Progressive Delivery : L'Ère des Déploiements Dynamiques et Sûrs
Vous souvenez-vous de cette angoisse qui précède une mise en production ? Cette tension palpable où toute l'équipe retient son souffle en espérant que le "gros bouton rouge" ne déclenchera pas une cascade de défaillances. Et si cette époque était révolue ? Si nous pouvions transformer le déploiement d'un événement stressant en un non-événement, un simple flux continu et maîtrisé ?
C'est précisément la promesse du Progressive Delivery. Ce n'est pas simplement une nouvelle version du CI/CD, mais une véritable évolution philosophique qui place la sécurité et la maîtrise du risque au cœur de la livraison logicielle. L'idée n'est plus de "pousser" une version en production, mais de la "dévoiler" progressivement à des segments d'utilisateurs de plus en plus larges.
Cette approche nous permet de collecter des données, de valider le comportement de notre code en conditions réelles et, si nécessaire, de faire marche arrière instantanément sans impacter la totalité de notre base utilisateur. C'est l'art de déployer avec confiance, en s'appuyant sur la donnée plutôt que sur l'espoir.
La Mécanique du Déploiement Maîtrisé
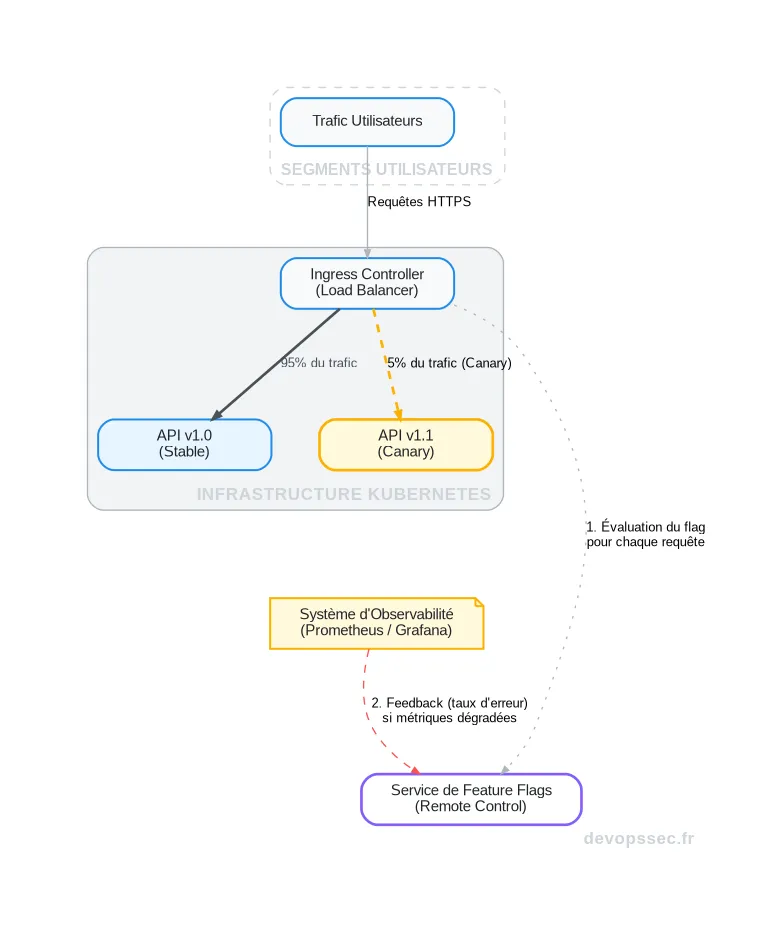
Le Progressive Delivery n'est pas une technologie unique, mais un ensemble de pratiques et d'outils orchestrés pour réduire l'impact potentiel de chaque changement. Il s'agit de découpler le déploiement (la mise en place du code sur les serveurs) de la publication (l'activation de la fonctionnalité pour les utilisateurs).
Les Stratégies au Cœur du Système
Pour atteindre ce niveau de granularité, nous nous appuyons sur plusieurs stratégies de déploiement bien connues, mais que nous élevons à un autre niveau grâce à l'automatisation et à l'analyse de données en temps réel.
| Stratégie | Principe de Fonctionnement | Cas d'usage Idéal |
|---|---|---|
| Blue/Green Deployment | Maintien de deux environnements de production identiques. Le trafic est basculé d'un seul coup de l'ancien (Blue) vers le nouveau (Green) après validation. | Déploiements d'infrastructure critiques ou changements non rétrocompatibles. |
| Déploiement Canary (Canary Release) | La nouvelle version est exposée à un petit sous-ensemble d'utilisateurs (les "canaris"). Si les métriques sont bonnes, le trafic est progressivement augmenté. | Validation de la performance et de la stabilité d'une nouvelle fonctionnalité majeure avec un risque minimal. |
| A/B Testing | Déploiement simultané de plusieurs versions d'une même fonctionnalité à des segments d'utilisateurs distincts pour comparer leur performance par rapport à un objectif métier. | Optimisation de l'expérience utilisateur, validation d'hypothèses produit (ex: couleur d'un bouton, parcours d'achat). |
L'Observabilité : Vos Yeux en Production
Déployer progressivement sans voir ce qu'il se passe serait comme piloter un avion les yeux bandés. L'Observabilité est le pilier qui rend tout cela possible. Elle va bien au-delà du simple monitoring en nous donnant la capacité de poser des questions sur l'état de notre système sans avoir à prédéfinir toutes les pannes possibles.
Concrètement, elle repose sur la corrélation de trois types de signaux :
- Les Métriques (Metrics) : Des indicateurs numériques sur la santé du système (ex: temps de réponse, taux d'erreur, utilisation CPU).
- Les Traces (Traces) : La visualisation du parcours complet d'une requête à travers les différents microservices de votre architecture.
- Les Journaux (Logs) : Des enregistrements textuels d'événements spécifiques qui se sont produits à un instant T.
C'est en analysant ces signaux en temps réel qu'un système de déploiement Canary peut décider automatiquement d'augmenter le trafic ou, au contraire, d'initier un rollback en cas de dégradation des performances.
Les Feature Flags : La Clé de Voûte du Système
Imaginez pouvoir activer ou désactiver une fonctionnalité en production d'un simple clic, sans redéployer le moindre octet de code. C'est le super-pouvoir que nous offrent les Feature Flags (ou feature toggles), véritables interrupteurs logiciels qui conditionnent l'exécution de portions de notre code.
Un feature flag est, dans sa forme la plus simple, une structure conditionnelle (un `if/else`) dont la décision est contrôlée à distance par un service de configuration. Cela nous permet de déployer du code "inactif" ou "sombre" en production, en toute sécurité.
Un exemple de configuration simple
Voici à quoi pourrait ressembler la configuration d'un flag dans un fichier YAML pour un service comme LaunchDarkly ou Flagsmith. Ce flag simple active une nouvelle page de paiement pour 10% des utilisateurs basés en France.
new-payment-flow:
description: "Active le nouveau tunnel de paiement avec Stripe V2."
enabled: true
rules:
- key: countryTargeting
# On cible uniquement les utilisateurs en France
clauses:
- attribute: country
op: in
values: ["FR"]
# On active pour 10% du segment ciblé
percentage: 10
# Valeur par défaut si aucune règle ne correspond
defaultValue: falseLa puissance de cette approche est qu'elle sépare la décision technique (déployer le code) de la décision métier (rendre la fonctionnalité accessible). Le Product Manager peut ainsi contrôler le rythme de la sortie d'une fonctionnalité directement depuis une interface dédiée.
Les Limites et la Dette Technique Associée
Malgré leur incroyable flexibilité, les feature flags ne sont pas une solution miracle et introduisent leur propre lot de complexité. Le risque le plus courant est l'accumulation de "dette de flags" : des interrupteurs qui restent dans le code bien après que la fonctionnalité associée soit devenue stable et déployée à 100%.
Ce code mort complexifie la maintenance, augmente la surface de test et peut même introduire des comportements inattendus si un vieux flag est réactivé par erreur. La gestion du cycle de vie des flags est donc une discipline essentielle.
Cycle de Vie d'un Feature Flag
Chaque feature flag devrait avoir un "propriétaire" et une "date d'expiration". Intégrez dans votre processus une revue régulière pour archiver ou supprimer les flags qui ont servi leur but. Des outils peuvent même scanner votre code pour détecter les flags obsolètes.
Conclusion : Déployer Moins pour Livrer Plus
En définitive, le Progressive Delivery change notre rapport au risque. Plutôt que de chercher à l'éliminer via des cycles de validation interminables avant la production, il nous apprend à le gérer et à le maîtriser directement en production, dans un environnement contrôlé.
Adopter cette culture, c'est accepter que le véritable test se passe face aux utilisateurs. C'est transformer chaque déploiement en une opportunité d'apprendre, d'itérer et de livrer de la valeur métier plus rapidement et plus sereinement que jamais. L'objectif n'est plus la perfection, mais l'amélioration continue, sécurisée par des filets de sécurité robustes et intelligents.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
24 commentaires
C'est exactement ça. Plus besoin de stresser, tu laisses le contrôleur gérer la montée en charge. Si les
Metricssont rouges, il rollback tout seul en moins d'une seconde.J'ai testé
Argo Rolloutset c'est vraiment puissant pour éviter le "gros bouton rouge" dont tu parles.Si tu arrêtes de passer 3 jours à préparer un release, oui, ça booste la vélocité. Tu déploies dès que c'est prêt, c'est tout.
Le Progressive Delivery, ça booste vraiment la vélocité ou c'est juste du buzzword ?
Audit log obligatoire. Si ton outil de flag n'a pas d'API pour exporter les logs d'audit vers ton SIEM, tu es aveugle.
Comment tu gères le logging des changements de flags ?
Si un mec change un flag en prod, je veux savoir qui et quand.
Un flag qui active une fonctionnalité lourde en base de données pour 100% des utilisateurs d'un coup. Résultat : base de données au tapis en 30 secondes.
Toujours faire du
percentagerollout progressif.C'est quoi la pire erreur que tu as vue avec les flags ?
Sur le stateful, oublie le Blue/Green classique. Canary avec traffic shifting via un Service Mesh genre Istio est bien plus propre.
Sympa le tableau sur les stratégies. Le Blue/Green c'est bien, mais sur du stateful, c'est souvent la galère.
Regarde
UnleashouFlagsmith. C'est du solide, tu peux les auto-héberger sur ton cluster Kubernetes facilement.Quelqu'un a testé des outils open source pour les flags ? LaunchDarkly c'est hors de prix pour les petites boîtes.
Utilise un SDK qui fait du local evaluation. Le flag est récupéré au démarrage ou via un stream push, la décision est prise en mémoire sur le serveur.
Pas de requête réseau à chaque appel de fonction.
Vous gérez comment les flags pour les clients VIP ?
J'ai peur que la logique de ciblage finisse par alourdir les perfs du service de config.
C'est clair. Le test en prod est obligatoire, mais ça ne remplace pas une pipeline CI solide.
Le but c'est de réduire le blast radius quand ça pète, pas de supprimer les bugs.
La séparation entre déploiement et release, c'est le vrai changement de paradigme.
Ça demande une rigueur folle sur les tests d'intégration, sinon tu déploies du code "sombre" qui casse tout au moment de l'activation.
Argo Rollouts est fait pour ça. Tu définis ton
AnalysisTemplateet si le taux d'erreur 5xx dépasse un seuil, il fait le rollback tout seul.Le déploiement Canary c'est cool, mais comment tu automatises le rollback si les métriques déconnent ?
Vous faites ça avec
ArgoCD?Tempo est plus simple à scaler pour du gros volume de traces. Combiné avec
Lokipour les logs, t'as une corrélation parfaite.Pour l'observabilité, vous utilisez quoi comme stack ?
Prometheus + Grafana c'est le standard, mais pour les traces, vous préférez Jaeger ou Tempo ?
Exact. C'est la fameuse "dette de flags".
La solution c'est d'intégrer un linter ou des tests unitaires qui échouent si un flag est présent depuis plus de X jours. Faut automatiser le nettoyage sinon c'est ingérable.
D'accord avec l'auteur. Par contre, les Feature Flags ça devient vite un cimetière de conditions
if/elsedans le code.Vous avez des outils pour monitorer ça ?
C'est le point critique. La règle d'or : tes changements de schéma doivent être rétrocompatibles.
Tu fais tes migrations en deux temps : d'abord l'ajout de colonnes ou tables, jamais de suppression destructive avant que l'ancienne version soit totalement éteinte.
Le concept de Progressive Delivery est sympa sur le papier, mais en pratique, gérer les rolling updates avec des dépendances de base de données, c'est l'enfer.
Comment tu gères le schéma DB si tu as deux versions de code qui tournent en même temps ?