DevOps Cognitif : L'IA Co-Pilote de Vos Opérations Complexes
La complexité de nos systèmes distribués a atteint un point de rupture. Chaque jour, des milliers de métriques, de traces et de logs sont générés, créant un bruit de fond assourdissant qui noie les signaux critiques. Pour les équipes SRE et Ops, la charge cognitive est devenue intenable, transformant la gestion d'incidents en une quête désespérée d'une aiguille dans une botte de foin numérique.
C'est précisément ici que le DevOps Cognitif entre en scène. Il ne s'agit plus de simples dashboards ou d'alertes basiques, mais de l'intégration d'une intelligence artificielle qui agit comme un véritable co-pilote. Son rôle n'est pas de remplacer l'ingénieur, mais de l'augmenter : filtrer le bruit, corréler des événements apparemment sans lien et proposer des actions pertinentes pour maintenir la résilience du système.
Du Monitoring Classique à l'Observabilité Augmentée par l'IA
Pendant des années, nous nous sommes contentés de monitorer des silos : la santé du CPU, l'utilisation de la mémoire, le statut d'un service. Cette approche est aujourd'hui dépassée. Elle ne nous dit pas "pourquoi" un système ralentit, elle nous dit simplement "qu'il" ralentit. Le passage à l'Observabilité a été la première révolution, nous forçant à unifier trois piliers de données : les métriques (le "quoi"), les traces (le "où") et les logs (le "pourquoi").
Pourtant, même avec ces trois piliers, le volume de données reste un défi majeur. L'étape suivante consiste donc à appliquer une couche d'intelligence sur cette masse d'informations pour en extraire du sens. C'est le cœur du DevOps Cognitif : transformer des données brutes en sagesse opérationnelle actionnable.
Le Rôle du Co-Pilote IA dans la Corrélation d'Incidents
Imaginez une latence qui augmente sur votre API principale. Le monitoring classique vous alerte sur le symptôme. L'observabilité vous montre la trace distribuée qui révèle un ralentissement dans une requête de base de données. Mais le co-pilote IA va plus loin. Il analyse en temps réel les logs de déploiement, les métriques des nœuds Kubernetes sous-jacents et les traces des services dépendants.
Il pourrait découvrir que cette latence coïncide systématiquement avec une augmentation des erreurs de cache Redis sur un autre service, un événement qui, pour un humain, semblerait totalement déconnecté. L'IA établit cette corrélation cachée, identifie la cause racine probable et la présente à l'équipe SRE, lui faisant gagner un temps précieux.
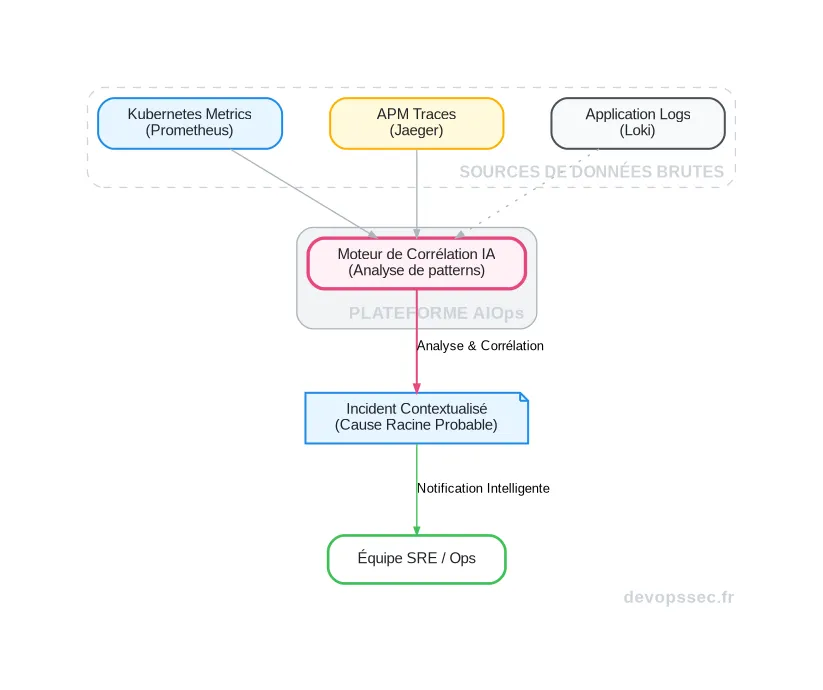
Ce schéma illustre parfaitement le flux de données. Les métriques, traces et logs ne sont plus analysés isolément par un humain. Ils convergent vers un moteur d'IA qui agit comme un cerveau central, digérant la complexité pour produire un rapport d'incident clair et directement exploitable par l'équipe d'astreinte.
Filtrage Intelligent du Bruit : Moins d'Alertes, Plus de Contexte
La fatigue liée aux alertes est l'un des pires fléaux des équipes opérationnelles. Des centaines de notifications non critiques finissent par désensibiliser les ingénieurs, qui risquent de manquer le véritable incident lorsqu'il se produit. L'IA excelle dans le filtrage et la priorisation de ce bruit.
En apprenant le comportement "normal" de votre système (ce qu'on appelle le baseline), le co-pilote cognitif est capable de distinguer une anomalie statistique d'un véritable problème impactant les utilisateurs. Il ne se contente pas de déclencher une alerte, il l'enrichit avec un contexte précieux.
- Suppression des doublons : L'IA regroupe des dizaines d'alertes symptomatiques (CPU élevé, latence en hausse, erreurs 500) en un seul incident majeur.
- Analyse d'impact : Elle peut estimer quels services ou fonctionnalités utilisateurs sont affectés, permettant de prioriser la réponse.
- Détection de saisonnalité : Elle apprend que l'utilisation du CPU augmente tous les jours à 9h et cesse de vous alerter inutilement pour ce comportement normal.
- Identification des "First Movers" : Elle met en évidence l'événement initial qui a déclenché une cascade de défaillances, guidant l'ingénieur directement vers la source du problème.
L'IA en Action : Cas Pratiques du DevOps Cognitif
Au-delà de la gestion d'incidents, l'IA s'infuse dans tout le cycle de vie opérationnel, de la prévention à la remédiation. Elle devient un partenaire stratégique pour construire des systèmes plus robustes et plus efficients.
Analyse Prédictive des Défaillances
Le Graal de la gestion des opérations n'est pas de résoudre les pannes rapidement, mais de les empêcher de se produire. Grâce à l'analyse de séries temporelles sur des millions de points de données, les modèles de Machine Learning peuvent détecter des dégradations de performance subtiles, bien avant qu'elles ne franchissent les seuils d'alerte traditionnels.
Par exemple, un modèle pourrait détecter une légère mais constante augmentation de la latence d'une requête spécifique ou une consommation de mémoire qui dérive lentement. Il peut alors créer un ticket préventif pour l'équipe de développement, en signalant une potentielle fuite de mémoire ou une requête SQL qui deviendra problématique à plus grande échelle.
# Exemple de configuration d'une politique de détection d'anomalie
apiVersion: aiops.example.com/v1alpha1
kind: AnomalyDetectionPolicy
metadata:
name: predict-disk-full-api-db
spec:
target:
kind: StatefulSet
name: mysql-primary
metric: persistentvolume_used_percent
algorithm: linear_regression_forecast
sensitivity: medium
thresholds:
- severity: warning
value: 85
forecast_hours: 72 # Alerte si le disque risque d'être plein à 85% dans les 72h
- severity: critical
value: 95
forecast_hours: 24
actions:
- type: create_ticket
project: SRE
assignee: {{ on_call_person }}Ce type de politique prédictive transforme une équipe réactive en une équipe proactive. Au lieu de se réveiller en pleine nuit car un disque est plein, l'équipe est notifiée plusieurs jours à l'avance, avec suffisamment de temps pour planifier une action corrective sans stress.
Remédiation Autonome et Suggestion d'Actions (AIOps)
L'étape ultime du DevOps Cognitif est l'AIOps (AI for IT Operations), où l'intelligence artificielle ne se contente pas de détecter et de prédire, mais suggère ou exécute des actions correctives. Cela peut aller de la suggestion d'un rollback de déploiement à l'exécution automatique d'un playbook d'autoscaling.
Concrètement, face à une augmentation de la latence, le système AIOps pourrait corréler l'incident avec un déploiement récent, analyser les logs d'erreurs, et présenter à l'opérateur un bouton "Rollback to version 1.2.3", accompagné d'un résumé des raisons de cette suggestion. La décision finale reste humaine, mais elle est éclairée et accélérée par l'IA.
| Approche Manuelle | Approche Assistée par IA (AIOps) |
|---|---|
| Alerte PagerDuty : "Latence API > 500ms" | Notification Slack : "Incident Critique #451 détecté" |
| Connexion aux dashboards Grafana pour analyser les métriques. | L'IA a déjà corrélé 15 alertes en un seul incident. |
| Analyse des logs dans Kibana, recherche manuelle d'erreurs. | La cause racine probable est identifiée : déploiement du service 'auth-api' version 1.2.4. |
| Recherche du dernier déploiement dans Jenkins ou GitLab CI. | L'IA suggère une action : "Rollback vers la version 1.2.3 (stabilité prouvée)" |
| Déclenchement manuel du pipeline de rollback. | L'opérateur valide l'action en un clic. |
| Temps moyen de résolution : 25-45 minutes. | Temps moyen de résolution : 3-5 minutes. |
Ce tableau met en évidence la différence fondamentale : le gain de temps n'est pas marginal, il est exponentiel. Il libère les ingénieurs des tâches répétitives et stressantes pour qu'ils puissent se concentrer sur l'amélioration à long terme de la plateforme.
Les Limites et les Coûts Cachés de l'IA Ops
Cependant, l'adoption du DevOps Cognitif n'est pas une solution magique. Elle comporte des défis importants à ne pas sous-estimer. La première limite est la qualité des données. Un modèle d'IA nourri avec des données d'observabilité de mauvaise qualité ou incomplètes produira des conclusions erronées, menant à une perte de confiance des équipes.
Ensuite, il y a le risque de la "dérive du modèle". Le comportement de votre application et de votre infrastructure évolue constamment. Un modèle d'IA entraîné il y a six mois pourrait ne plus être pertinent aujourd'hui, nécessitant un réentraînement continu et une supervision par des experts en Machine Learning, des compétences qui ne sont pas toujours présentes dans une équipe Ops traditionnelle.
Enfin, le coût d'acquisition et de maintenance de ces plateformes AIOps peut être très élevé. Il est crucial d'intégrer une culture FinOps pour s'assurer que les bénéfices en termes de fiabilité et d'efficacité opérationnelle justifient l'investissement financier. L'IA est un outil puissant, mais son déploiement doit être une décision stratégique et mesurée.
Vers une Collaboration Homme-Machine Intelligente
Le DevOps Cognitif ne signe pas la fin des ingénieurs SRE ou des administrateurs système. Au contraire, il redéfinit leur rôle en les élevant au-dessus des tâches opérationnelles fastidieuses. L'IA devient ce collègue infatigable qui trie, analyse et prépare le terrain, permettant à l'humain de se concentrer sur ce qu'il fait de mieux : la stratégie, l'architecture et l'innovation.
En réduisant la charge cognitive, nous ne faisons pas que rendre nos systèmes plus fiables nous rendons aussi le travail de nos équipes plus durable et plus intéressant. La véritable promesse de cette approche est de transformer la gestion des opérations d'une lutte constante contre le chaos en un partenariat intelligent avec la machine, pour construire les systèmes résilients de demain.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
Gardez en tête que l'IA ne corrigera jamais une architecture mal conçue.
Si votre service est un monolithe qui crash à la moindre montée en charge, aucune couche cognitive ne sauvera vos nuits. L'observabilité précède l'intelligence.
Python reste le standard pour tout ce qui est data et manip de modèles.
Pour les playbooks, utilise des outils qui supportent le typage fort comme Go si tu veux éviter des erreurs de runtime pendant une crise. Voici une structure de base pour gérer une alerte :
Merci pour le retour. Ça donne envie de tester en labo.
Vous avez une reco sur le langage à privilégier pour écrire ces scripts de remédiation ?
La moyenne glissante ne suffit pas pour les pics de charge complexes.
On passe par des modèles type Holt-Winters ou des réseaux de neurones récurrents (LSTM) si la saisonnalité est vraiment chaotique. L'objectif est de définir une
baselinedynamique qui s'adapte au jour de la semaine.La détection de saisonnalité dont tu parles, c'est top.
Vous utilisez quoi comme algo pour ça ? Une simple moyenne glissante ou un truc plus costaud ?
Il faut être agressif sur le
lifecycle management.Tu gardes les données brutes peu de temps, et tu ne conserves que les vecteurs d'entraînement ou les résumés statistiques pour le long terme. Le stockage coûte cher, mais la donnée inutile coûte encore plus cher en frais de requête.
Et niveau coût ?
Stocker des années de logs pour entraîner un modèle, ça coûte une blinde en stockage S3. Vous faites comment pour la rétention ?
Ne code pas ça à la main, c'est une usine à gaz.
Regarde du côté de Thanos ou Cortex pour agrémenter tes données, et des outils comme Prophet pour le forecasting. L'idée c'est de brancher une couche d'analyse au-dessus de tes TSDB existantes plutôt que de remplacer tout ton monitoring.
On utilise déjà Prometheus pour les alertes.
Est-ce qu'il y a des outils open source qui s'intègrent facilement pour faire ce genre de
AnomalyDetectionPolicyou faut tout coder soi-même ?C'est là que l'humain reste indispensable. L'IA propose, l'humain dispose.
Le rôle du co-pilote est de fournir le contexte (le "pourquoi"), pas de prendre la décision finale. Si l'opérateur valide sans vérifier le
diffdu déploiement précédent, c'est un problème de culture, pas de tech.La promesse du 3-5 minutes de résolution est belle sur le papier.
Mais en pratique, qui valide le
rollbacksuggéré par l'IA ? J'ai peur que les équipes deviennent trop dépendantes et valident sans réfléchir.Le parsing est une étape obligatoire, sinon tu injectes du garbage.
Il faut normaliser en JSON structuré dès la sortie du conteneur. Si tu ne forces pas un format standard via tes bibliothèques de logging, ton IA perdra 80% de sa pertinence. Voici un exemple de ce qu'on attend idéalement :
J'aime l'idée de corréler les logs avec l'infra, mais comment vous gérez la formatage des logs pour que l'IA y comprenne quelque chose ?
J'ai des microservices en Go, Python et Java, c'est le bordel total dans les formats.
Ne fais jamais tourner ton moteur d'IA sur le même cluster que ta prod si tu as peur de la contention de ressources.
Utilise un exporteur déporté qui envoie tes données vers une instance dédiée. Sinon, tu finis par avoir l'IA qui crashe ton monitoring au moment précis où il y a un pic de charge, c'est l'effet boomerang garanti.
Sympa l'exemple de la
linear_regression_forecastpour le disque.Mais concrètement, on installe quoi comme stack pour supporter ça sur un cluster Kubernetes déjà bien chargé sans exploser la consommation CPU ?
C'est le point critique. Si ton modèle est statique, il meurt en une semaine.
Il faut impérativement coupler ton pipeline de déploiement avec le réentraînement du modèle. Si tu ne fais pas de
retrainingautomatique basé sur les nouvelles signatures de métriques après un déploiement, tu vas juste polluer ton Slack avec du bruit.Article intéressant, mais je reste sceptique sur la gestion de la dérive des modèles.
Dans un environnement qui bouge avec des déploiements quotidiens, comment on évite que l'IA ne devienne un générateur de faux positifs dès qu'on change une version de librairie ?