Comprendre l'enfer du thrashing mémoire et l'environnement de contrôle

Le piège mortel de la swap incontrôlée
Le thrashing mémoire est comparable à un cuisinier qui n'aurait plus de place sur son plan de travail. Au lieu de cuisiner, il passe tout son temps à faire des allers-retours entre sa cuisine et la cave pour stocker et récupérer ses ingrédients. En production, ce phénomène détruit les performances de vos applications. La latence s'envole, le CPU s'asphyxie et le serveur ne répond plus du tout, tout en restant techniquement "actif" pour vos outils de monitoring traditionnels qui ne détectent pas de panne franche.
Pour éviter cette paralysie silencieuse, nous devons confier la surveillance de nos conteneurs et de nos services système à cgroup v2. Contrairement à la première version, cette réécriture moderne du noyau Linux introduit une gestion unifiée des ressources et intègre nativement le concept de Pressure Stall Information (PSI). Le PSI agit comme un indicateur d'effort qui remonte en temps réel le pourcentage de temps CPU perdu à attendre de la mémoire ou des entrées-sorties disque.
Pourquoi cgroup v2 change la donne
Le modèle cgroup v1 gérait les ressources dans des hiérarchies séparées, rendant impossible la corrélation entre l'utilisation du processeur, de la mémoire et des disques. La version v2 unifie cette structure, permettant enfin d'appliquer des règles d'éviction intelligentes basées sur la souffrance réelle du système plutôt que sur des seuils de consommation arbitraires.
Préparation de l'environnement sous cgroup v2
Avant de déployer nos politiques d'éviction, nous devons nous assurer que votre système d'exploitation utilise bien la hiérarchie unifiée cgroup v2 et que le PSI est activé au niveau du noyau. Les distributions d'entreprise récentes l'activent par défaut, mais une vérification rigoureuse s'impose.
Exécutez la commande suivante dans votre terminal de production pour confirmer la configuration actuelle de votre système :
grep -E "cgroup2|psi" /proc/filesystems /proc/cmdlineRésultat:
nodev cgroup2
BOOT_IMAGE=/vmlinuz-linux root=UUID=... rw psi=1Si la ligne contenant psi=1 n'apparaît pas ou si cgroup2 n'est pas répertorié, vous devez modifier les paramètres d'amorçage de votre noyau. Ouvrez le fichier de configuration du chargeur de démarrage /etc/default/grub et ajoutez les paramètres requis à la ligne des arguments par défaut.
# Modification des paramètres du chargeur de démarrage
sudo sed -i 's/GRUB_CMDLINE_LINUX_DEFAULT="/GRUB_CMDLINE_LINUX_DEFAULT="systemd.unified_cgroup_hierarchy=1 psi=1 /' /etc/default/grub
sudo update-grubLe paramètre systemd.unified_cgroup_hierarchy=1 force l'activation de la hiérarchie unique de cgroup v2, tandis que psi=1 ordonne au noyau de calculer les statistiques de blocage pour le processeur, la mémoire et les entrées-sorties. Un redémarrage de la machine est indispensable pour appliquer ces modifications de bas niveau.
Configuration initiale et validation des limites système
Implémentation de base avec systemd-run
Pour comprendre comment le noyau réagit lorsque les limites physiques sont atteintes, nous allons exécuter un processus isolé au sein d'un cgroup temporaire managé par systemd. Cette approche évite d'écrire manuellement dans les dossiers virtuels de /sys/fs/cgroup, une pratique risquée en production.
Nous allons lancer une commande qui consomme volontairement de la mémoire tout en lui imposant une limite stricte de 500 Mo. Si le processus tente de dépasser cette valeur, le noyau refusera de lui allouer des pages physiques supplémentaires.
systemd-run --user --scope -p MemoryMax=500M -p MemorySwapMax=0M --unit=test-limite-ram tail /dev/zeroExaminons de près les paramètres appliqués à cette commande pour en comprendre la portée :
- --scope : Exécute le processus de manière synchrone dans la session actuelle de l'utilisateur tout en l'associant à un cgroup dédié.
- MemoryMax=500M : Définit la limite absolue de mémoire physique de travail. Au-delà, l'allocation échoue immédiatement.
- MemorySwapMax=0M : Désactive complètement l'utilisation du swap pour ce cgroup. C'est l'instruction clé pour empêcher le thrashing.
- --unit=test-limite-ram : Assigne un nom explicite au service pour faciliter son suivi et sa gestion par le gestionnaire d'initialisation.
Vérifions maintenant la création effective du groupe de contrôle et l'application des restrictions en lisant directement les fichiers d'état gérés par le système d'exploitation :
cat /sys/fs/cgroup/user.slice/user-$(id -u).slice/user@$(id -u).service/app.slice/test-limite-ram.scope/memory.maxRésultat:
524288000La valeur retournée correspond exactement à la limite de 500 Mo convertie en octets. Le noyau Linux appliquera désormais une surveillance matérielle stricte sur ce groupe de processus, interdisant tout débordement mémoire et éliminant tout recours au stockage sur disque.
Architecture résiliente et éviction mémoire de production
Configuration avancée de systemd-oomd pour la production
Le tueur de processus par défaut du noyau, le fameux OOM Killer (Out Of Memory Killer), intervient souvent trop tard. Lorsque la mémoire physique est totalement épuisée, il choisit sa cible de manière brutale, tuant parfois votre base de données principale ou votre serveur web. Pour remédier à cela, nous allons configurer systemd-oomd, un démon moderne qui utilise les métriques PSI de cgroup v2 pour tuer les services en souffrance bien avant que le noyau ne panique.
Nous allons créer une configuration de production pour nos applications en définissant une tranche de ressources (slice) personnalisée qui protégera les services critiques tout en sacrifiant les tâches secondaires sous forte pression.
Créez le fichier de configuration de la tranche d'application à l'emplacement /etc/systemd/system/production-apps.slice :
[Unit]
Description=Tranche de production pour applications conteneurisees
Before=slices.target
[Slice]
# Activation de la comptabilite des ressources
MemoryAccounting=yes
CPUAccounting=yes
# Seuils de regulation memoire
MemoryHigh=3.5G
MemoryMax=4G
MemorySwapMax=500M
# Configuration de systemd-oomd
ManagedOOMMemoryPressure=kill
ManagedOOMMemoryPressureLimit=80%
ManagedOOMSwap=killDécortiquons chaque directive technique pour en assimiler le comportement opérationnel :
- MemoryHigh : Seuil de sécurité à partir duquel le noyau commence à ralentir activement les allocations de mémoire du processus et à récupérer agressivement du cache disque.
- MemoryMax : Limite physique absolue. Si le service l'atteint, l'allocation est stoppée et le processus peut être éliminé.
- ManagedOOMMemoryPressure=kill : Autorise systemd-oomd à surveiller cette tranche et à tuer les cgroups enfants si la pression sur la mémoire devient insupportable.
- ManagedOOMMemoryPressureLimit=80% : Seuil de déclenchement. Si les processus perdent plus de 80% de leur temps d'exécution à cause d'attentes d'allocation mémoire pendant plus de 20 secondes, l'éviction s'active.
- ManagedOOMSwap=kill : Ordonne la destruction immédiate des processus de cette tranche si l'utilisation globale de la swap du système dépasse 90% et que cette tranche y contribue fortement.
Analyse des flux d'éviction mémoire
Le diagramme ci-dessous illustre le mécanisme de décision et d'escalade des ressources lorsque la mémoire physique d'un serveur commence à saturer sous l'effet d'une charge applicative intense.
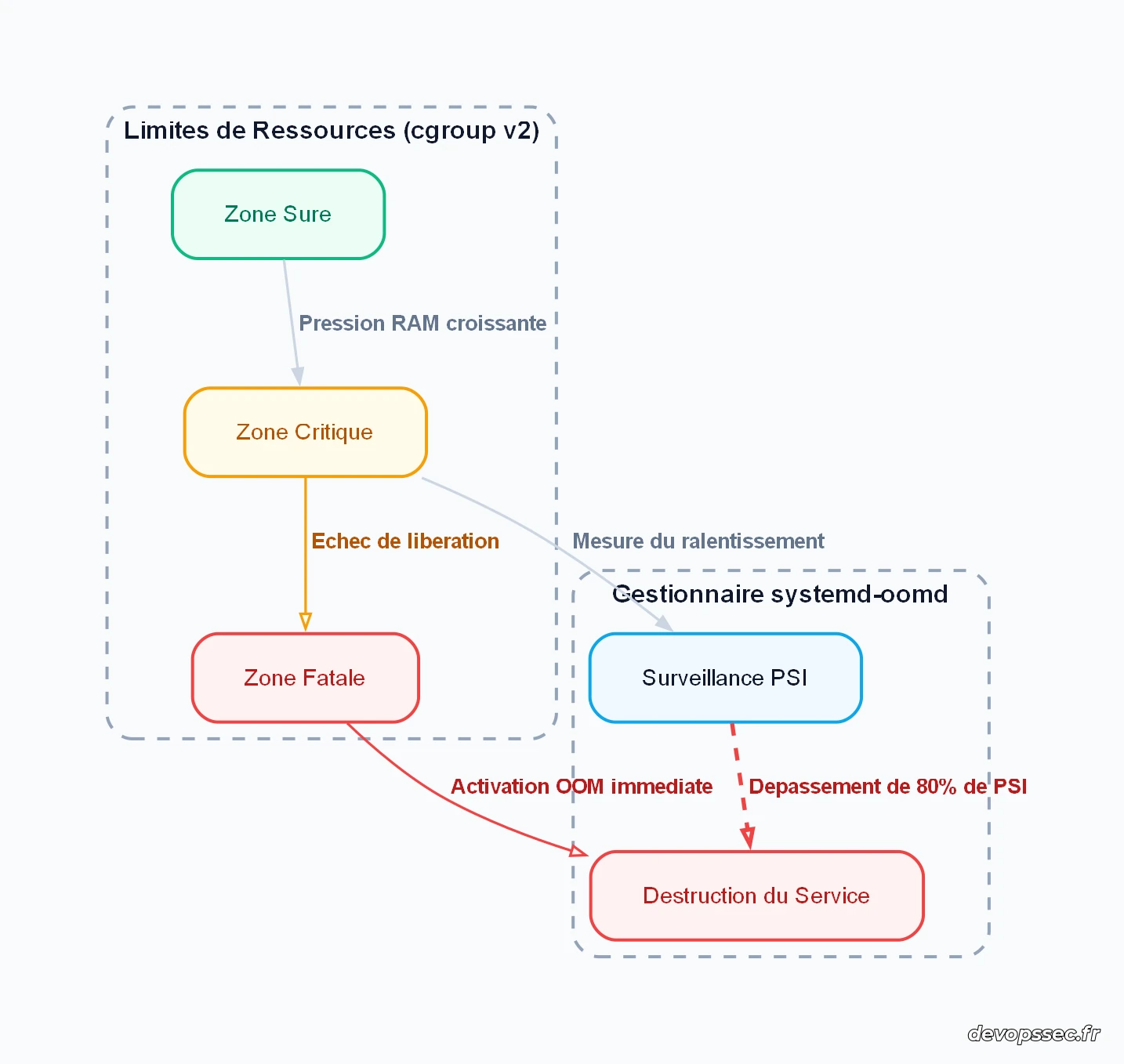
Le flux démontre que la surveillance basée sur le PSI (Pressure Stall Information) offre une zone tampon essentielle. Le service en souffrance est éliminé proprement dès que la perte d'efficacité dépasse le seuil tolérable de 80 %, évitant ainsi d'atteindre la zone fatale où le système d'exploitation complet perd sa réactivité.
Monitoring et validation des alertes d'éviction
Mettre en place des politiques d'éviction automatiques n'a de sens que si vous êtes immédiatement informé de leur exécution. Un serveur qui tue silencieusement ses propres conteneurs en boucle est une bombe à retardement pour votre infrastructure de production.
Simulation d'une tempête mémoire et lecture des logs de production
Pour valider notre configuration de production sans risquer de perturber d'autres services, nous allons forcer un dépassement de mémoire contrôlé. Nous utiliserons l'outil de test de charge stress-ng au sein d'un service système rattaché à notre tranche protectrice.
Déclarons un service éphémère et injectons-lui une charge mémoire supérieure à sa limite autorisée :
systemd-run --slice=production-apps.slice --unit=api-simule stress-ng --vm 1 --vm-bytes 5G --timeout 60sDès que la consommation de la tâche fictive dépasse les seuils définis, systemd-oomd intercepte l'anomalie grâce aux statistiques PSI et met fin à l'exécution du processus hors limites. Inspectons les journaux d'événements du système pour analyser la signature de cette éviction propre.
journalctl -u systemd-oomd.service --since "5 minutes ago" --no-pagerRésultat:
systemd-oomd[450]: Killed /production-apps.slice/api-simule.service due to memory pressure being 84.12% > 80.00% for 20s!
systemd-oomd[450]: Sent kill signal to 12945 (stress-ng-vm)
systemd[1]: api-simule.service: Main process exited, code=killed, status=9/KILL
systemd[1]: api-simule.service: Failed with result 'oom-kill'.L'analyse des journaux démontre que l'éviction s'est déroulée de manière chirurgicale. Contrairement à l'OOM Killer du noyau qui aurait pu cibler un service aléatoire, le démon systemd-oomd a identifié précisément l'unité api-simule.service au sein de la tranche supervisée. Le reste du système n'a subi aucun ralentissement, aucune écriture de swap intempestive, préservant ainsi la réactivité globale de votre serveur de production.
Maîtriser la mémoire pour garantir la haute disponibilité
Le contrôle de la mémoire sous Linux ne doit plus être un processus passif soumis aux réactions imprévisibles du noyau. En exploitant la puissance de cgroup v2 et les métriques de blocage temps réel de systemd-oomd, vous transformez vos serveurs d'une posture de survie réactive en une plateforme d'exécution prévisible et résiliente.
Appliquez ces configurations de tranches de ressources sur vos orchestrateurs et vos serveurs bare-metal pour isoler vos charges de travail critiques. Vous éliminerez ainsi définitivement le spectre des pannes de CPU causées par l'écriture frénétique sur le disque de swap, garantissant une expérience utilisateur fluide même sous des tempêtes de trafic imprévues.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
28 commentaires
J'ai testé le
psi=1maisgrepne renvoie rien sur mon vieux serveur Debian. Une idée ?Par défaut,
systemd-oomdsurveille la slice racine. Si ton conteneur n'est pas isolé, il peut être ciblé. Toujours isoler tes charges critiques dans une slice dédiée comme montré dans l'article.Super article. J'ai un doute sur le
systemd-oomd. Est-ce qu'il peut tuer un conteneur docker si je ne l'ai pas configuré dans une slice spécifique ?