Calcul Homomorphe : La Révolution Confidentielle du Cloud Native
Vous avez passé des années à maîtriser la sécurité en transit avec TLS et la sécurité au repos avec des disques chiffrés. Pourtant, une question fondamentale demeure : que se passe-t-il lorsque vos données doivent être utilisées, traitées, analysées ? À cet instant précis, elles redeviennent vulnérables, exposées en clair dans la mémoire de vos serveurs. Et si cette vulnérabilité intrinsèque était sur le point de disparaître ?
Le Calcul Homomorphe, C'est Quoi au Juste ?
Imaginez un instant que vous confiez à un artisan une boîte à bijoux fermée à clé, dont vous êtes le seul à posséder la clé. Vous lui demandez de polir le bijou à l'intérieur sans jamais ouvrir la boîte. L'artisan manipule la boîte, effectue son travail "à l'aveugle" et vous la rend, toujours scellée. En l'ouvrant, vous découvrez votre bijou poli. C'est exactement la promesse du Calcul Homomorphe (Homomorphic Encryption).
Il s'agit d'une forme de chiffrement révolutionnaire qui permet d'effectuer des calculs directement sur des données chiffrées, sans avoir besoin de les déchiffrer au préalable. Le résultat de l'opération, lui-même chiffré, ne peut être lu qu'une fois déchiffré par le propriétaire de la clé privée. Cela complète le triptyque de la sécurité des données : après le repos (stockage) et le transit (réseau), nous sécurisons enfin la donnée en cours d'utilisation (calcul).
Démystifier les différents niveaux de "magie"
Le concept n'est pas monolithique. Il existe plusieurs schémas de chiffrement homomorphe, chacun avec ses propres capacités et contraintes. Comprendre ces nuances est essentiel pour choisir la bonne approche en fonction du besoin métier et des contraintes de performance.
Concrètement, la complexité des opérations que vous pouvez effectuer sur les données chiffrées détermine le type de système que vous utilisez. Cela va de simples additions à des algorithmes de machine learning complexes.
- Partially Homomorphic Encryption (PHE) : Permet d'effectuer un seul type d'opération mathématique (soit des additions, soit des multiplications) un nombre illimité de fois.
- Somewhat Homomorphic Encryption (SHE) : Autorise un nombre limité d'opérations différentes (additions ET multiplications), mais pas une infinité, à cause du "bruit" qui s'accumule dans le ciphertext à chaque calcul.
- Fully Homomorphic Encryption (FHE) : Le Graal. Il permet d'exécuter n'importe quel type de calcul, un nombre illimité de fois, en utilisant une technique de "bootstrapping" pour réinitialiser le bruit après chaque opération.
L'Impact sur l'Écosystème DevOps et Cloud Native
Pour nous, ingénieurs DevOps, l'arrivée à maturité de ces technologies change fondamentalement la donne. La sécurité n'est plus seulement une affaire d'infrastructure, de pare-feux ou de gestion des secrets. Elle s'infuse directement au cœur de la logique applicative, créant un nouveau paradigme de déploiement pour les applications Cloud Native.
Le mantra "zero trust" s'étend désormais au-delà du réseau pour englober le processeur lui-même. Un pod Kubernetes n'a plus besoin d'accéder aux données en clair pour accomplir sa tâche, réduisant drastiquement la surface d'attaque en cas de compromission du nœud ou du conteneur.
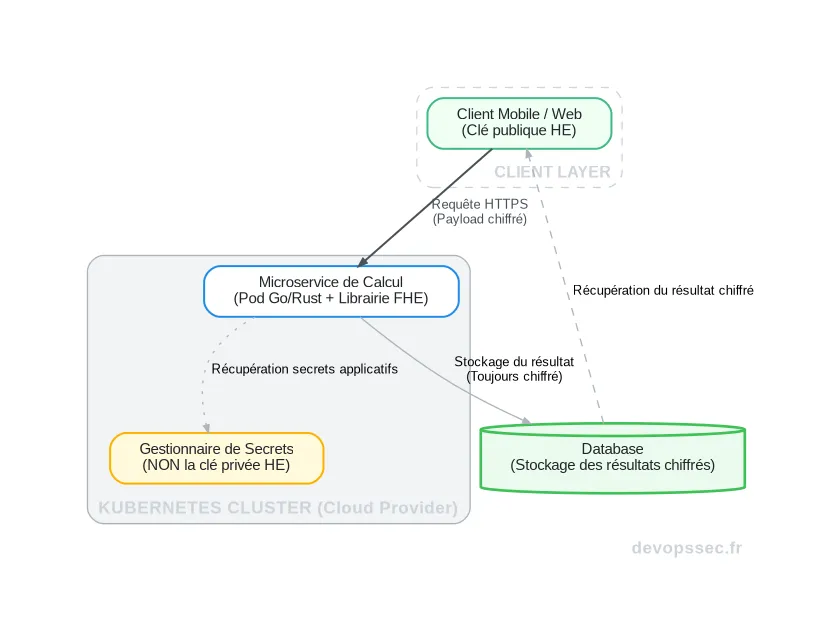
Ce schéma illustre un flux typique. Le client chiffre ses données sensibles localement avec une clé publique. Il envoie ensuite ces données chiffrées (le ciphertext) au microservice qui tourne dans le cluster Kubernetes. Le service effectue les calculs demandés directement sur le ciphertext, sans jamais voir les données en clair. Le résultat, lui-même chiffré, est stocké puis renvoyé au client, qui est le seul à pouvoir le déchiffrer avec sa clé privée.
Cas d'usage qui redéfinissent la confidentialité
Les applications pratiques ne sont plus de la science-fiction. Elles touchent des secteurs où la confidentialité est non négociable, comme la santé, la finance ou la défense, permettant d'utiliser la puissance du cloud sans sacrifier la souveraineté des données.
| Cas d'Usage | Problématique de Confidentialité | Solution avec le Calcul Homomorphe |
|---|---|---|
| Analyse prédictive de données de santé | Un hôpital veut utiliser une IA dans le cloud pour analyser des dossiers médicaux sans exposer les informations personnelles des patients. | Les dossiers sont chiffrés homomorphiquement avant l'envoi. Le modèle d'IA opère sur les données chiffrées et renvoie un score de risque, lui aussi chiffré. |
| Externalisation de la paie | Une entreprise souhaite utiliser un SaaS pour gérer la paie, mais ne veut pas que le fournisseur ait accès aux salaires en clair. | Les salaires et les informations des employés sont chiffrés. Le SaaS effectue les calculs (impôts, primes) sur les chiffres sans les connaître. |
| Vote électronique | Garantir l'anonymat du vote tout en assurant un dépouillement public et vérifiable. | Chaque vote est un "1" chiffré. Le serveur central additionne tous les votes chiffrés. Le résultat final est le seul élément déchiffré, impossible de retracer les votes individuels. |
Intégration et Déploiement : Les Nouveaux Défis
Adopter le calcul homomorphe n'est pas juste une question de changer une bibliothèque dans le code. Cela implique de repenser une partie de notre chaîne d'outillage CI/CD et nos stratégies de déploiement. La gestion des clés cryptographiques, déjà cruciale, prend une nouvelle dimension.
Un pipeline CI/CD adapté à la cryptographie
L'intégration de bibliothèques comme Microsoft SEAL, HElib ou Concrete de Zama se fait via les gestionnaires de paquets habituels. Le véritable enjeu réside dans le cycle de vie des schémas cryptographiques et des clés. Ces éléments doivent être versionnés, testés et déployés avec autant de rigueur que le code applicatif lui-même.
Votre pipeline doit désormais intégrer des étapes de "linting" cryptographique pour vérifier la robustesse des paramètres choisis, et des tests de non-régression pour s'assurer qu'une mise à jour de la bibliothèque ne compromet pas les données déjà chiffrées. Ci-dessous, un exemple de ce à quoi pourrait ressembler un Manifest Kubernetes pour un service utilisant une de ces bibliothèques.
apiVersion: apps/v1
kind: Deployment
metadata:
name: confidential-computation-service
spec:
replicas: 3
selector:
matchLabels:
app: he-processor
template:
metadata:
labels:
app: he-processor
spec:
containers:
- name: processor
image: my-registry/my-he-app:1.2.0
ports:
- containerPort: 8080
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
env:
- name: HE_SCHEME_PARAMS_PATH
value: "/etc/config/he_params.json"
volumeMounts:
- name: he-scheme-config
mountPath: "/etc/config"
readOnly: true
volumes:
- name: he-scheme-config
configMap:
name: he-scheme-v2-paramsOn remarque ici deux points importants. Premièrement, les ressources CPU et mémoire demandées (resources) sont significativement plus élevées qu'pour un microservice classique. Deuxièmement, les paramètres du schéma cryptographique sont externalisés dans une ConfigMap, ce qui permet de les mettre à jour indépendamment du code de l'application.
Attention à la gestion des clés
La clé privée permettant de déchiffrer les résultats ne doit JAMAIS se trouver sur le serveur. Elle doit rester en possession exclusive du client. La sécurité de tout le système repose sur ce principe fondamental.
Les coûts cachés de la confidentialité absolue
Le calcul homomorphe n'est pas une solution miracle sans contreparties. La confidentialité totale a un coût, et il est essentiel de le comprendre avant de se lancer dans un projet d'envergure. Ignorer ces aspects peut conduire à des applications inutilisables en production.
Le principal défi est la performance. Les opérations sur des données chiffrées sont, par nature, des ordres de grandeur plus lentes que sur des données en clair. Cet impact se mesure directement sur la latence des requêtes et sur la facture de votre fournisseur cloud.
- Surcharge de calcul (CPU) : Les opérations cryptographiques sont extrêmement intensives. Un simple calcul d'addition peut nécessiter des milliers d'opérations processeur.
- Explosion de la taille des données (RAM/Réseau) : Un entier de 64 bits, une fois chiffré, peut occuper plusieurs mégaoctets en mémoire. Cela impacte la consommation de RAM, la bande passante réseau et les coûts de stockage.
- Complexité d'implémentation : Choisir les bons paramètres pour un schéma FHE demande une réelle expertise. Un mauvais choix peut soit rendre le système vulnérable, soit le rendre inutilisablement lent.
Vers une Confiance Zéro Intégrale
Le calcul homomorphe est bien plus qu'une simple technologie de chiffrement. C'est une pièce maîtresse qui nous permet enfin d'envisager des architectures où la confiance n'est plus un prérequis, même au niveau le plus bas de la pile d'exécution. C'est l'aboutissement logique de la démarche "zero trust".
Même si les défis de performance restent réels, les progrès fulgurants des bibliothèques et l'arrivée d'accélérateurs matériels dédiés rendent cette technologie de plus en plus accessible. Elle ne remplacera pas toutes les autres mesures de sécurité, mais elle offre une nouvelle garantie fondamentale pour les cas d'usage les plus sensibles.
Pour vous qui débutez dans le DevOps, c'est le moment idéal pour commencer à vous familiariser avec ces concepts. Montez des petits PoC, jouez avec les bibliothèques open source, mesurez l'impact sur les performances. Car demain, savoir déployer et opérer un service qui traite des données sans jamais les voir sera une compétence aussi essentielle que de savoir écrire un Dockerfile aujourd'hui.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
Pour ceux qui veulent creuser l'impact sur le
Deployment, voici comment on ajuste les limites pour éviter le OOMKill :C'est énorme, mais nécessaire à cause de la taille des objets chiffrés.
Exactement. C'est l'opération la plus coûteuse en cycle CPU.
Sans ça, tu serais limité au SHE, donc à un nombre fini d'opérations.
Juste pour être sûr, le
bootstrappingc'est bien ce qui permet de réinitialiser le bruit sans décrypter ?Pour de l'inférence simple, oui. Pour de l'entraînement massif, on est encore loin du compte.
On en est à l'étape des PoC fonctionnels mais très lents.
Merci pour l'article. Est-ce que le FHE est réellement prêt pour des workloads de type
Machine Learning?Utilise des tags de version sur tes ConfigMaps avec un hash unique.
Ne fais pas de mise à jour in-place sur un schéma en prod, c'est le meilleur moyen de corrompre tes données.
J'ai essayé de déployer ça avec Helm, mais la gestion des ConfigMaps pour les paramètres de chiffrement devient un enfer de versioning.
Tu ne monitores pas la donnée, tu monitores le bruit et la consommation CPU.
Si le niveau de bruit dépasse un seuil, ton calcul va échouer. Il faut exposer ces métriques via un exporter custom.
C'est bien beau tout ça, mais niveau monitoring, comment tu tracks la santé d'un calcul qui tourne à l'aveugle ?
Prometheus ne voit que des blobs chiffrés.
La clé privée ne doit jamais être dans le cluster. Elle reste côté client.
Le pod ne manipule que les paramètres du schéma (ex:
he_params.json) pour savoir comment traiter le ciphertext.Le point sur le
volumeMountsen read-only est crucial.Comment tu fais pour injecter les paramètres sans exposer la clé privée par erreur dans le pod ?
Le GPU aide, mais le gain est surtout visible si tu utilises des bibliothèques optimisées pour le parallélisme massif.
Pour les coûts, c'est le prix de la souveraineté. Si tes données valent cher, le coût infra devient secondaire.
Perso, on a essayé d'intégrer ça sur un cluster EKS, mais le coût CPU a fait exploser notre facture EC2 en une semaine.
Faut-il vraiment passer sur du GPU pour que ce soit viable ?
L'explosion de la taille des données mentionnée est inquiétante pour nos coûts de sortie réseau AWS.
Vous avez des retours d'expérience sur la compression des
ciphertext?Si tu veux du rapide, regarde du côté de Concrete de Zama. Ils abstraient pas mal de complexité mathématique.
Tu peux tester rapidement avec ce petit snippet en Python :
Concrètement, quelles librairies tu recommandes pour un premier PoC ?
J'ai testé SEAL mais la courbe d'apprentissage est violente pour un devops classique.
C'est là que ça devient complexe. Tu ne peux pas simplement ré-encrypter sans déchiffrer au milieu.
La stratégie, c'est le re-encryption proxy ou maintenir une version historique des paramètres dans ton
config.yaml.Le
HE_SCHEME_PARAMS_PATHdans le manifest est une bonne idée pour la gestion des configs.Mais comment tu gères la rotation des clés sans casser les données déjà chiffrées en base ?
La latence est le vrai point noir. Pour 4Gi, c'est une base pour traiter des petits vecteurs. Si tu veux monter en charge, tu vas vite saturer ton CPU avec le bootstrapping en FHE.
C'est pas pour du temps réel, c'est pour du traitement asynchrone.
Article intéressant, mais on parle de quel niveau de latence réelle en prod ?
Sur ton exemple avec
4Gide RAM, c'est pour quel type de volume de données par requête ?