Introduction à eBPF et à la sécurité en production
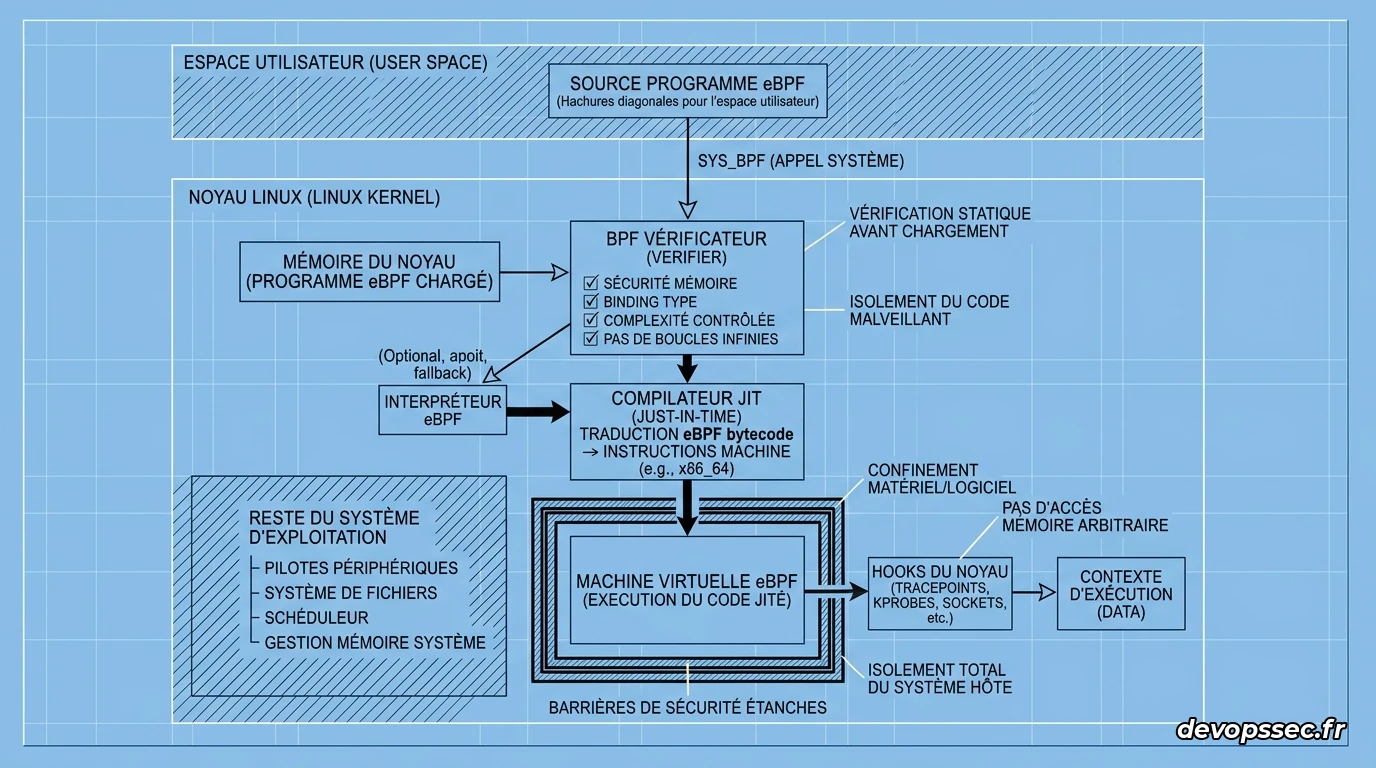
Le crash d'un serveur de production à trois heures du matin à cause d'un module noyau défectueux est le pire cauchemar de tout ingénieur système. Heureusement, la technologie Extended Berkeley Packet Filter (eBPF) a révolutionné la manière dont nous observons et sécurisons nos infrastructures en permettant d'exécuter du code directement dans le noyau Linux sans jamais risquer de faire planter la machine. Contrairement aux modules noyau traditionnels qui s'exécutent sans filet de sécurité, eBPF utilise une machine virtuelle interne dotée d'un validateur ultra-strict qui garantit que votre code ne causera jamais de fuite de mémoire ou de blocage système.
Pour exploiter cette technologie sur des parcs de serveurs hétérogènes sans avoir à recompiler vos programmes pour chaque version de noyau, nous utilisons le concept de Compile Once – Run Everywhere (CO-RE). Cette approche repose sur les métadonnées du BPF Type Format (BTF) fournies par les distributions modernes, permettant d'ajuster dynamiquement à la volée les décalages de structures de données du noyau lors du chargement du programme. Nous allons voir comment installer l'environnement nécessaire et écrire nos premiers outils d'observation robustes, prêts à affronter des charges de production réelles.
Pour démarrer sur une distribution Debian ou Ubuntu moderne, vous devez installer les en-têtes du noyau, la bibliothèque de développement de libbpf, ainsi que la suite d'outils de compilation LLVM et Clang. Ces outils permettent de traduire notre code source C en instructions bytecode eBPF compréhensibles par le noyau. Lancez la commande suivante dans votre terminal pour préparer votre machine de développement :
sudo apt update && sudo apt install -y clang llvm libelf-dev libbpf-dev bpfcc-tools linux-headers-$(uname -r) pkg-config build-essentialRésultat:
Reading package lists... Done
Building dependency tree... Done
linux-headers-generic is already the newest version.
libbpf-dev is newly installed with success.
Clang compiler and LLVM tools are ready for compilation.Mise en place de l'environnement et premier probe sécurisé
Le premier pas : Un Kprobe minimaliste mais robuste
Les kprobes, ou sondes de noyau, permettent de s'attacher à presque n'importe quel point d'entrée de fonction à l'intérieur du noyau Linux. Notre premier exercice consiste à intercepter la création de processus via l'appel système de clonage, tout en veillant à ne pas surcharger le CPU avec des opérations de journalisation trop lourdes. Créez un fichier nommé kprobe_clone.bpf.c et insérez-y le code de production suivant :
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
char LICENSE[] SEC("license") = "GPL";
SEC("kprobe/sys_clone")
int BPF_KPROBE(kprobe_sys_clone) {
u64 id = bpf_get_current_pid_tgid();
u32 tgid = id >> 32;
u32 pid = id;
if (tgid == 0) {
return 0;
}
bpf_printk("Appel clone detecte - TGID: %d, PID: %d\n", tgid, pid);
return 0;
}Examinons en détail la structure de ce code pour comprendre comment il garantit la sécurité et l'efficacité de l'exécution. La structure LICENSE déclarée sous la section SEC("license") est obligatoire pour que le noyau autorise l'accès aux fonctions d'aide critiques restreintes sous licence GPL. La macro BPF_KPROBE enveloppe proprement l'accès aux registres du processeur, masquant la complexité de l'architecture matérielle sous-jacente.
La ligne de filtrage if (tgid == 0) est une garde essentielle pour éviter de traiter les threads du noyau ou les processus inactifs, limitant ainsi l'overhead de traitement. Enfin, nous extrayons le PID et le TGID à partir d'un entier de 64 bits retourné par bpf_get_current_pid_tgid() en appliquant un décalage binaire vers la droite, une opération extrêmement rapide et sans allocation de mémoire.
Compilation et validation du bytecode
Pour transformer ce fichier source en un fichier objet exécutable par la machine virtuelle du noyau, nous devons cibler l'architecture de processeur virtuelle BPF. Utilisez la commande suivante pour exécuter la compilation avec un niveau d'optimisation élevé, indispensable pour que le validateur puisse simplifier le graphe d'exécution de notre code :
clang -g -O2 -target bpf -D__TARGET_ARCH_x86 -I/usr/include/x86_64-linux-gnu -c kprobe_clone.bpf.c -o kprobe_clone.bpf.oUne fois le fichier objet kprobe_clone.bpf.o généré, vous pouvez utiliser l'utilitaire bpftool pour inspecter la structure interne du fichier et vous assurer que les symboles BTF ont été correctement embarqués. Cette étape de vérification est cruciale avant d'essayer de charger un programme sur des environnements de staging ou de production.
L'art du fentry et fexit pour des performances optimales
Pourquoi fentry écrase les kprobes traditionnels
Bien que les kprobes soient très populaires, ils souffrent d'un inconvénient majeur en production : leur coût en performances lors des transitions de contexte. Les sondes de type fentry/fexit (Function Entry/Exit) résolvent ce problème en s'intégrant directement au mécanisme de traçage de fonction natif du noyau, appelé ftrace. En éliminant le besoin de remplacer dynamiquement les instructions machine par des interruptions matérielles de type point d'arrêt, les sondes fentry réduisent l'impact sur la latence du système de près de 80% par rapport à un kprobe classique.
Pour illustrer ce flux d'exécution et comprendre comment les programmes eBPF s'exécutent en toute sécurité sans jamais provoquer de crash, analysons le cycle de vie d'un programme eBPF de l'espace utilisateur jusqu'au cœur du noyau Linux :
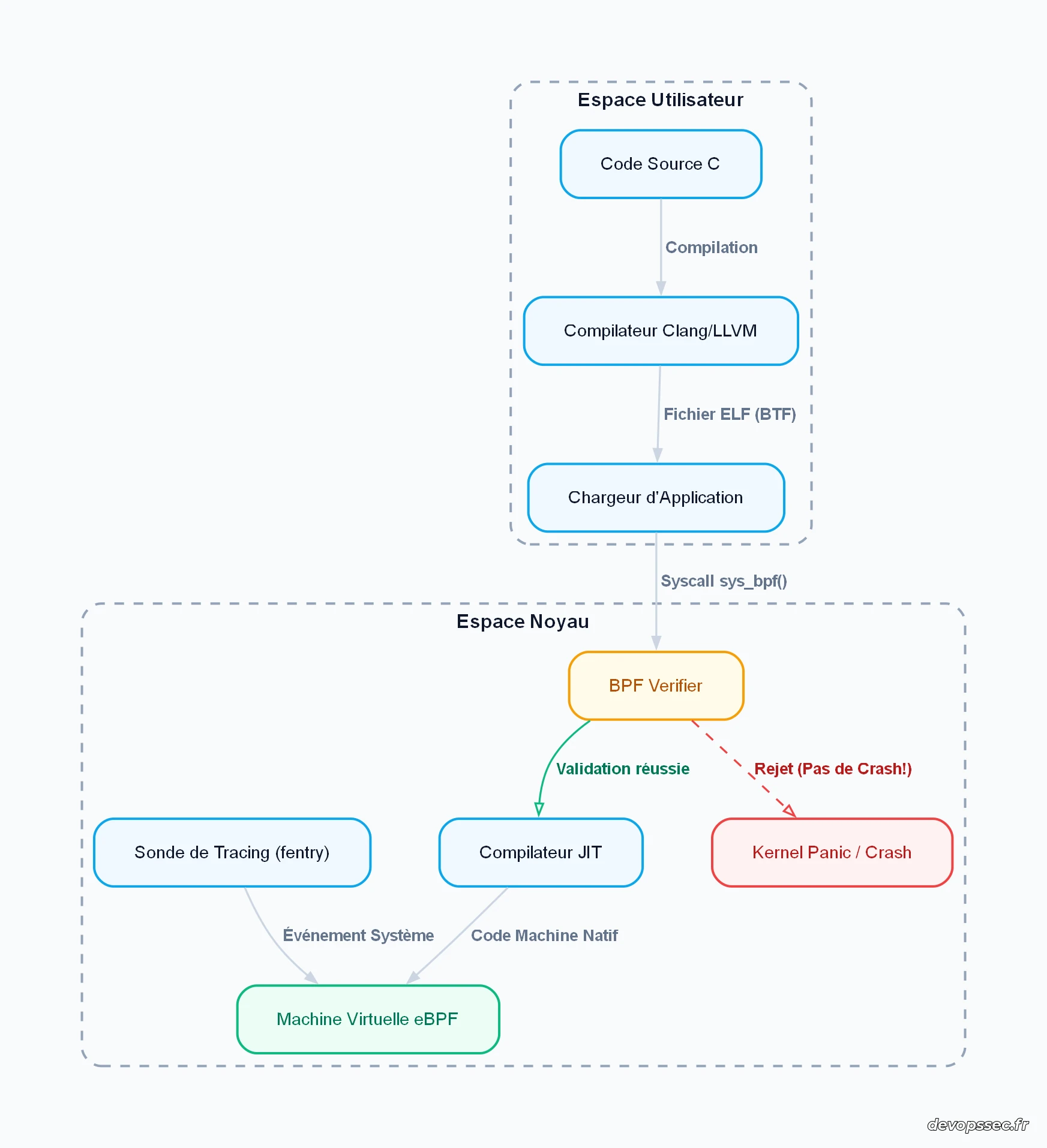
Ce schéma met en évidence le rôle central du BPF Verifier. Lorsqu'une application tente de charger un code eBPF dans le noyau via l'appel système sys_bpf(), le vérificateur analyse statiquement toutes les branches possibles du programme pour s'assurer qu'il ne contient aucune boucle infinie, qu'il ne tente pas d'accéder à des zones mémoire interdites et qu'il se termine toujours. Si le vérificateur détecte le moindre risque, le programme est immédiatement rejeté au lieu de provoquer un plantage complet du système, protégeant ainsi activement vos serveurs de production contre les erreurs de programmation.
Implémentation d'un tracing fentry de production
Mettons maintenant en œuvre un programme exploitant les performances de fentry pour monitorer de manière ultra-rapide les exécutions de commandes sur nos serveurs. Nous allons intercepter la fonction système __x64_sys_execve de façon sécurisée en lisant les arguments transmis à l'appel système depuis l'espace utilisateur sans risquer de violation d'accès mémoire.
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
struct event_t {
u32 pid;
char comm[16];
char filename[128];
};
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} events SEC(".maps");
SEC("fentry/__x64_sys_execve")
int BPF_PROG(trace_execve, struct pt_regs *regs, const char *filename, const char *const argv[], const char *const envp[]) {
struct event_t ev = {0};
ev.pid = bpf_get_current_pid_tgid() >> 32;
bpf_get_current_comm(&ev.comm, sizeof(ev.comm));
long res = bpf_probe_read_user_str(&ev.filename, sizeof(ev.filename), filename);
if (res < 0) {
bpf_printk("Echec de lecture securisee du chemin d'acces: %ld\n", res);
return 0;
}
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &ev, sizeof(ev));
return 0;
}Dans cette structure, nous déclarons une map de type BPF_MAP_TYPE_PERF_EVENT_ARRAY appelée events. Cette structure de données de production sert de file d'attente circulaire asynchrone pour envoyer des événements de manière non bloquante vers l'espace utilisateur. Cela évite d'utiliser la fonction bpf_printk qui écrit dans un fichier de trace global lent et partagé par tout le système.
La fonction bpf_probe_read_user_str est l'un des piliers de la stabilité du système : elle copie en toute sécurité la chaîne de caractères située dans l'espace mémoire utilisateur (le nom du binaire exécuté) vers la mémoire sécurisée du noyau réservée à notre programme eBPF. Si le pointeur filename est invalide ou corrompu, la fonction renvoie une erreur négative que nous interceptons proprement pour interrompre le traitement sans causer de défaut de page dans le noyau.
Éviter le Kernel Panic : Gestion des ressources et limites du vérificateur
Dompter le BPF Verifier
Le validateur eBPF est impitoyable, et de nombreux développeurs juniors se heurtent à ses restrictions dès qu'ils tentent d'écrire des algorithmes un peu complexes. Pour assurer la stabilité de production, le validateur rejette systématiquement tout programme qui dépasse une complexité de 1 million d'instructions vérifiées ou qui possède des chemins d'exécution dont la terminaison n'est pas garantie à 100%. Cela signifie que toutes vos boucles de traitement doivent utiliser des bornes d'itération constantes connues dès la compilation.
Astuce de Performance
Ne tentez jamais de parcourir de grands tableaux dynamiques en eBPF. Si vous devez analyser des listes d'éléments, utilisez des directives de préprocesseur pour limiter strictement le nombre d'itérations, ou déléguez le filtrage lourd à votre application dans l'espace utilisateur.
Un autre piège fréquent concerne l'accès aux pointeurs imbriqués. Lorsque vous lisez des champs complexes de structures réseau ou d'informations de processus, vous devez explicitement vérifier chaque pointeur intermédiaire contre la valeur nulle avant de le déréférencer, ou utiliser des macros d'accès sécurisé fournies par bpf_core_read.h telles que BPF_CORE_READ(). Sans cela, le validateur arrêtera net le chargement de votre programme avec une erreur explicite.
Gestion des maps de production et comparaison des techniques
Pour assurer la pérennité de votre infrastructure de tracing en production, le choix de la technologie de capture doit être mûrement réfléchi. Le tableau ci-dessous compare les deux approches étudiées afin de vous guider dans vos décisions architecturales selon vos contraintes système :
| Caractéristique | Kprobes (Kernel Probes) | Fentry (Function Entry) |
|---|---|---|
| Compatibilité noyau | Excellente (disponible sur presque tous les vieux noyaux) | Noyaux récents (> 5.5) avec support BTF actif |
| Impact sur les performances | Moyen (overhead dû aux interruptions matérielles) | Extrêmement faible (liaison directe via ftrace) |
| Stabilité et sécurité | Élevée (vérifié par eBPF) | Maximale (vérification des types d'arguments à la compilation) |
| Facilité de maintenance | Complexe (sensible aux changements internes du noyau) | Simple (repose sur le dictionnaire BTF standardisé) |
Pour éviter les fuites de mémoire et la saturation de vos tables d'événements, configurez toujours des limites de taille maximales restrictives sur vos maps eBPF. Une map de type table de hachage qui déborde refusera tout simplement l'enregistrement de nouvelles entrées, protégeant ainsi la mémoire physique globale de votre système contre tout risque de déni de service interne provoqué par un trafic applicatif anormal.
Maîtriser eBPF sans frissonner le vendredi soir
Intégrer eBPF dans votre arsenal de debugging en production vous offre une visibilité inégalée sans compromettre la stabilité de vos plateformes. En combinant l'utilisation systématique de CO-RE pour la portabilité et les sondes de type fentry pour préserver vos ressources CPU, vous pouvez désormais concevoir des outils de monitoring sur mesure capables de répondre instantanément aux pannes les plus complexes. N'oubliez jamais d'analyser vos codes à l'aide de bpftool et de respecter scrupuleusement les exigences du validateur eBPF pour garantir des déploiements sans aucun risque.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
28 commentaires
Super article, mais je bloque sur l'installation des dépendances. La commande
apt installme sort une erreur sur le paquetlibbpf-dev, il dit qu'il est introuvable sur ma Debian 10.J'essaie de compiler le
kprobe_clone.bpf.cmais Clang me renvoie une erreur de typevmlinux.h not found. Où est censé se trouver ce fichier ?Tu dois générer le
vmlinux.htoi-même à partir de ton kernel actuel. Utilisebpftoolpour extraire les types :J'ai implémenté le
fentrypour__x64_sys_execve, ça tourne bien mais je sature ma mapeventsen quelques secondes sur un serveur à forte charge. Comment limiter proprement ?Il faut définir une taille fixe pour ta map dans le code C. Ne laisse pas la valeur par défaut. Utilise
__uint(max_entries, 10240);dans la déclaration de ta mapevents.Quelqu'un a déjà testé ça sur un noyau 4.19 ? L'article dit que
fentrydemande 5.5+, c'est bloquant pour mon infra legacy.Sur 4.19, oublie
fentry. Reste sur leskprobesclassiques. C'est moins performant mais c'est la seule option viable sur les vieux noyaux sans support BTF natif.Merci pour le tuto ! Par contre, j'ai une erreur
invalid mem accesslors de l'accès àfilenamedanstrace_execve. Une idée ?C'est probablement parce que tu n'utilises pas
bpf_probe_read_user_str. Tu ne peux pas déréférencer directement un pointeur venant de l'user space. Montre ton code si ça persiste.Est-ce que je peux utiliser
bpf_printkpour débugger en prod ? Ou c'est risqué ?À ne jamais faire en prod.
bpf_printkest très lent car il écrit dans un fichier global. Utilise lesperf_event_arraycomme montré dans l'article pour remonter tes données proprement.Le validateur eBPF me rejette mon programme à cause de la taille du stack. J'ai déclaré un buffer de 512 octets, c'est trop ?
La limite est de 512 octets pour tout le stack eBPF. Si tu as déjà des variables locales, tu dépasses. Réduis ton buffer ou utilise une
BPF_MAP_TYPE_PERCPU_ARRAYpour stocker tes données temporaires.J'ai une erreur
BPF_PROG_LOAD: Argument list too long. C'est lié à quoi ?C'est que ton programme est trop complexe pour le vérificateur. Il dépasse le million d'instructions. Simplifie tes boucles ou segmente ton code en plusieurs programmes
tail_call.Est-ce que je peux utiliser
BPF_CORE_READsur des structures qui ne sont pas dansvmlinux.h?Non,
BPF_CORE_READrepose sur les informations BTF du noyau. Si la structure n'est pas connue du BTF, ça ne fonctionnera pas.Le schéma du cycle de vie est top. Ça aide à comprendre pourquoi on ne risque pas de Kernel Panic.
Exactement. Le validateur est là pour ça. Si le code est foireux, le noyau refuse le chargement et c'est tout. Zéro risque de crash.
Quel compilateur tu conseilles ? Clang 10 suffit ?
Clang 10 est vieillissant. Utilise au moins Clang 14 ou 15 pour avoir un support correct des features BPF modernes comme les
CO-RE.Comment je peux monitorer l'usage CPU de mon programme eBPF lui-même ?
Utilise
bpftool prog show. Il te donnera le temps d'exécution total et le nombre d'appels pour chaque programme chargé.Merci pour le guide, ça m'a sauvé un debugging de 3 jours sur un problème d'execve introuvable.
Content que ça t'ait débloqué. eBPF est puissant mais la courbe d'apprentissage est raide. Bonne continuation.