Comprendre le comportement de l'OOMKilled et configurer son environnement de diagnostic
Le scénario est classique mais redoutable : votre application en production fonctionne parfaitement pendant plusieurs heures, puis disparaît soudainement sans laisser la moindre trace d'erreur dans ses propres fichiers de logs. Quelques secondes plus tard, la plateforme de conteneurisation Kubernetes recrée un nouveau processus identique, laissant votre équipe d'exploitation face à une énigme technique récurrente.
L'anatomie d'un crash Out-Of-Memory
Lorsqu'un conteneur dépasse la limite de mémoire physique qui lui a été attribuée, le système d'exploitation applique une mesure d'urgence radicale. C'est le mécanisme appelé OOMKilled, déclenché par le gestionnaire de ressources du noyau Linux. Pour comprendre ce phénomène, on peut imaginer le système d'exploitation comme le videur d'une boîte de nuit surpeuplée : dès que l'espace disponible est saturé, il expulse immédiatement l'invité le plus bruyant et le plus volumineux sans aucune négociation préalable pour éviter l'effondrement de tout l'établissement.
Sous le capot, le noyau Linux utilise les mécanismes de groupes de contrôle nommés cgroups v2 pour surveiller l'empreinte mémoire de chaque processus isolé. Dès que la frontière étanche de la ressource allouée est franchie, le signal système standard d'arrêt immédiat, le fameux signal d'arrêt forcé avec le code d'erreur 137, est envoyé au processus principal du conteneur.
Mise en place de l'environnement de diagnostic
Pour reproduire et analyser ce comportement de manière rigoureuse, nous allons déployer une application de démonstration écrite en Node.js qui simule une dérive d'allocation mémoire progressive. Avant de commencer, assurez-vous de disposer d'un accès à un cluster Kubernetes opérationnel et de l'utilitaire d'administration en ligne de commande kubectl installé localement.
Voici le descripteur de déploiement initial de notre application défaillante à enregistrer sous le nom de fichier diagnostic-deployment.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: leaky-app-deployment
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: leaky-app
template:
metadata:
labels:
app: leaky-app
spec:
containers:
- name: memory-consumer
image: node:20-alpine
command: ["node"]
args: ["-e", "const list = []; setInterval(() => { for (let i = 0; i < 10000; i++) { list.push({ data: Math.random() }); } console.log('RAM utilisable estimée:', Math.round(process.memoryUsage().heapUsed / 1024 / 1024), 'MB'); }, 100);"]
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "200m"Analysons en détail les paramètres clés de cette configuration de diagnostic :
- image: node:20-alpine : Nous utilisons une version allégée et stable de l'environnement d'exécution pour limiter l'empreinte de base du système d'exploitation hôte.
- resources.requests.memory : Fixé à 128 Mégasecteurs (Mi), il s'agit de la quantité de mémoire vive minimale garantie par le planificateur de Kubernetes lors du placement initial du conteneur sur un nœud physique du cluster.
- resources.limits.memory : Positionné à 256 Mégasecteurs (Mi), ce paramètre définit la barrière absolue au-dessus de laquelle le système d'exploitation hôte activera immédiatement le processus de destruction du conteneur si la consommation d'espace de stockage temporaire est franchie.
La configuration initiale pour identifier la dérive
Une fois notre environnement de test déployé, nous devons apprendre à observer et valider scientifiquement la survenue de l'incident d'allocation mémoire avant de pouvoir y remédier efficacement.
Observation du cycle de vie du conteneur
Déployez l'application de test en exécutant la commande d'application dans votre terminal :
kubectl apply -f diagnostic-deployment.yamlSurveillons maintenant en temps réel les changements d'état de notre pod d'expérimentation grâce à la commande de surveillance continue suivante :
kubectl get pods -wRésultat:
NAME READY STATUS RESTARTS AGE
leaky-app-deployment-6dfbd8cbf7-p5nzs 1/1 Running 0 5s
leaky-app-deployment-6dfbd8cbf7-p5nzs 1/1 Running 0 15s
leaky-app-deployment-6dfbd8cbf7-p5nzs 0/1 OOMKilled 1 25sLe statut du pod bascule brusquement vers l'état redouté. Pour confirmer l'origine exacte du dysfonctionnement physique de notre conteneur, nous devons interroger les événements enregistrés au sein du moteur d'orchestration de conteneurs.
Extraction des métadonnées système d'erreur
Exécutez la commande d'inspection détaillée du pod concerné afin d'analyser son historique d'exécution récent :
kubectl describe pod leaky-app-deployment-6dfbd8cbf7-p5nzsRésultat:
Containers:
memory-consumer:
Container ID: containerd://e926a798b31a
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Mon, 12 May 14:02:10 +0200
Finished: Mon, 12 May 14:02:35 +0200
State: Running
Started: Mon, 12 May 14:02:36 +0200
Ready: True
Restart Count: 1L'indicateur Exit Code: 137 confirme de manière irréfutable que le système d'exploitation a détruit de force notre application à cause d'un dépassement de la limite de mémoire maximale autorisée de 256 Mi spécifiée dans le descripteur.
Attention à la perte d'informations de diagnostic
Lorsqu'un conteneur subit une destruction forcée, toutes les informations temporaires stockées en mémoire vive volatile et les fichiers locaux non persistés de l'application sont définitivement perdus, rendant l'analyse post-mortem impossible sans préparation adéquate.
L'implémentation robuste et résiliente en production
Pour empêcher les interruptions de service en conditions réelles, l'application doit coopérer intelligemment avec l'orchestrateur. Le Garbage Collector (ou ramasse-miettes) d'un langage de programmation fonctionne comme un service de nettoyage municipal : si vous ne l'informez pas des limites de la ville, il risque de laisser les déchets s'accumuler en pensant disposer d'un espace infini.
La configuration alignée avec l'environnement d'exécution
Nous allons concevoir un descripteur de déploiement hautement résistant destiné aux environnements de production. Cette configuration applique de bonnes pratiques indispensables : l'utilisation de variables d'environnement pour guider la machine virtuelle applicative et la définition de sondes d'activité rigoureuses.
Enregistrez la configuration avancée suivante sous le nom production-deployment.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: resilient-node-app
namespace: default
labels:
tier: api
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: resilient-node-app
template:
metadata:
labels:
app: resilient-node-app
spec:
securityContext:
runAsNonRoot: true
runAsUser: 10001
containers:
- name: api-server
image: node:20-alpine
command: ["node"]
args: ["--max-old-space-size=180", "server.js"]
env:
- name: NODE_ENV
value: "production"
resources:
requests:
memory: "192Mi"
cpu: "200m"
limits:
memory: "256Mi"
cpu: "400m"
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 15
timeoutSeconds: 3
failureThreshold: 3Voici les explications détaillées des paramètres critiques de cette architecture hautement disponible :
- --max-old-space-size=180 : Cette option cruciale indique à la machine virtuelle JavaScript qu'elle doit démarrer le cycle de nettoyage complet de la mémoire vive dès que l'usage de la mémoire allouée atteint 180 Mégaoctets, garantissant ainsi qu'elle restera toujours en dessous de notre limite matérielle stricte de 256 Mi.
- strategy.rollingUpdate : Garantit une transition fluide sans aucune interruption d'accès pour les utilisateurs en veillant à ce qu'aucune instance active ne soit désactivée avant qu'une nouvelle version saine ne soit pleinement opérationnelle.
- livenessProbe : La sonde de viabilité interroge l'application toutes les 15 secondes pour s'assurer qu'elle répond correctement. Si le conteneur s'avère bloqué à cause d'une saturation de ses ressources de calcul internes, Kubernetes se chargera de le redémarrer proprement de manière proactive.
Visualisation de la dynamique d'allocation de mémoire
Le schéma ci-dessous illustre comment les différents composants de notre infrastructure interagissent lorsque la charge applicative s'intensifie et menace de saturer l'espace mémoire alloué.
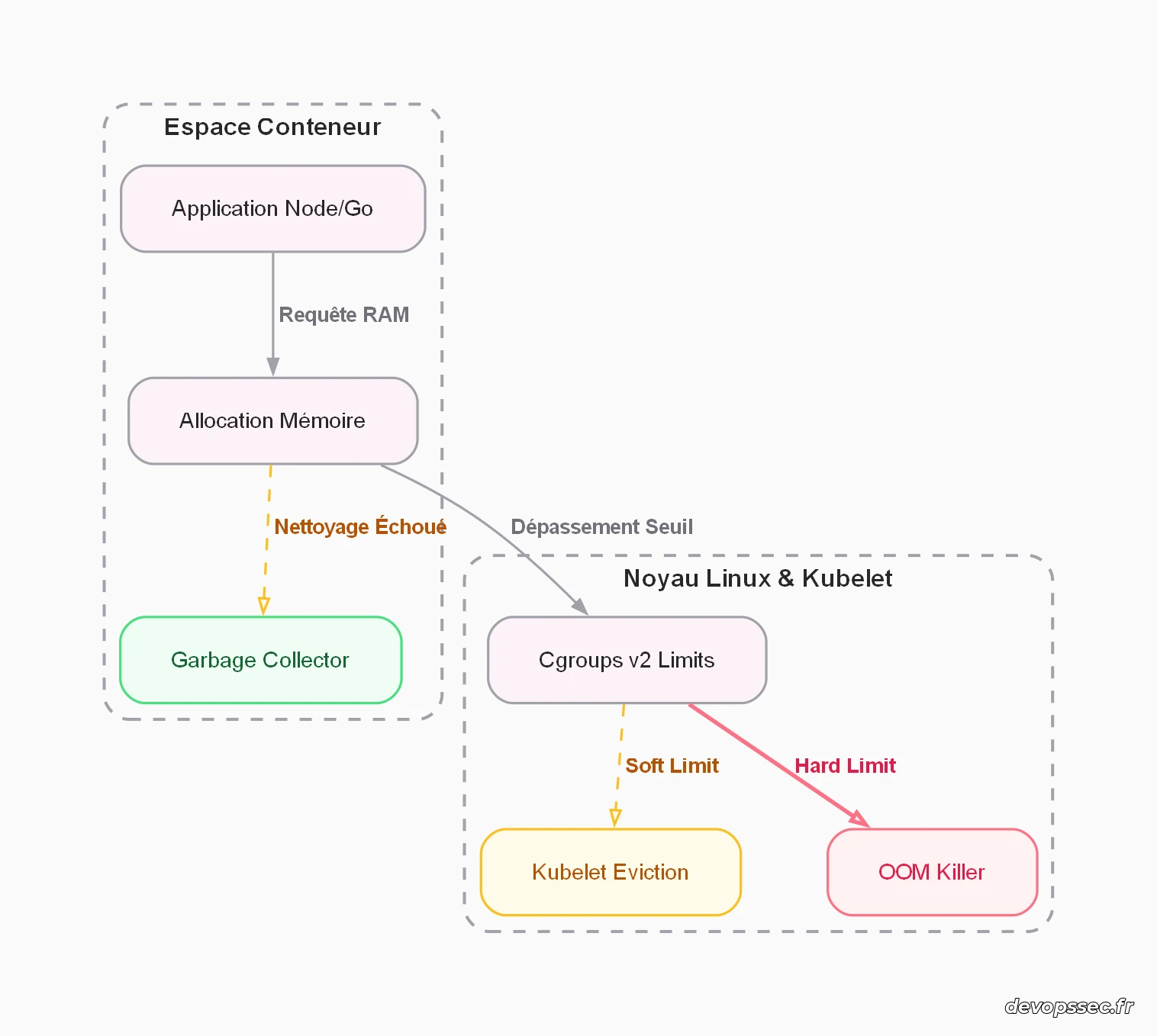
Ce graphique montre clairement que si le Garbage Collector ne parvient pas à libérer de l'espace rapidement, l'allocation dépasse les seuils définis. Le système d'exploitation, via l'implémentation de cgroups v2, va alors arbitrer la situation : soit la Kubelet initie une expulsion douce du conteneur en cas d'atteinte de la limite tolérable temporaire, soit le mécanisme de destruction physique du noyau Linux s'active immédiatement pour stopper la dérive du processus applicatif.
Mise en place d'une détection proactive
Pour ne plus subir les coupures inattendues de vos pods de production, il convient de surveiller activement le rythme de croissance de l'utilisation des ressources mémoire en s'appuyant sur le puissant langage d'interrogation PromQL de l'outil Prometheus.
Voici la règle de détection d'anomalie dynamique à configurer au sein de votre système de supervision globale :
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: memory-leak-detection-rules
namespace: monitoring
spec:
groups:
- name: application-memory-alerts
rules:
- alert: PodMemoryLeakPredicted
expr: predict_linear(container_memory_working_set_bytes{container="api-server"}[1h], 14400) > container_spec_memory_limit_bytes{container="api-server"}
for: 15m
labels:
severity: warning
annotations:
summary: "Fuite de mémoire suspectée sur le pod {{ $labels.pod }}"
description: "L'analyse mathématique indique que le conteneur dépassera sa limite matérielle autorisée dans moins de 4 heures d'après son comportement d'écriture récent."Expliquons les rouages de cette règle d'alerte hautement préventive :
- predict_linear(...[1h], 14400) : Cette fonction statistique avancée étudie l'évolution historique de la mémoire consommée durant la dernière heure pour prédire de façon linéaire sa valeur cible dans un intervalle futur de 4 heures (exprimé ici par la valeur en secondes 14400).
- for: 15m : L'alerte ne se déclenchera pas sur un simple pic d'activité éphémère. Elle attend que la dérive linéaire alarmante soit continue et observée sur une durée de validation d'au moins 15 minutes.
Profiler et capturer les fuites de mémoire à chaud

Lorsqu'une dérive est formellement détectée, le redémarrage successif des instances ne constitue qu'un traitement temporaire des symptômes. Pour éradiquer définitivement la faille, il devient impératif d'obtenir un instantané de l'état interne de la mémoire de l'application en cours d'exécution, couramment appelé heap dump.
Configuration d'une routine de secours automatisée
La méthode moderne pour profiler une application sans dégrader ses performances de production consiste à programmer l'extraction de l'analyse directement depuis le conteneur lorsqu'un seuil d'alerte critique est franchi.
Voici le script shell d'extraction automatisée à encapsuler dans vos tâches utilitaires de maintenance :
#!/bin/sh
set -eu
POD_NAME=$(kubectl get pods -l app=resilient-node-app -o jsonpath='{.items[0].metadata.name}')
THRESHOLD_PERCENT=85
CURRENT_MEM=$(kubectl top pod "${POD_NAME}" --containers=api-server --no-headers | awk '{print $3}' | sed 's/Mi//')
LIMIT_MEM=256
USAGE_PERCENT=$((CURRENT_MEM * 100 / LIMIT_MEM))
if [ "$USAGE_PERCENT" -gt "$THRESHOLD_PERCENT" ]; then
echo "Seuil critique dépassé ($USAGE_PERCENT%). Déclenchement de l'analyse de mémoire..."
kubectl exec "${POD_NAME}" -c api-server -- node -e "
const fs = require('fs');
const v8 = require('v8');
const fileName = '/tmp/heap-' + Date.now() + '.heapsnapshot';
const stream = v8.getHeapSnapshot();
const fileStream = fs.createWriteStream(fileName);
stream.pipe(fileStream);
fileStream.on('finish', () => console.log('Capture enregistrée avec succès : ' + fileName));
"
kubectl cp "${POD_NAME}":/tmp/heap-*.heapsnapshot ./diagnostics.heapsnapshot -c api-server
echo "Fichier de diagnostic rapatrié avec succès sur la machine locale d'exploitation."
else
echo "Niveau de mémoire sous contrôle ($USAGE_PERCENT%). Aucune action requise."
fiPassons en revue les mécanismes fondamentaux mis en œuvre dans ce script d'analyse en direct :
- kubectl top pod : Permet d'obtenir en temps réel la consommation actuelle du conteneur ciblé pour calculer précisément le pourcentage de charge mémoire par rapport au plafond structurel.
- v8.getHeapSnapshot() : Cette fonction native du moteur d'exécution JavaScript génère un flux binaire contenant l'arbre de dépendances complet de tous les objets persistants en mémoire vive sans avoir recours à des bibliothèques externes tierces potentiellement instables.
- kubectl cp : Transfère de manière sécurisée le fichier de diagnostic volumineux généré dans l'environnement isolé du conteneur vers votre poste de travail d'ingénierie pour une inspection approfondie avec les outils de développement de votre navigateur.
Analyse du fichier de capture
Une fois le fichier généré et récupéré localement sous le format standardisé `.heapsnapshot`, ouvrez simplement le volet des outils de développement de votre navigateur web habituel, naviguez vers l'onglet dédié à l'analyse de mémoire et importez le fichier pour identifier instantanément les structures de données qui refusent de se détruire.
Pérenniser la stabilité de votre cluster Kubernetes
Le traitement des incidents d'allocation de mémoire vive en production ne s'improvise pas au milieu de la nuit lors d'une astreinte agitée. En adoptant une démarche scientifique basée sur la mise en adéquation des limites physiques des cgroups avec le paramétrage interne des moteurs d'exécution, vous transformez des crashs inattendus en transitions logicielles fluides et parfaitement contrôlées.
En tant qu'ingénieur système accompli, veillez à toujours concevoir vos limites de ressources avec une marge de sécurité technique d'environ 20% à 30% au-dessus des limites de déclenchement de vos outils de nettoyage interne de mémoire. Cette discipline opérationnelle simple mais rigoureuse garantira la pérennité, la stabilité ainsi que la sérénité globale de vos infrastructures cloud-natives.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Super article. Par contre, dès que je lance mon pod, il se fait kill instantanément. J'ai bien mis mes
requestsetlimitsdans mon yaml mais rien à faire.