DevOps Agentique : L'Ère des Systèmes Autonomes Intelligents
Vous avez certainement déjà scripté une pipeline CI/CD, automatisé un déploiement sur Kubernetes ou même configuré des alertes complexes. Mais imaginez un instant que ces systèmes ne se contentent plus d'exécuter des ordres, mais qu'ils prennent des décisions, anticipent les pannes et s'auto-corrigent en temps réel. Bienvenue dans l'ère du DevOps Agentique, une évolution où l'automatisation cède la place à l'autonomie.
Ce n'est plus de la science-fiction. C'est la nouvelle frontière de notre métier, une transformation profonde qui redéfinit la manière dont nous concevons, livrons et maintenons les infrastructures logicielles. Oubliez les scripts rigides et les workflows manuels, nous parlons désormais d'écosystèmes intelligents qui collaborent pour garantir la résilience et la performance.
Qu'est-ce qu'un Agent DevOps ? Au-delà de l'Automatisation
L'automatisation, telle que nous la connaissons, est fondamentalement réactive. Un script s'exécute en réponse à un déclencheur, comme un commit Git ou une alerte de monitoring. Un agent DevOps, lui, est une entité logicielle dotée d'une intelligence propre, capable d'agir de manière proactive et autonome pour atteindre un objectif défini.
Pensez à un agent non pas comme un outil, mais comme un membre de votre équipe. Il n'attend pas qu'un seuil de CPU soit dépassé pour réagir il analyse les tendances, prédit la charge future en se basant sur les événements du calendrier marketing et décide de provisionner de nouvelles ressources avant même que l'incident ne se produise. C'est là toute la différence : passer d'une logique de "si ceci, alors faire cela" à une approche "voici l'objectif, trouve la meilleure façon de l'atteindre".
Les Piliers de l'Intelligence Agentique
Pour qu'un système soit véritablement agentique, il doit reposer sur plusieurs principes fondamentaux qui le distinguent radicalement d'un simple pipeline automatisé. Ces piliers ne sont pas optionnels ils constituent l'ADN même de ces Systèmes Autonomes.
La collaboration entre agents est également cruciale. Un agent de sécurité qui détecte une vulnérabilité ne se contente pas de créer un ticket. Il communique directement avec l'agent de déploiement pour initier un rollback contrôlé et avec l'agent de test pour déclencher une nouvelle suite de scans sur la version précédente, formant une véritable intelligence collective.
| Caractéristique | Automatisation Classique (Script) | Système Agentique (Agent IA) |
|---|---|---|
| Autonomie | Exécute des tâches prédéfinies. Nécessite une intervention humaine pour les cas non prévus. | Prend des décisions indépendantes pour atteindre des objectifs. S'adapte aux situations nouvelles. |
| Apprentissage | Statique. Le comportement ne change pas sans mise à jour du code. | Dynamique. Apprend des incidents passés (logs, métriques) pour améliorer ses futures décisions. |
| Proactivité | Réagit à des événements (triggers). | Anticipe les problèmes en analysant les signaux faibles et les tendances. |
| Conscience du contexte | Opère en silo, sans vision globale du système. | Intègre des données de sources multiples (observabilité, Git, outils métier) pour une décision éclairée. |
Anatomie d'un Workflow DevOps Gouverné par des Agents
Pour mieux comprendre comment ces agents interagissent, visualisons un flux de déploiement complet. Un développeur pousse son code, et à partir de là, l'écosystème agentique prend le relais. Chaque agent a une spécialité, mais tous partagent un contexte commun et communiquent en permanence.
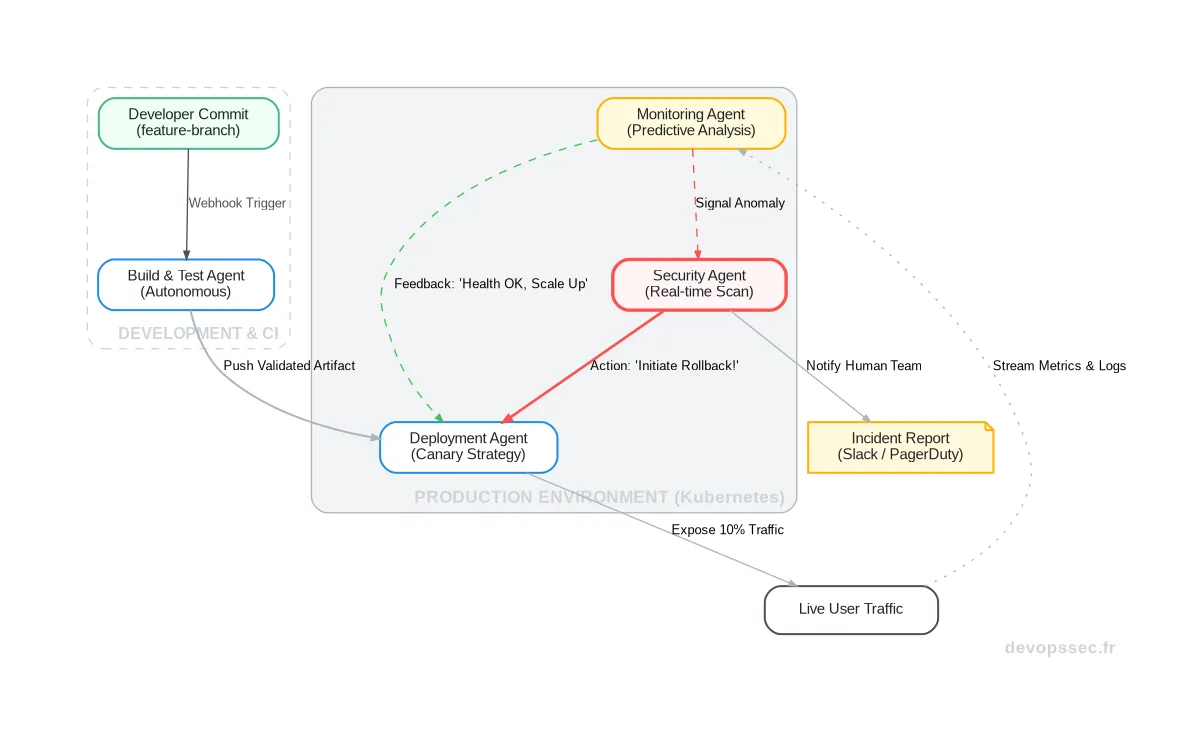
Ce schéma illustre parfaitement l'Intelligence Collective à l'œuvre. Le commit d'un développeur déclenche l'Agent de Build. S'il valide les tests, il ne se contente pas de passer le relais : il transmet un artefact enrichi de métadonnées (couverture de code, dépendances) à l'Agent de Déploiement. Ce dernier, conscient du contexte, choisit une stratégie de déploiement canari, exposant la nouvelle version à une fraction du trafic.
C'est là que la magie opère. L'Agent de Monitoring n'attend pas une alerte. Il analyse en continu les signaux (latence, taux d'erreur) et communique son analyse à l'Agent de Déploiement. Si les indicateurs sont bons, il lui donne le feu vert pour augmenter le trafic. S'il détecte une anomalie, il alerte l'Agent de Sécurité qui, après une analyse instantanée, peut ordonner un rollback immédiat, le tout en quelques secondes, avant même qu'un humain n'ait eu le temps de lire la notification.
Mettre en place son premier écosystème d'agents
L'idée peut sembler intimidante, mais commencer avec le DevOps agentique est plus accessible qu'on ne le pense. Il ne s'agit pas de remplacer tout votre système du jour au lendemain, mais d'introduire progressivement des agents pour des tâches spécifiques et bien définies. Un excellent point de départ est la gestion d'un déploiement progressif, comme le "canary release".
Définir le comportement d'un Agent de Déploiement
La configuration d'un agent se fait souvent via des fichiers déclaratifs, comme le YAML, où l'on ne décrit pas les étapes mais les objectifs, les contraintes et les sources de données à surveiller. C'est une approche centrée sur l'intention (Intent-Based).
Voici un exemple conceptuel de la définition d'un agent chargé de gérer un déploiement canari. Notez comment on définit des objectifs (goal) et des conditions de succès (success_criteria) plutôt qu'une suite d'instructions impératives.
agent:
name: canary-deployer-api-main
type: DeploymentAgent
# L'objectif que l'agent doit atteindre
goal: "Safely deploy version {{ new_version }} to 100% of traffic"
# Les sources de données que l'agent doit observer
observability_sources:
- provider: prometheus
endpoint: "http://monitoring.svc.cluster.local"
query: 'rate(http_requests_total{status_code=~"5.*"}[5m])'
- provider: fluentd
source: "logs-api-main"
# Les étapes et conditions de la stratégie
strategy:
- name: "Initial Rollout"
action: "set_traffic_weight"
target: "api-main-v2"
value: "10%"
duration: "5m"
- name: "Health Evaluation"
action: "evaluate_health"
success_criteria:
- metric: "prometheus_error_rate"
condition: "less_than"
threshold: "1%"
- metric: "p99_latency"
condition: "less_than"
threshold: "250ms"
- name: "Progressive Scale-Up"
action: "set_traffic_weight"
target: "api-main-v2"
value: "50%"
# Conditionne cette étape au succès de la précédente
depends_on: "Health Evaluation"
# Action à prendre en cas d'échec d'un critère
failure_policy:
action: "rollback"
target: "previous_stable_version"
notify: "#alerts-channel"Les limites et les risques à ne pas négliger
L'autonomie est puissante, mais elle comporte sa part de risques. Un écosystème d'agents mal configuré ou basé sur des données de mauvaise qualité peut prendre des décisions catastrophiques à une vitesse fulgurante. Le débogage d'une décision prise par une "boîte noire" IA peut s'avérer complexe.
La sécurité est une autre préoccupation majeure. Si un agent est compromis, il pourrait recevoir des ordres malveillants ou exfiltrer des données sensibles. La gestion des permissions et l'audit des actions de chaque agent deviennent donc des disciplines absolument critiques pour éviter les dérives.
Le Paradoxe de l'Observabilité
Plus vos systèmes deviennent autonomes, plus l'Observabilité Proactive devient cruciale. Vous ne monitorez plus seulement pour réagir aux pannes, mais pour comprendre et valider les décisions de vos agents. Investir dans des plateformes qui corrèlent les logs, les métriques et les traces n'est plus un luxe, c'est une nécessité pour maintenir la confiance dans le système.
Enfin, il y a le coût caché. L'inférence des modèles d'IA, l'analyse constante des flux de données et la communication inter-agents consomment des ressources de calcul non négligeables. Une surveillance fine de ces coûts est indispensable pour garantir que le gain d'efficacité opérationnelle ne soit pas annulé par une explosion de la facture cloud.
Conclusion : Votre Rôle en tant qu'Architecte de Systèmes Intelligents
Le DevOps agentique ne signe pas la fin de l'ingénieur DevOps, bien au contraire. Il fait évoluer notre rôle de "faiseurs" à celui d'architectes, de formateurs et de superviseurs de systèmes intelligents. Notre mission n'est plus de scripter chaque étape, mais de définir les objectifs, de fixer les garde-fous et d'enseigner aux agents à bien se comporter.
En libérant les équipes des tâches opérationnelles répétitives, cette nouvelle approche nous permet de nous concentrer sur ce qui a le plus de valeur : l'innovation, l'optimisation de l'architecture et la stratégie à long terme. C'est une opportunité unique de monter en compétence et de devenir le chef d'orchestre d'une symphonie technologique autonome et résiliente.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
L'inférence doit être locale au cluster. Évite les appels API externes pour chaque décision. Utilise des modèles légers déployés en sidecar ou via un service interne dédié.
Le temps de réponse doit être inférieur à la seconde pour être utile en cas de crash.
Des retours sur la latence de décision ? Si l'agent met 30s à analyser les métriques avant de décider, c'est trop tard.
@9 : C'est exactement ça. Plus ton système est autonome, plus tu dois investir dans une stack d'observabilité béton.
Si tu ne peux pas expliquer pourquoi l'agent a pris une décision, tu ne maîtrises plus ton infra.
Le paradoxe de l'observabilité mentionné est super pertinent. On finit par monitorer le moniteur.
Est-ce qu'on peut utiliser ça pour gérer le scaling horizontal sur des clusters hybrides ?
Il faut traiter les décisions comme des logs d'audit immuables. Chaque action de l'agent doit être loggée avec son état initial et la raison de la décision.
Par exemple :
C'est bien beau les agents, mais si le modèle s'auto-corrompt avec des données de logs pourries, c'est irrécupérable. On a des outils pour auditer les décisions de l'agent ?
@6 : On utilise des headers de contexte propagés dans toutes les requêtes. L'agent injecte un
X-Canary-Agent-IDpour identifier les flux générés par ses tests.Ça permet à ton back-end d'exclure ces données des dashboards de prod classique.
J'ai bien aimé la partie sur le
canary-deployer-api-main. Vous gérez comment la corrélation des traces quand l'agent fait des tests ?La notion d'intelligence collective entre agents me fait peur. Si un agent de monitoring envoie une info erronée, l'agent de déploiement va se planter en boucle sans comprendre pourquoi.
@4 : Tu ne dois jamais envoyer le flux brut ! Il faut faire un pré-traitement local, par exemple avec un agrégateur qui ne pousse vers l'IA que les anomalies détectées.
Utilise un workflow de ce genre pour filtrer :
J'ai testé un setup similaire avec des agents basés sur des LLM pour analyser les logs. Le problème c'est le coût des tokens si tu envoies tout le flux en temps réel.
@3 : Exact. Il faut isoler les agents dans des namespaces dédiés avec des
ServiceAccountrestreints au strict minimum via RBAC.Ne jamais donner de droits globaux à un agent. Tu appliques le principe du moindre privilège, comme pour n'importe quel humain.
Grosse question sur la sécurité aussi. Si on donne à l'agent des droits d'écriture sur le cluster pour faire du
kubectl apply, il devient la cible numéro 1 pour une élévation de privilèges.L'approche déclarative dans le YAML est propre, ça rappelle un peu le fonctionnement de Kubernetes. Par contre, comment on gère la persistance de l'état si l'agent crash ?
C'est le point critique. Le but n'est pas de laisser l'IA en roue libre totale. Tu définis des garde-fous stricts dans ton fichier de config.
Si l'agent dépasse un certain seuil de décisions automatiques, tu peux forcer un mode
manual-override. C'est pas une boîte noire, c'est un système expert avec des limites hardcodées.Encore une énième couche d'abstraction qui va finir par rendre le debug impossible. Quand ton agent décide de rollback tout seul en plein pic de trafic à cause d'une latence réseau temporaire, tu fais comment pour reprendre la main ?