Le silo est mort, vive la convergence !
As-tu déjà eu cette sensation de jongler avec une dizaine d'outils différents juste pour déployer une simple modification ? Un peu de Terraform par-ci, un pipeline Jenkins par-là, des manifestes Kubernetes dans un coin et des règles de sécurité gérées dans une console obscure. Cette fragmentation, c'est l'anti-DevOps. Elle crée des frictions, ralentit les cycles et rend le système opaque.
L'approche déclarative unifiée propose une rupture radicale avec ce modèle. L'idée n'est plus de dire au système *comment* faire les choses, mais de décrire l'état final désiré dans une source de vérité unique, généralement un dépôt Git. Tout le reste, de la création d'un VPC à la configuration d'un pod applicatif, devient une conséquence de ce que vous avez écrit.
Cette vision transforme radicalement notre métier. Nous ne sommes plus des opérateurs qui cliquent sur des boutons ou qui lancent des scripts impératifs. Nous devenons les architectes d'un système auto-guérisseur, dont l'état entier est versionné, auditable et reproductible à l'infini.
Les piliers de la maîtrise déclarative
Pour atteindre cette gouvernance totale par le code, il faut assembler plusieurs briques conceptuelles. Chacune d'elles étend le principe "As Code" à une nouvelle facette de votre système d'information, créant une synergie puissante.
Le socle : l'Infrastructure as Code (IaC)
C'est le point de départ incontournable. L'IaC consiste à définir vos ressources cloud (serveurs, bases de données, réseaux) dans des fichiers de configuration. Au lieu de provisionner manuellement une machine virtuelle, vous décrivez ses caractéristiques dans un langage comme HCL pour Terraform.
Le moteur d'IaC se charge ensuite de comparer l'état décrit dans votre code avec l'état réel de l'infrastructure et d'appliquer les changements nécessaires. C'est le principe de convergence continue : le système cherche en permanence à correspondre à sa définition codée.
# Exemple simplifié de ressource avec un moteur d'IaC
# Fichier: production/network.hcl
resource "cloud_vpc" "main" {
name = "vpc-prod-main"
cidr_block = "10.0.0.0/16"
enable_dns_support = true
}
resource "cloud_subnet" "web_tier" {
vpc_id = cloud_vpc.main.id
cidr_block = "10.0.1.0/24"
availability_zone = "eu-west-3a"
}Cette approche apporte une traçabilité et une reproductibilité sans faille. Cloner un environnement entier devient aussi simple qu'une nouvelle branche Git et un nouveau contexte d'exécution.
L'extension logique : la Politique en tant que Code (PaC)
Une fois l'infrastructure définie, la question suivante est : comment s'assurer que tout ce qui y est déployé respecte les règles de l'entreprise ? C'est là qu'intervient la Politique en tant que Code (Policy as Code). Des outils comme Open Policy Agent (OPA) permettent de définir des règles de sécurité et de conformité dans un langage dédié, comme Rego.
Ces politiques sont stockées dans le même dépôt Git que votre infrastructure. Elles peuvent ensuite être appliquées à chaque étape du cycle de vie.
| Étape du Cycle de Vie | Exemple de Politique Appliquée |
|---|---|
| Commit de code | Vérifier que l'image Docker n'utilise pas la version `latest`. |
| Plan d'IaC | Interdire la création de buckets de stockage publics. |
| Admission sur Kubernetes | Exiger que chaque déploiement possède des `requests` et `limits` de ressources. |
| Runtime | Auditer en continu les configurations pour détecter les dérives. |
L'avantage est immense : la sécurité n'est plus une réflexion après coup mais une garde-fou automatisée et intégrée nativement dans le flux de travail des développeurs.
Le flux unifié en action : du code à la production
Concrètement, comment tout cela s'articule-t-il ? Le modèle le plus abouti pour orchestrer cette approche est le GitOps. Le dépôt Git devient le centre de commande, et des agents automatisés se chargent de synchroniser l'état réel avec l'état désiré décrit dans la branche principale.
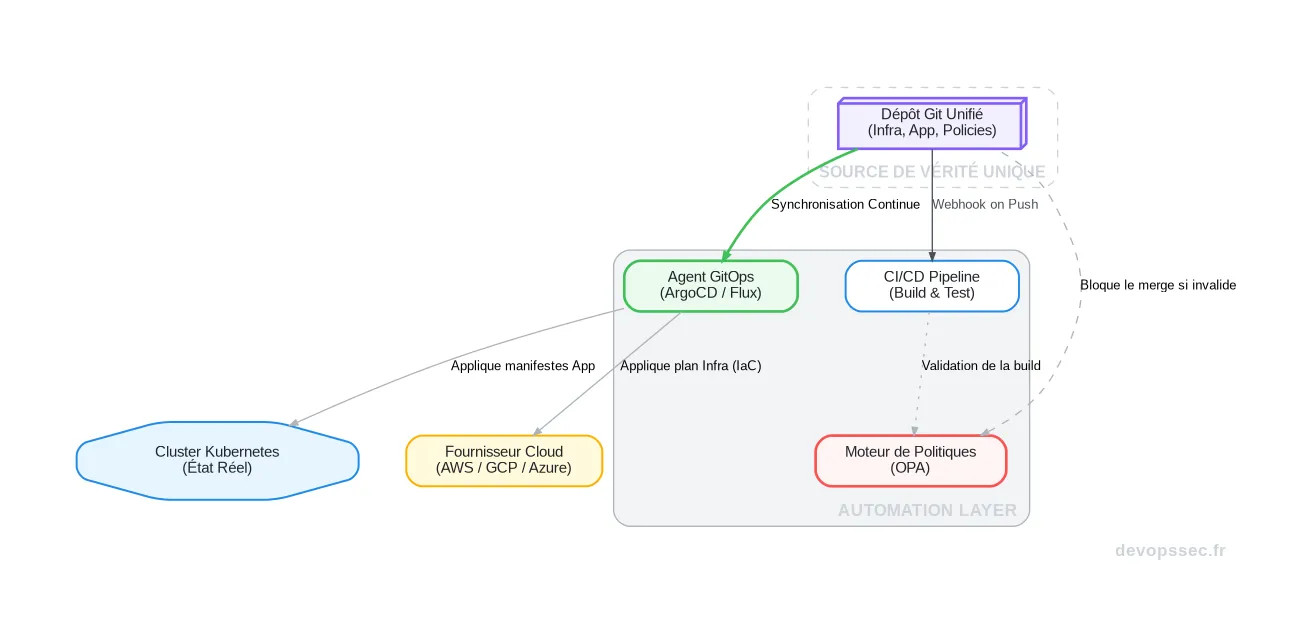
Ce schéma illustre le cycle de vie complet. Un développeur pousse une modification dans le dépôt Git. Le pipeline de CI se déclenche, construit les artéfacts, puis le moteur de politiques valide la conformité de la demande de changement. Si tout est conforme, la modification est fusionnée, et l'agent GitOps détecte le changement, puis orchestre la convergence de l'infrastructure et de l'application vers ce nouvel état désiré.
Attention à la complexité de l'outillage
L'approche unifiée est puissante, mais elle peut introduire une forte dépendance à un outil central (comme un contrôleur GitOps). Assurez-vous que cet outil est lui-même hautement disponible et que ses processus de mise à jour et de reprise après sinistre sont maîtrisés.
Les coûts cachés et les défis de l'unification
Adopter ce modèle n'est pas une simple transition technique, c'est un changement culturel profond. Il ne faut pas sous-estimer la courbe d'apprentissage. Vos équipes doivent non seulement maîtriser leur domaine (développement, infra, sécurité), mais aussi apprendre à l'exprimer de manière déclarative.
Le risque principal est de créer un monolithe de configuration. Si un seul dépôt gouverne tout, une erreur de syntaxe mineure dans un fichier de politique pourrait bloquer les déploiements de toute l'entreprise. Une gouvernance forte, avec des revues de code rigoureuses et une séparation claire des responsabilités via la structure des dossiers (/infra, /apps, /policies), est absolument cruciale.
Enfin, la détection de dérive (drift) devient un enjeu majeur. Que se passe-t-il si quelqu'un modifie manuellement une ressource en production ? Votre système doit non seulement détecter cet écart par rapport à la source de vérité, mais aussi avoir une stratégie claire : faut-il écraser la modification manuelle automatiquement ou simplement alerter l'équipe d'astreinte ? La réponse dépend du niveau de criticité de la ressource.
Conclusion : Vers une ingénierie de système holistique
Le DevOps déclaratif unifié n'est pas une mode passagère, c'est l'aboutissement logique du mouvement "Everything as Code". En traitant l'ensemble de votre système comme un grand programme logiciel cohérent, vous gagnez des niveaux de résilience, d'agilité et de visibilité qui étaient impensables avec des approches silotées.
Le chemin est exigeant et demande de nouvelles compétences, notamment une compréhension profonde de la théorie des systèmes et des architectures distribuées. Mais la récompense est à la hauteur : des systèmes qui ne tombent plus en panne, mais qui convergent en permanence vers l'état parfait que vous avez conçu et codé.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
22 commentaires
On utilise
terratestpour ça. Ça permet de valider que ton infrastructure se déploie correctement avant de merge. C'est indispensable si tu veux éviter les mauvaises surprises en prod.Est-ce que vous avez des retours sur l'utilisation de tests unitaires pour le code HCL ? Ça semble être la suite logique de votre approche, mais personne ne le fait vraiment.
D'accord avec ça. L'automatisation sans processus, c'est juste une manière plus rapide de se tirer une balle dans le pied. Le code doit refléter une architecture saine, pas juste masquer un chaos existant.
Le problème de fond c'est que beaucoup confondent "GitOps" et "automatisation". GitOps c'est un pattern, pas une solution miracle. Si ton processus métier est pourri, l'automatiser ne fera que le rendre pourri plus vite.
J'ai testé cette approche. Le souci c'est quand le provider cloud change son API. Ton code déclaratif devient obsolète du jour au lendemain et t'as des erreurs 400 partout.
Justement, si ton outil est déclaratif, le développeur devient autonome. Il n'a plus besoin de solliciter l'expert DevOps pour chaque changement de règle de firewall. C'est ça, la vraie démocratisation de l'infra.
L'auteur a raison sur un point : la fin des silos. Mais le prix à payer c'est que le DevOps devient un expert en tout, ce qui est intenable. On finit par avoir des super-DevOps qui sont des goulots d'étranglement.
Mouais, le déclaratif c'est bien, mais ça masque la complexité réelle du système. Quand ça casse, tu ne sais plus si c'est la config, le controller ou le cloud provider qui déconne.
Perso, j'injecte via un sidecar qui va chercher dans Vault. Jamais de secrets en clair dans le repo.
Vous utilisez quoi pour gérer les secrets dans votre approche "tout code" ? Parce que mettre des variables dans un
deployment.yamlc'est risqué. Vous gérez comment le cycle de vie des clés ?Pour le legacy, faut utiliser
terraform importpetit à petit, par périmètre fonctionnel. Faut pas chercher à tout "gitopser" d'un coup. C'est une migration, pas un reboot.Le "tout déclaratif" ça marche quand t'as une infra propre dès le début. Pour migrer du legacy, c'est juste impossible. On fait comment pour importer des ressources non-gérées sans tout casser ?
J'ai essayé de tout mettre dans un repo Git unique comme suggéré. À 50 développeurs, c'est l'enfer des merges. On passe plus de temps à gérer les conflits qu'à coder l'infra.
La vélocité vient de la confiance. Si tu sais que tes politiques empêchent les erreurs critiques, tu peux pousser en prod beaucoup plus sereinement. Mieux vaut 20 minutes de build que 2 heures de rollback à 3h du mat.
C'est beau de dire "on code tout". Mais quand ton pipeline CI met 20 minutes à valider une simple modif de config parce qu'il doit checker 50 policies OPA avant de lancer le
terraform plan, la vélocité elle est où ?L'article parle de "convergence continue". J'ai vu des clusters Kubernetes se faire détruire par une boucle de réconciliation mal configurée qui a interprété une latence réseau comme une dérive. C'est dangereux.
Pour OPA, le secret c'est la modularité. Faut pas faire un monolithe. Pour Terraform, utilisez un backend distant avec verrouillage (DynamoDB par exemple) et surtout, divisez vos stacks par couche. Le
terraform.tfstatene devrait jamais être global.Le problème de l'IaC avec Terraform, c'est la gestion de l'état. Le fichier
terraform.tfstate, c'est la plaie. Dès que deux personnes touchent au même module, t'es bon pour des conflits de lock.Je bosse avec OPA depuis deux ans. C'est génial pour la conformité, mais le langage Rego est une abomination à maintenir sur le long terme. Qui relit vos fichiers
policy.regoquand ils font 500 lignes ?Le point de défaillance unique est un choix architectural, pas une fatalité. On peut scaler les contrôleurs ou utiliser du multi-cluster. Et pour le
kubectl editen urgence, c'est justement là que la culture DevOps intervient : si tu dois patcher à la main, c'est que ton processus de déploiement est trop lent ou rigide.Exactement. Et la gestion du drift, c'est de la théorie pour les slides. En vrai, quand t'as une urgence en prod, le mec d'astreinte va faire un
kubectl editpour débloquer la situation. Ton GitOps va se battre contre lui et tout écraser au prochain sync.Tout ça c'est très joli sur le papier. Mais le "déclaratif unifié", c'est le meilleur moyen de créer un point de défaillance unique massif. Si ton contrôleur GitOps tombe, tu fais quoi ?