L'IA Redéfinit l'Architecture Logicielle : Vers des Systèmes Auto-Conçus en DevOps
Vous avez probablement remarqué que le rôle de l'architecte logiciel a subtilement commencé à muter ces dernières années. Fini le temps où les schémas étaient gravés dans le marbre pour des mois, voire des années. Aujourd'hui, nous entrons dans une ère où l'architecture est un organisme vivant, qui respire et s'adapte en temps réel, et cette transformation est largement catalysée par l'intelligence artificielle.
L'idée n'est plus de concevoir un système parfait du premier coup, mais de mettre en place un cadre capable d'évoluer intelligemment. L'IA ne remplace pas l'architecte, elle lui fournit des super-pouvoirs : une capacité d'analyse et de prédiction qui dépasse de loin ce qu'un humain ou même une équipe entière pourrait accomplir manuellement.
Cette nouvelle approche nous pousse à penser nos applications non plus comme des monolithes immuables ou des microservices statiques, mais comme des écosystèmes dynamiques. Des systèmes qui apprennent de leur propre fonctionnement pour s'optimiser en continu, c'est la promesse des Systèmes Auto-Conçus que nous allons explorer ensemble.
Les Fondations de l'Architecture Assistée par IA
Pour qu'une IA puisse "penser" l'architecture, elle a besoin de carburant, de données brutes et contextuelles sur le comportement du système. C'est là que les piliers du DevOps moderne entrent en jeu, en fournissant un flux constant d'informations que des modèles peuvent interpréter pour en extraire des recommandations pertinentes et actionnables.
Le Triptyque Sacré : Logs, Métriques et Traces
Le socle de toute décision architecturale intelligente est une Observabilité exhaustive. Sans une vision claire et détaillée de ce qui se passe à l'intérieur de vos applications, une IA navigue à l'aveugle. Elle ne peut pas suggérer de scinder un service trop lent si elle ne peut pas mesurer sa latence, ni recommander de renforcer une file d'attente si elle ignore son taux de saturation.
Concrètement, l'IA va consommer et corréler en permanence des sources de données incroyablement variées pour se forger une compréhension holistique de la santé et de l'efficacité de l'architecture. Elle ne se contente pas de lire les chiffres, elle cherche les signaux faibles, les schémas récurrents et les anomalies.
Voici ce qu'un modèle d'IA typique va analyser en continu :
- Les métriques de performance : Temps de réponse des API, utilisation CPU/RAM des conteneurs, taux d'erreur 5xx, latence de la base de données.
- Les traces distribuées : Cartographie des appels entre microservices pour identifier les goulots d'étranglement ou les dépendances critiques cachées.
- Les journaux (logs) : Détection d'erreurs récurrentes, d'avertissements de sécurité ou de comportements inattendus dans les flux applicatifs.
- Les coûts d'infrastructure : Analyse de la consommation cloud pour suggérer des optimisations, comme le passage à des instances moins chères ou l'utilisation de spot instances.
Des Modèles Prédictifs au Service de la Scalabilité
Une fois que l'IA a ingéré ces données, elle passe de la simple observation à la prédiction. C'est le cœur du Cognitive DevOps. En se basant sur les tendances historiques, elle peut anticiper des pics de charge avant même qu'ils ne se produisent et proposer des ajustements proactifs à l'infrastructure.
Imaginons un site e-commerce. Un modèle d'IA entraîné sur les données des années précédentes pourrait détecter l'approche d'une période de soldes et recommander automatiquement une augmentation des réplicas pour les services de panier et de paiement, bien avant que les premiers clients n'arrivent. Cela va plus loin que le simple auto-scaling réactif basé sur le CPU.
Dans un orchestrateur comme Kubernetes, cela pourrait se traduire par une nouvelle génération de Horizontal Pod Autoscalers (HPA) qui ne se basent plus seulement sur des métriques instantanées, mais sur des modèles prédictifs. La définition ressemblerait à ceci, où un `behaviorModel` indiquerait à l'HPA de faire confiance à une source d'analyse externe.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-payment-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-payment
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Pods
value: 10
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300
# Ici réside la nouveauté : une référence à un modèle prédictif externe
prediction:
modelProvider: "prometheus-ai-predictor"
behaviorModel: "aggressive-seasonal-scaling"L'IA Architecte en Action : Un Flux de Travail Concret
Maintenant, voyons comment cette intelligence s'intègre concrètement dans nos cycles de développement. L'un des cas d'usage les plus puissants est l'intégration d'un Agent Gardien d'Architecture directement dans la pipeline CI/CD. Son rôle est d'agir comme un relecteur de code ultra-compétent, mais spécialisé dans l'impact architectural des changements proposés.
Cet agent analyse chaque pull request non pas pour la qualité du code, mais pour ses conséquences sur la performance, la sécurité et la résilience globale du système. Il devient une barrière de sécurité automatisée contre la "dette architecturale".
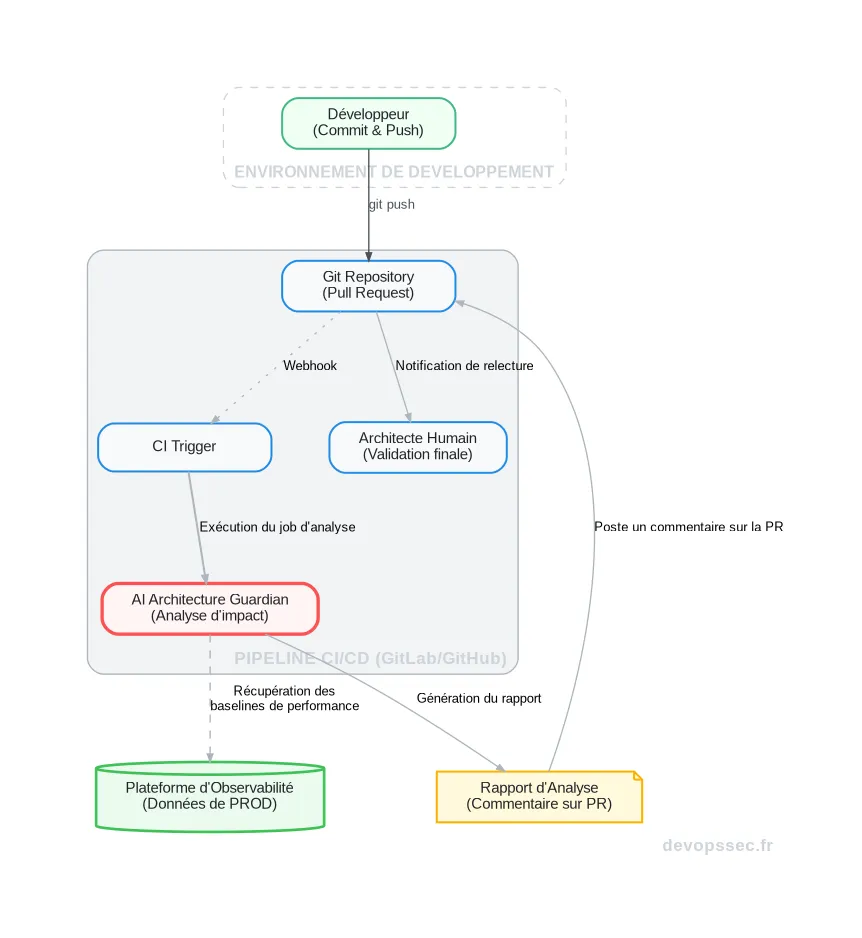
Le schéma ci-dessus illustre ce flux. Un développeur ouvre une pull request. La pipeline de CI se déclenche et exécute une étape dédiée à notre agent IA. Cet agent va alors interroger la plateforme d'observabilité pour récupérer des métriques de performance de l'environnement de production. Il compare le code modifié avec ces données pour simuler l'impact, puis génère un rapport qu'il poste directement en commentaire de la pull request, avant même que le premier relecteur humain n'ait posé les yeux dessus.
Les Risques et les Coûts Cachés de l'Autonomie
Cependant, il est crucial de ne pas tomber dans une confiance aveugle envers ces systèmes. L'intégration de l'IA dans l'architecture logicielle apporte son propre lot de défis et de complexités qu'il faut savoir anticiper pour éviter les mauvaises surprises.
Le principal risque est celui du "model drift", ou la dérive du modèle. Un modèle d'IA, même le plus performant, est entraîné sur des données passées. Si le comportement de vos utilisateurs ou de votre application change radicalement, les recommandations de l'IA peuvent devenir obsolètes, voire contre-productives. Une surveillance humaine et un ré-entraînement régulier des modèles sont donc non négociables.
| Avantages de l'IA Architecturale | Risques et Coûts Associés |
|---|---|
| Détection proactive des goulots d'étranglement. | Coût de calcul (GPU) pour l'entraînement et l'inférence. |
| Optimisation continue des coûts d'infrastructure. | Complexité de la mise en place et de la maintenance de la MLOps. |
| Réduction de la dette architecturale. | Risque de suggestions incorrectes (dérive du modèle). |
| Accélération des cycles de validation. | Nécessite des experts pour interpréter et valider les résultats. |
Conclusion : L'Architecte Augmenté, Pas Remplacé
Alors, est-ce la fin du rôle d'architecte logiciel tel que nous le connaissons ? Certainement pas. C'est plutôt sa redéfinition. L'architecte de demain ne passera plus des semaines à dessiner des diagrammes sur un tableau blanc, mais à définir les règles, les objectifs et les garde-fous pour des systèmes d'IA qui feront le travail d'analyse à sa place.
Le rôle évolue vers celui d'un superviseur, d'un stratège. La compétence clé ne sera plus seulement de savoir concevoir une architecture, mais de savoir questionner, valider et orienter les suggestions d'une intelligence artificielle. Il faudra arbitrer entre une optimisation de coût proposée par l'IA et un impératif de résilience qu'elle n'aurait pas su modéliser.
En somme, l'IA ne nous vole pas notre travail, elle le rend plus intéressant. Elle automatise les tâches d'analyse fastidieuses et nous libère du temps pour nous concentrer sur ce qui a le plus de valeur : la vision stratégique, l'innovation et la compréhension profonde des besoins métier. Préparez-vous à devenir un architecte augmenté.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
18 commentaires
Au contraire, on se débarrasse de la glue technique pour se concentrer sur les patterns de haute disponibilité.
C'est une opportunité de monter en compétence sur la partie stratégique.
Le concept d'architecte augmenté est séduisant, mais on va finir par devenir des opérateurs de modèles au lieu d'ingénieurs.
C'est encore du sur-mesure. Voici la structure de base du sidecar qui envoie les données au provider :
Le reste c'est du code métier qui calcule les tendances.
Je vois beaucoup d'articles comme ça, mais niveau implémentation, on est encore loin du compte. Tu as un repo exemple pour le
behaviorModel?C'est là que le
GitOpssauve la mise. Chaque modif faite par l'IA doit être tracée via un commit signé.L'auditeur regarde l'historique du repo, pas la magie derrière.
C'est bien beau tout ça, mais en entreprise, on a des contraintes de compliance. Comment expliquer à un auditeur qu'une IA a changé la config réseau ?
L'IA ne doit jamais avoir les droits en
cluster-admin.Elle propose des PR, et c'est un humain qui valide le merge. L'IA propose, le DevOps dispose. C'est la seule façon de rester serein.
Intéressant, mais quid de la sécurité ? Si l'IA peut modifier la config, on risque pas des injections dans les manifests
yaml?Il faut filtrer à la source avec un
FluentdouVector.N'envoie à ton moteur d'IA que les métriques agrégées et les erreurs 5xx. Le log debug, ça sert à rien pour l'archi.
J'ai testé l'approche sur un petit cluster. Le souci c'est la verbosité des logs. Si l'IA analyse tout, on explose les coûts de stockage dans
Elasticsearch.Totalement d'accord. Faut pas utiliser des gros modèles LLM pour ça. Un simple modèle de régression linéaire ou un
RandomForestléger tourne sur n'importe quel CPU de worker.Ne jamais sur-ingénier une solution de scaling.
Le coût des GPU pour l'inférence, c'est pas un peu overkill pour juste scaler des pods ?
On utilise un script Python qui interroge l'API
Prometheuspendant le job de test.C'est basique mais ça suffit pour bloquer une PR qui dégrade la performance.
Sympa l'idée de l'Agent Gardien en CI. Concrètement, vous utilisez quoi pour parser les PR et injecter les stats d'infra ?
Il faut traiter les recommandations de l'IA comme des alertes
Prometheusclassiques.Si l'écart entre la prédiction et la conso réelle dépasse un delta de 20%, on déclenche une alerte de "dérive de modèle" pour forcer un ré-entraînement sur les données des 48 dernières heures.
Le model drift mentionné est le vrai problème. En prod, on a déjà du mal à garder des seuils cohérents, alors laisser une IA décider...
Tu préconises quoi pour monitorer la pertinence des recommandations de l'IA ?
C'est une remarque pertinente. La règle d'or ici est le fallback statique.
Ton contrôleur doit toujours avoir une règle de secours basée sur les métriques standard (CPU/RAM) si le provider de prédiction ne répond pas dans les temps.
Article intéressant, mais le coup de l'auto-scaling prédictif dans le
HorizontalPodAutoscalerme laisse sceptique.Comment tu gères le fait que le
modelProvidersoit indisponible pendant un pic de charge ? C'est le crash assuré.