Pourquoi votre code rapide est-il si lent en production ?

Vous venez de passer trois jours à optimiser la complexité algorithmique de votre binaire. Sur le papier, votre algorithme est parfait, pourtant, une fois déployé sur vos serveurs de production, les temps de réponse s'effondrent dès que la charge augmente. La raison de ce désastre ne réside pas dans votre logique métier, mais dans l'ignorance d'une barrière matérielle impitoyable : les cache misses du processeur.
Pendant que votre CPU attend désespérément que la mémoire vive lui fournisse les données nécessaires à ses calculs, il tourne à vide, gâchant de précieux cycles d'exécution. Nous allons explorer les profondeurs de l'architecture matérielle moderne pour comprendre comment restructurer vos structures de données et éliminer ce goulot d'étranglement invisible.
L'architecture mémoire moderne : Du silicium aux registres
Pour comprendre l'origine du problème, il faut remonter à la conception physique de nos ordinateurs. La vitesse de calcul des processeurs a augmenté de manière exponentielle, tandis que le temps d'accès à la mémoire vive (RAM) n'a progressé que très lentement. Pour combler ce fossé abyssal, les fondeurs ont intégré de petites mémoires ultra-rapides directement sur la puce de silicium : les caches CPU.
La pyramide de la mémoire et la dure réalité physique
Imaginez que le processeur est un artisan travaillant à son bureau. Les registres du CPU représentent les outils qu'il a directement en main, accessibles instantanément en moins d'un cycle d'horloge. Le cache L1, divisé en instructions et données, correspond aux outils posés sur son plan de travail, accessibles en quelques cycles.
Le cache L2 et le cache L3 partagé représentent respectivement un tiroir sous le bureau et une armoire de rangement située dans la même pièce. Enfin, la mémoire RAM équivaut à un entrepôt situé à l'autre bout de la ville : chaque trajet pour y récupérer un composant interrompt le travail de l'artisan pendant un temps interminable.
Lorsqu'un processeur exécute une instruction nécessitant une donnée en mémoire, il interroge d'abord les différents niveaux de cache. Si la donnée y est présente, c'est un Cache Hit. Si elle est absente, c'est un cache miss, forçant le processeur à suspendre son exécution en attendant que la donnée soit rapatriée depuis la RAM, un processus qui peut prendre jusqu'à plusieurs centaines de cycles d'horloge.
Les exigences du noyau Linux pour l'analyse d'accès mémoire
Pour observer ces phénomènes physiques depuis l'espace utilisateur, le système d'exploitation doit collaborer étroitement avec le processeur. Le noyau Linux s'appuie sur le sous-système perf_events pour exposer les compteurs de performance matériels du processeur.
Ces compteurs sont des registres physiques spécifiques intégrés dans le processeur qui s'incrémentent automatiquement à chaque événement matériel, comme un accès mémoire ou un défaut de cache. Pour y accéder sans privilèges restrictifs, la configuration système doit autoriser l'accès aux compteurs matériels via le paramètre sysctl approprié.
sudo sysctl -w kernel.perf_event_paranoid=1Configuration Persistante
Pour rendre ce réglage permanent après un redémarrage, ajoutez la ligne kernel.perf_event_paranoid = 1 dans le fichier de configuration système /etc/sysctl.conf.
Sous le capot : Le mécanisme du Cache Miss
Le transfert de données entre la mémoire principale et les caches ne se fait pas octet par octet. Comprendre cette mécanique fine est indispensable pour concevoir du code haute performance qui respecte le fonctionnement interne du matériel.
Lignes de cache et localité spatio-temporelle
Lorsque le processeur lit une variable en mémoire, il rapatrie systématiquement un bloc entier de données contiguës, généralement d'une taille fixe de 64 octets. Ce bloc indivisible est appelé une ligne de cache. Ce mécanisme repose sur le principe de la localité spatiale : si vous accédez à un élément en mémoire, il est hautement probable que vous accédiez très bientôt aux données situées juste à côté.
Le principe de localité temporelle stipule quant à lui qu'une donnée récemment consultée a de fortes chances d'être réutilisée à court terme. C'est pourquoi le CPU maintient ces lignes de cache actives le plus longtemps possible, éliminant les plus anciennes selon des algorithmes de remplacement stricts.
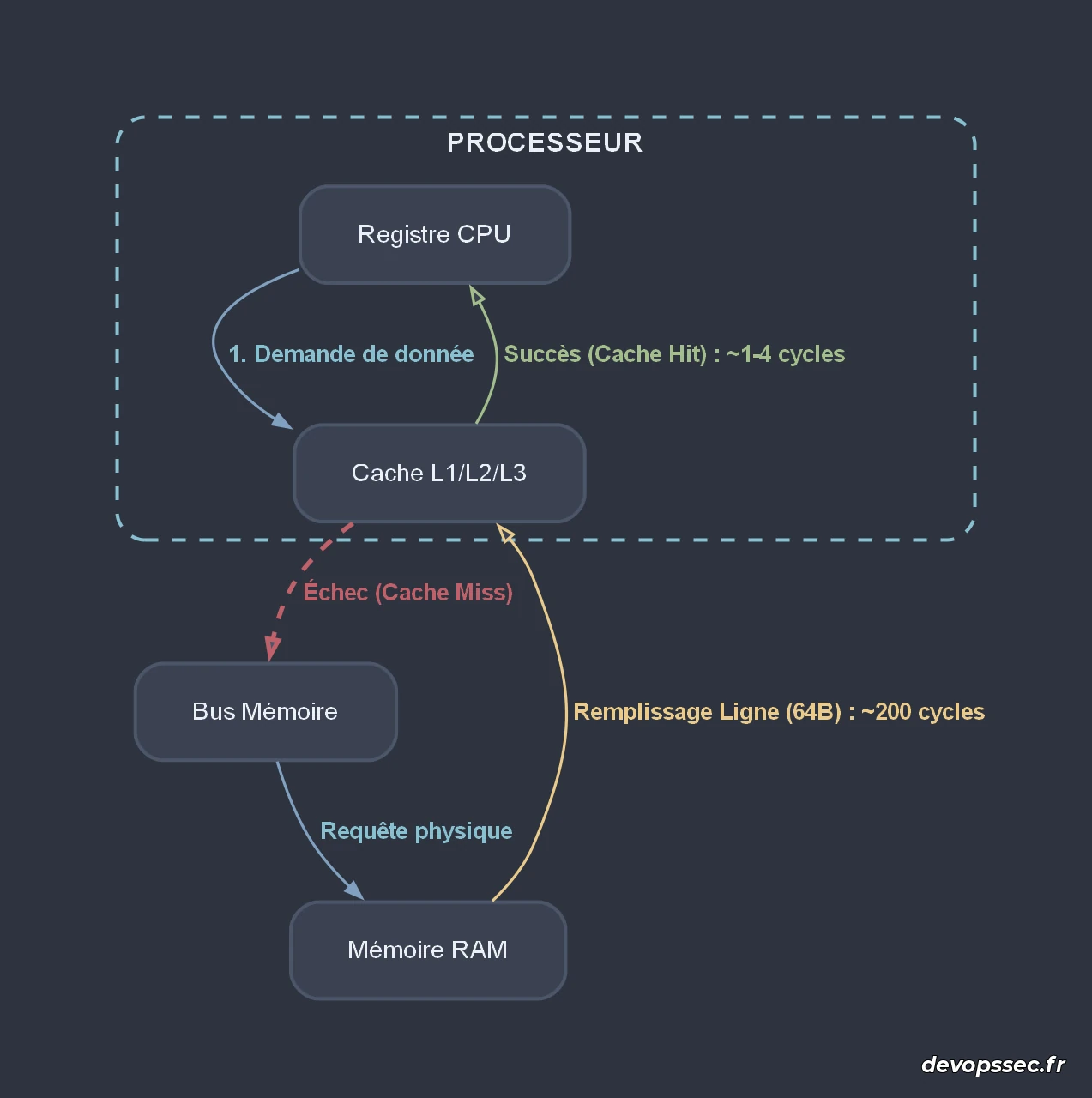
Ce schéma illustre la différence drastique de cheminement entre un accès réussi et un accès manqué. Alors que le cycle nominal de lecture de données au sein des caches du processeur s'exécute de manière quasi instantanée en tâche de fond, la survenue d'une panne de cache force la requête à traverser le bus de communication pour interroger physiquement les puces de mémoire vive, bloquant temporairement le thread d'exécution.
Optimiser son code pour le CPU : Cache-Friendly Design
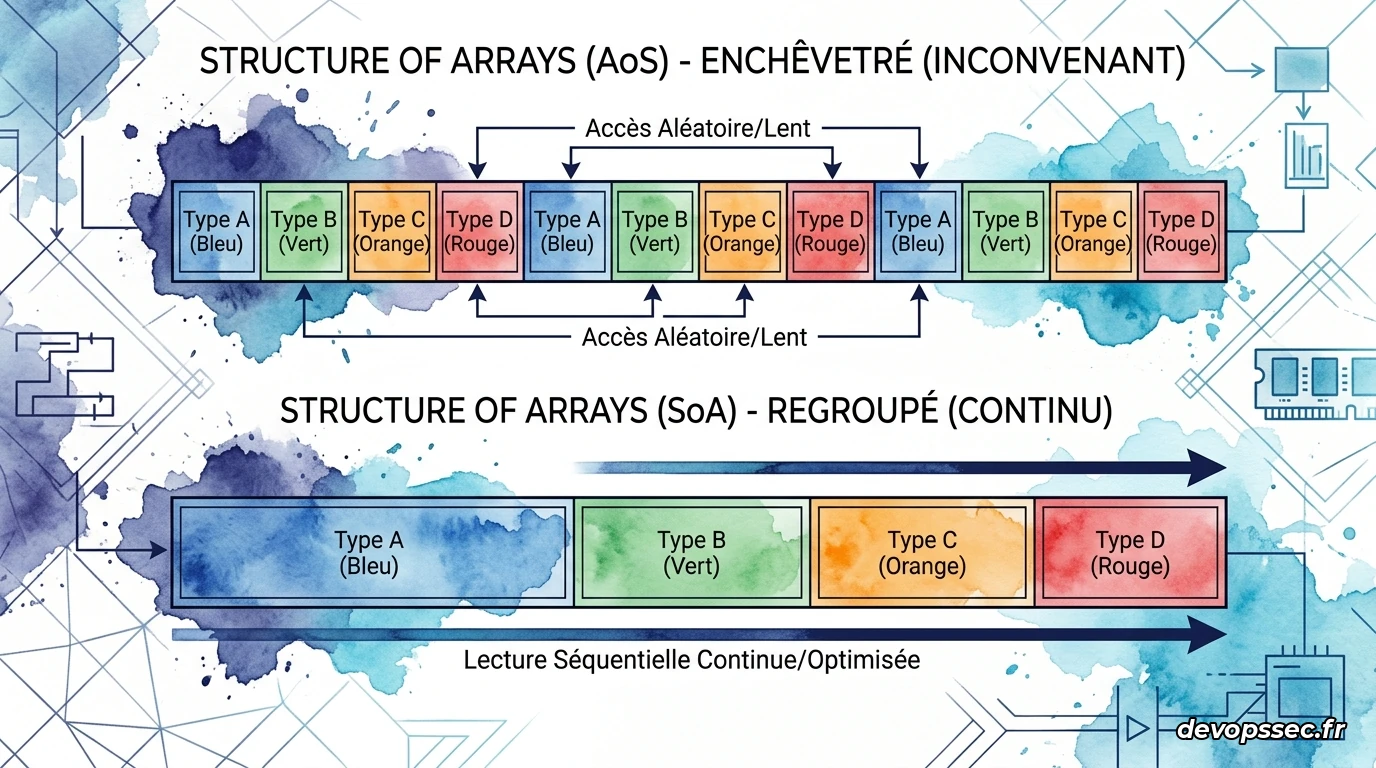
La manière dont vous organisez vos structures de données en mémoire dicte directement le taux d'efficacité de vos caches. Pour maximiser la vitesse de traitement de gros volumes d'informations, l'approche traditionnelle de la programmation orientée objet doit parfois être réévaluée.
La confrontation : Array of Structures (AoS) vs Structure of Arrays (SoA)
La plupart des développeurs juniors ont l'habitude de concevoir des objets regroupant l'ensemble des attributs d'une entité, puis de manipuler un tableau contenant ces objets. C'est le modèle Array of Structures (AoS). Si vous devez parcourir ce tableau pour mettre à jour un seul attribut spécifique de chaque entité, le processeur chargera inutilement en cache tous les autres attributs adjacents de chaque structure, saturant la bande passante pour rien.
À l'inverse, l'approche Structure of Arrays (SoA) consiste à séparer chaque attribut dans son propre tableau contigu. Ainsi, si vous souhaitez lire uniquement les coordonnées de vos entités, vous lisez un tableau de données pures, compactes et parfaitement alignées avec vos lignes de cache. Chaque octet transféré depuis la RAM est alors utile pour votre calcul.
Cas d'usage concret et benchmark d'implémentation
Mettons ce concept en pratique avec une implémentation comparative de traitement de données géographiques. Nous allons analyser deux structures de données distinctes pour effectuer un calcul de mise à jour de coordonnées sur un ensemble massif d'entités.
package main
import (
"fmt"
"testing"
)
const size = 1000000
// Structure traditionnelle (Array of Structures - AoS)
type NodeAoS struct {
Latitude float64
Longitude float64
ID int64
Name [32]byte
Active bool
}
// Structure optimisée (Structure of Arrays - SoA)
type NodesSoA struct {
Latitudes []float64
Longitudes []float64
IDs []int64
Names [][32]byte
Actives []bool
}
func BenchmarkAoS(b *testing.B) {
nodes := make([]NodeAoS, size)
for i := 0; i < size; i++ {
nodes[i].Latitude = float64(i)
nodes[i].Longitude = float64(i * 2)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
for j := 0; j < size; j++ {
nodes[j].Latitude += 0.5
}
}
}
func BenchmarkSoA(b *testing.B) {
nodes := NodesSoA{
Latitudes: make([]float64, size),
Longitudes: make([]float64, size),
}
for i := 0; i < size; i++ {
nodes.Latitudes[i] = float64(i)
nodes.Longitudes[i] = float64(i * 2)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
for j := 0; j < size; j++ {
nodes.Latitudes[j] += 0.5
}
}
}Dans l'exemple de l'AoS, chaque structure NodeAoS occupe plus de 50 octets en mémoire à cause des champs inutilisés lors du calcul de mise à jour, comme le nom ou l'identifiant. Lorsque le CPU charge une ligne de cache de 64 octets, il ne peut y loger qu'un seul élément à la fois. Dans l'exemple SoA, le tableau de latitudes est stocké de manière contiguë sous la forme d'une série de valeurs de type float64 de 8 octets. Une seule ligne de cache de 64 octets contient alors exactement 8 latitudes prêtes à être traitées à la suite, multipliant l'efficacité d'accès par huit.
Mesurer l'invisible : Profiler avec perf sur Linux
Vous ne pouvez pas optimiser ce que vous ne mesurez pas. Le diagnostic des défauts d'accès mémoire nécessite l'usage d'outils d'analyse de bas niveau capables de sonder l'activité physique de votre processeur lors de l'exécution d'une commande.
L'outil perf pour analyser les événements matériels
L'utilitaire d'analyse de performances de Linux perf permet d'interroger les compteurs matériels de performance. En ciblant spécifiquement les événements liés aux lectures et aux échecs d'accès au cache de dernier niveau, vous pouvez diagnostiquer instantanément si votre application souffre de problèmes de disposition de données en mémoire.
perf stat -e cache-references,cache-misses,L1-dcache-loads,L1-dcache-load-misses ./my_app_binaryRésultat:
Performance counter stats for './my_app_binary':
312,450,112 cache-references
45,891,204 cache-misses # 14.688 % of all cache refs
1,452,109,832 L1-dcache-loads
98,410,211 L1-dcache-load-misses # 6.777 % of all L1-dcache accesses
1.854311204 seconds time elapsedDans ce rapport de diagnostic, nous constatons un taux de cache-misses de près de 15% sur le cache global. Pour une application critique traitant des flux de données en continu, un tel pourcentage indique qu'une part massive du temps CPU est gaspillée dans des cycles d'attente d'accès mémoire, ce qui confirme l'importance d'adopter une stratégie de conception de données plus respectueuse des contraintes matérielles.
Dompter le hardware pour libérer le software
Le développement de logiciels hautement performants ne s'arrête pas à l'écriture d'un code élégant ou au choix d'un algorithme théoriquement optimal. Les limites de la physique et de la conception matérielle de nos serveurs s'imposeront toujours à l'exécution de nos programmes.
En apprenant à structurer vos types de données pour favoriser les lectures contiguës, en favorisant les structures de tableaux plutôt que les enchaînements de pointeurs éparpillés en mémoire, vous offrez à votre processeur les conditions idéales pour exprimer toute sa puissance. Prenez l'habitude de profiler vos binaires de production avec des outils système performants : c'est l'unique moyen de déceler ces tueurs silencieux et de garantir des performances de classe mondiale.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
28 commentaires
Comment tu gères le cas où t'as besoin de manipuler l'objet complet dans ta boucle ? Le
SoAdevient un enfer à maintenir.Le compilateur fait des miracles, mais il ne peut pas deviner l'accès futur à tes structures de données. Le gain est massif sur les gros datasets.
Sur du traitement de signal ou de la géo, on passe souvent d'un CPU bound à un throughput mémoire bien plus efficace. C'est surtout visible sur la latence P99.
Article intéressant. J'ai toujours cru que le compilateur gérait ça tout seul, mais je vois que le layout mémoire en
AoSvsSoAchange radicalement la donne.C'est quoi le gain réel en prod sur une grosse stack ?