité où l'ordonnancement FIFO classique te fait perdre du temps bêtement.Encore un buzzword pour vendre du conseil ?
Le coup du solveur qui prend 2 minutes pour décider quoi lancer, c'est juste une perte de temps si ton build ne dure que 5 minutes.