Vous pensiez maîtriser vos coûts cloud avec vos dashboards FinOps ?
C'est une question que beaucoup d'équipes se posent, fières de leurs graphiques et de leurs rapports de dépenses. Pourtant, cette vision, bien que nécessaire, reste fondamentalement réactive. Vous analysez ce qui a déjà été dépensé, vous optimisez après coup. Imaginez un instant un système qui ne se contente pas de suivre les coûts, mais qui les anticipe et les négocie en permanence, de manière autonome.
C'est précisément la promesse de la nouvelle vague qui submerge le monde du DevOps : l'alliance de l'intelligence artificielle et de l'ingénierie financière pour créer un arbitrage cloud dynamique. Nous ne parlons plus de simple optimisation, mais d'une gestion prédictive et stratégique de vos ressources informatiques, transformant votre infrastructure en un véritable actif financier intelligent.
Au-delà du FinOps : Qu'est-ce que l'Arbitrage Cloud Dynamique ?
Pour bien saisir cette révolution, il faut d'abord comprendre les limites du modèle précédent. Le FinOps, en tant que pratique culturelle et technique, a été une étape cruciale pour responsabiliser les équipes sur leurs dépenses cloud. Il a apporté la visibilité là où régnait le chaos.
Cependant, son approche repose sur des cycles humains : analyse des factures, réunions de planification, ajustements manuels des instances. Dans un monde où les prix des ressources spot peuvent changer en quelques secondes et où les besoins applicatifs fluctuent de manière imprévisible, cette méthode a atteint son plafond de verre.
Le principe : traiter le Cloud comme un marché financier
L'Arbitrage Cloud Dynamique s'inspire directement des stratégies de trading à haute fréquence. L'idée est simple : pourquoi payer un prix fixe pour une ressource de calcul ou de stockage quand son coût varie constamment entre différents fournisseurs et régions ? Un moteur d'IA peut analyser ces variations en temps réel et prendre des décisions à votre place.
Concrètement, ce système ne se contente pas de comparer les prix bruts. Il intègre une multitude de paramètres pour prendre la meilleure décision à un instant T, transformant la gestion de l'infrastructure en une véritable science de la donnée.
| Paramètre Analysé par l'IA | Impact sur la Décision |
|---|---|
| Prix des instances (Spot, On-Demand) | Choix du fournisseur le moins cher pour des workloads non critiques. |
| Latence réseau vers les utilisateurs | Déploiement des ressources dans la région la plus proche des pics de trafic. |
| Coûts de transfert de données (egress) | Éviter les migrations qui coûteraient plus cher en sortie de données qu'en économie de calcul. |
| Prédictions de charge applicative | Provisionner des ressources à l'avance sur un cloud moins cher en prévision d'un pic. |
| Disponibilité des types d'instances spécifiques | Basculer sur un autre fournisseur si un type de GPU ou de CPU spécialisé vient à manquer. |
Ce niveau d'analyse permet non seulement des économies substantielles mais aussi une augmentation de la résilience et de la performance de vos applications, en s'adaptant dynamiquement aux conditions du marché global du cloud.
Architecture d'un Moteur d'Arbitrage Intelligent
Mettre en place un tel système ne se fait pas avec un simple script. Cela requiert une architecture pensée pour la collecte de données massives, la prise de décision rapide et une exécution automatisée et sécurisée. Le socle de cette architecture est une Observabilité sans faille de toute votre infrastructure.
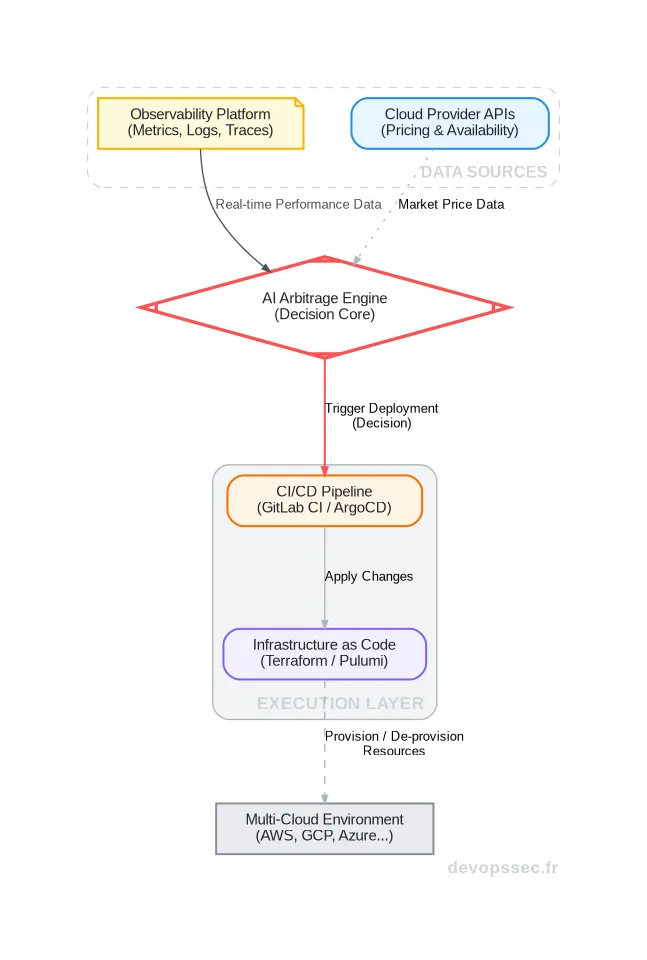
Ce schéma illustre le cœur du processus. Les plateformes d'observabilité et les API des fournisseurs cloud alimentent continuellement le moteur d'IA en données. En se basant sur des modèles prédictifs et des règles que vous définissez, le moteur prend une décision, comme "déplacer 50 pods de calcul de la région eu-west-1 sur AWS vers europe-west4 sur GCP pour les 6 prochaines heures". Cette décision devient alors une instruction pour votre pipeline CI/CD, qui se charge de l'appliquer via votre code d'infrastructure.
Définir les règles du jeu pour l'IA
L'intelligence de ce système ne réside pas seulement dans sa capacité à analyser les prix, mais aussi dans sa faculté à respecter les contraintes métier que vous lui imposez. L'IA n'est pas une boîte noire incontrôlable c'est un outil que vous configurez avec des garde-fous très stricts, souvent via un fichier de configuration déclaratif.
Voici un exemple de ce à quoi pourrait ressembler une politique d'arbitrage, définie en YAML. Ce fichier serait la constitution de votre moteur, ses lois fondamentales.
# policies/arbitrage-policy-production.yaml
apiVersion: arbitrage.io/v1alpha1
kind: ArbitragePolicy
metadata:
name: prod-workload-optimizer
spec:
# Sélectionne les applications sur lesquelles cette politique s'applique
targetWorkloads:
- namespace: production
selector:
app: data-processing
# Contraintes à respecter impérativement
constraints:
maxLatencyMs: 50
dataResidency: # Souveraineté des données
- EU
minInstanceCpu: 4
minInstanceMemory: 16Gi
# Objectifs d'optimisation, par ordre de priorité
optimizationGoals:
- strategy: cost # Priorité 1 : minimiser le coût
priority: 1
- strategy: carbon_footprint # Priorité 2 : minimiser l'empreinte carbone
priority: 2
# Fournisseurs autorisés pour cet arbitrage
allowedProviders:
- aws
- gcp
- scalewayDans cet exemple, on demande à l'IA de minimiser le coût pour les applications de traitement de données en production, tout en garantissant une latence inférieure à 50ms, en gardant les données en Europe, et en utilisant des instances d'une certaine taille. Si deux options de coût sont égales, elle choisira la plus écologique. C'est ce niveau de finesse qui rend l'approche si puissante.
Les Risques et les Limites à ne pas Ignorer
Adopter une stratégie d'arbitrage dynamique est un projet d'une complexité technique considérable. Il serait malhonnête de ne présenter que les avantages sans aborder les défis, qui sont bien réels et nécessitent une grande maturité DevOps.
Le premier obstacle est la standardisation. Pour pouvoir déplacer une charge de travail d'un cloud à l'autre de manière transparente, vos applications doivent être entièrement conteneurisées et orchestrées, idéalement via Kubernetes. Toute dépendance à un service managé spécifique à un fournisseur (comme AWS Lambda ou Google BigQuery) crée un "verrou propriétaire" qui rend l'arbitrage impossible pour cette partie de l'application.
Coûts cachés et effet de bord
Ironiquement, un système conçu pour économiser de l'argent a ses propres coûts. La mise en place, la maintenance du moteur d'IA et la puissance de calcul nécessaire à ses analyses ne sont pas gratuites. De plus, une mauvaise configuration peut entraîner des effets désastreux.
- Coûts de sortie (Egress Fees) : C'est le piège le plus courant. L'IA pourrait décider de déplacer une base de données vers un fournisseur moins cher, sans réaliser que le coût de transfert des données annule les économies pour les dix prochaines années.
- Fragmentation de l'état : Déplacer des applications avec état (stateful) est infiniment plus complexe que des applications sans état (stateless). La synchronisation des données entre les clouds peut devenir un cauchemar de performance et de cohérence.
- Complexité du débogage : Quand une application tombe en panne, le problème vient-il du code, de l'infrastructure, du fournisseur cloud A, du fournisseur B, ou du moteur d'arbitrage lui-même ? L'Observabilité doit être exceptionnelle pour s'y retrouver.
Conseil de Mentor
Ne commencez jamais un projet d'arbitrage sur vos systèmes de production critiques. Choisissez un workload stateless, non sensible à la latence et à faible volume de données pour faire vos premières armes. Apprenez à maîtriser la complexité sur un périmètre réduit avant de rêver de généraliser.
Conclusion : Vers une Infrastructure Financièrement Consciente
L'arbitrage cloud dynamique piloté par l'IA n'est pas une simple évolution du FinOps, c'est un saut quantique. Il transforme la gestion d'infrastructure d'une discipline de coûts subis à une stratégie d'investissement optimisée en temps réel. C'est le moment où le DevOps et la finance convergent véritablement.
Pour vous, jeunes talents de la tech, c'est une opportunité fantastique. Les compétences requises ne sont plus seulement techniques (Kubernetes, Terraform, CI/CD), mais aussi analytiques et financières. Comprendre les mécanismes du marché du cloud, savoir interpréter les données de performance et configurer des modèles d'IA deviendront des atouts majeurs.
Le chemin est complexe, mais la récompense est une infrastructure non seulement plus économique, mais aussi plus résiliente, plus performante et, à terme, plus respectueuse de l'environnement. L'infrastructure de demain ne sera pas seulement codée, elle sera intelligemment arbitrée.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
La complexité est là, c'est vrai. Mais c'est une complexité choisie pour gagner en agilité financière. On ne peut pas avoir le beurre et l'argent du beurre sans accepter de gérer cette couche de contrôle.
Ça reste une abstraction de trop. Quand ça pète à 3h du matin, personne ne va lire le modèle d'IA. On va juste vouloir savoir quel pod est down. La complexité cognitive est le vrai coût caché.
Bonne pratique. Le principe du
--dry-runest fondamental. Dans mon archi, chaque décision d'arbitrage génère un plan qui doit être approuvé par un contrôleur avant exécution.Il faut isoler le moteur. Voici comment je sécurise mes accès API dans mes scripts de déploiement :
Et côté sécurité ? Si ton moteur d'IA a les droits pour modifier ton infrastructure via ton pipeline CI/CD, c'est une faille de sécurité majeure. Si le moteur est compromis, c'est tout ton cloud qui est ouvert à la création de mineurs de crypto.
Si vous avez 3 nodes, oui, restez sur du basique. Mais pour des flottes de plusieurs milliers de pods, le FinOps manuel atteint ses limites. L'automatisation devient une question de survie financière.
Totalement d'accord. On cherche à résoudre des problèmes de riche avec des solutions de chercheurs. La plupart des boîtes ont juste besoin d'un bon
kubectl top nodeset de supprimer les ressources inutilisées.Je reste sceptique sur le coût de maintenance d'une telle usine à gaz. Combien de jours/homme pour configurer ce moteur par rapport aux économies réelles ? Parfois, une simple
Reserved Instancesur 3 ans coûte moins cher que de payer des ingénieurs pour maintenir cette complexité.C'est là que l'observabilité entre en jeu. Si les métriques remontent une latence supérieure à 50ms, la règle est violée et le moteur doit annuler la migration. C'est une boucle de rétroaction, pas juste un script.
Le problème c'est que l'IA va toujours privilégier le coût. Si elle choisit une région avec une latence réseau pourrie juste parce que c'est moins cher, ton user final va voir la différence. Le
maxLatencyMsdans votre config, c'est bien, mais en pratique ça fluctue trop.Vous parlez de Kubernetes, mais quid des services managés ? Si ton app dépend d'un SQS ou d'un Cloud Pub/Sub, tu es bloqué chez le fournisseur. Ton schéma d'arbitrage tombe à l'eau dès que tu as une dépendance forte.
Le risque est réel. C'est pour ça que la politique d'arbitrage est déclarative. On valide les changements via une
Pull Requestsur le repo GitOps. C'est l'humain qui garde le dernier mot sur lesconstraints.Exactement. J'ai déjà vu des outils d'auto-scaling interne tuer des instances en pleine charge parce que le seuil était mal réglé. Mettre une IA là-dessus me fait peur.
Le YAML de configuration
arbitrage-policy-production.yamlest mignon, mais comment on gère les mises à jour de règles en live ? Si l'IA fait une boucle de décision foireuse, on se retrouve avec des instabilités permanentes.C'est exactement pour ça que je précise : commencez par du
stateless. Personne ne vous demande de migrer vos bases de données transactionnelles dès le premier jour. Le but est de laisser l'IA gérer les workers éphémères sur du spot.D'accord avec 1. Le titre est vendeur mais en pratique, gérer du multi-cloud avec une IA qui décide toute seule de migrer des workloads, c'est le chaos assuré en cas de bug. Qui debug le moteur d'IA quand le cluster tombe en 404 ?
Encore un article qui vend du rêve. Déplacer 50 pods entre AWS et GCP juste pour gagner 3 centimes sur l'heure, c'est oublier le coût de transfert des données. Vous avez calculé le temps de latence réseau pour synchroniser les volumes persistants entre deux régions ? C'est le meilleur moyen de se manger des egress fees monstrueux.